做过站内搜索的朋友应该对Lucene.Net不陌生,没做过的也许会问:就不是个查询嘛!为什么不能使用Like模糊查找呢?
原因很简单--模糊查询的契合度太低,匹配关键字之间不能含有其他内容。最重要的是它会造成数据库全表扫描,效率底下,即使使用视图,也会造成数据库服务器"亚历山大",那LuceneNet又是一个神马东西?如何使用?以下给出详细的介绍包括Demo
Lucene简介
首先说明的是--Lucene.Net只是一个全文检索开发包,不是一个成型的搜索引擎,
它的功能就是负责将文本数据按照某种分词算法进行切词,分词后的结果存储在索引库中,从索引库检索数据的速度灰常快.
对以上加粗的词汇稍作下阐述:
文本数据:Lucene.Net只能对文本信息进行检索,所以非文本信息要么转换成为文本信息,要么你就死了这条心吧!
分词算法:将一句完整的话分解成若干词汇的算法 常见的一元分词(Lucene.Net内置就是一元分词,效率高,契合度低),二元分词,基于词库的分词算法(契合度高,效率低)...
切词:将一句完整的话,按分词算法切成若干词语
比如:"不是所有痞子都叫一毛" 这句话,如果根据一元分词算法则被切成: 不 是 所 有 痞 子 都 叫 一 毛
如果二元分词算法则切成: 不是 是所 所有 有痞 痞子 子都 都叫 叫一 一毛
如果基于词库的算法有可能:不是 所有 痞子 都叫 一毛 具体看词库
索引库:简单的理解成一个提供了全文检索功能的数据库
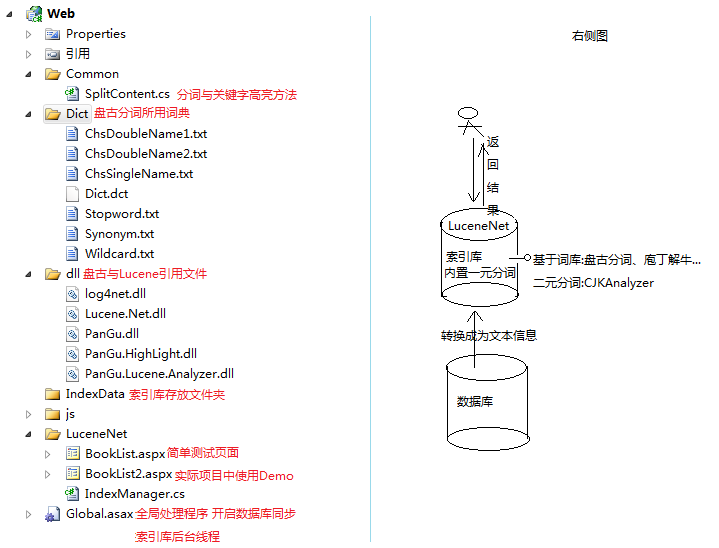
如果文字难以理解 见Demo文件说明中的右侧图吧
效果图
首先展示效果图,避免各位观众不知偶所云.
这里有三张图:
图1 简单使用页面效果图
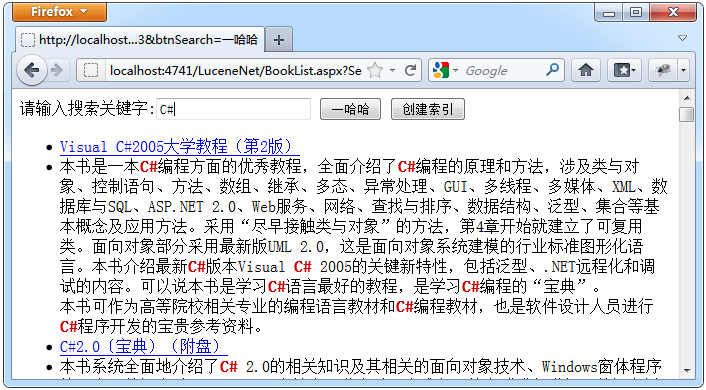
图2 对数据库新增数据后 索引库更新效果图
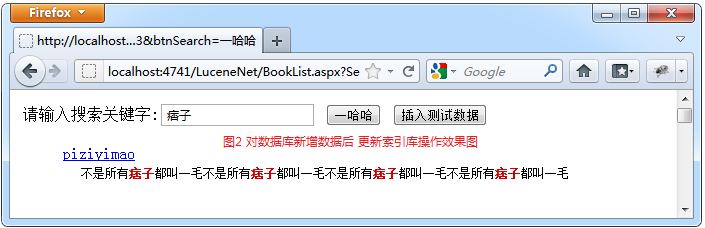
图3 将图2中的新增数据修改后 索引库更新效果图
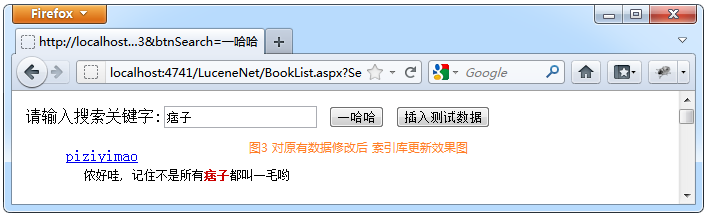
Demo文件说明
简单使用
图1中的BookList.aspx 页面
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="BookList.aspx.cs" Inherits="Web.LuceneNet.BookList" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title></title>
</head>
<body>
<form id="form1" method="get" action="BookList.aspx">
<div>
请输入搜索关键字:<input type="text" name="SearchKey" value="" />
<input type="submit" name="btnSearch" value="一哈哈" />
<input type="submit" name="btnCreate" value="创建索引" />
<br />
<ul>
<asp:Repeater ID="Repeater1" runat="server">
<ItemTemplate>
<li><a href='#'>
<%# Eval("Title") %></a></li>
<li><span>
<%# Eval("ContentDescription") %></span></li>
</ItemTemplate>
</asp:Repeater>
</ul>
</div>
</form>
</body>
</html>
BookList.aspx.cs 后台的处理操作
using System;
using System.Collections.Generic;
using System.IO;
using Lucene.Net.Analysis.PanGu;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.Search;
using Lucene.Net.Store;
using PZYM.Shop.BLL;
namespace Web.LuceneNet {
public partial class BookList : System.Web.UI.Page {
protected void Page_Load(object sender, EventArgs e) {
string btnCreate = Request.QueryString["btnCreate"];
string btnSearch = Request.QueryString["btnSearch"];
if(!string.IsNullOrEmpty(btnCreate)) {
//创建索引库
CreateIndexByData();
}
if(!string.IsNullOrEmpty(btnSearch)) {
//搜索
SearchFromIndexData();
}
}
/// <summary>
/// 创建索引
/// </summary>
private void CreateIndexByData() {
string indexPath = Context.Server.MapPath("~/IndexData");//索引文档保存位置 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());
//IndexReader:对索引库进行读取的类
bool isExist = IndexReader.IndexExists(directory); //是否存在索引库文件夹以及索引库特征文件
if(isExist) {
//如果索引目录被锁定(比如索引过程中程序异常退出或另一进程在操作索引库),则解锁
//Q:存在问题 如果一个用户正在对索引库写操作 此时是上锁的 而另一个用户过来操作时 将锁解开了 于是产生冲突 --解决方法后续
if(IndexWriter.IsLocked(directory)) {
IndexWriter.Unlock(directory);
}
}
//创建向索引库写操作对象 IndexWriter(索引目录,指定使用盘古分词进行切词,最大写入长度限制)
//补充:使用IndexWriter打开directory时会自动对索引库文件上锁
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isExist, IndexWriter.MaxFieldLength.UNLIMITED);
BooksManager bookManager = new BooksManager();
List<PZYM.Shop.Model.Books> bookList = bookManager.GetModelList("");
//--------------------------------遍历数据源 将数据转换成为文档对象 存入索引库
foreach(var book in bookList) {
Document document = new Document(); //new一篇文档对象 --一条记录对应索引库中的一个文档
//向文档中添加字段 Add(字段,值,是否保存字段原始值,是否针对该列创建索引)
document.Add(new Field("id", book.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));//--所有字段的值都将以字符串类型保存 因为索引库只存储字符串类型数据
//Field.Store:表示是否保存字段原值。指定Field.Store.YES的字段在检索时才能用document.Get取出原值 //Field.Index.NOT_ANALYZED:指定不按照分词后的结果保存--是否按分词后结果保存取决于是否对该列内容进行模糊查询
document.Add(new Field("title", book.Title, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
//Field.Index.ANALYZED:指定文章内容按照分词后结果保存 否则无法实现后续的模糊查询
//WITH_POSITIONS_OFFSETS:指示不仅保存分割后的词 还保存词之间的距离
document.Add(new Field("content", book.ContentDescription, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document); //文档写入索引库
}
writer.Close();//会自动解锁
directory.Close(); //不要忘了Close,否则索引结果搜不到
}
/// <summary>
/// 从索引库中检索关键字
/// </summary>
private void SearchFromIndexData() {
string indexPath = Context.Server.MapPath("~/IndexData");
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
//搜索条件
PhraseQuery query = new PhraseQuery();
//把用户输入的关键字进行分词
foreach(string word in Common.SplitContent.SplitWords(Request.QueryString["SearchKey"])) {
query.Add(new Term("content", word));
}
//query.Add(new Term("content", "C#"));//多个查询条件时 为且的关系
query.SetSlop(100); //指定关键词相隔最大距离
//TopScoreDocCollector盛放查询结果的容器
TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true);
searcher.Search(query, null, collector);//根据query查询条件进行查询,查询结果放入collector容器
//TopDocs 指定0到GetTotalHits() 即所有查询结果中的文档 如果TopDocs(20,10)则意味着获取第20-30之间文档内容 达到分页的效果
ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;
//展示数据实体对象集合
List<PZYM.Shop.Model.Books> bookResult = new List<PZYM.Shop.Model.Books>();
for(int i = 0; i < docs.Length; i++) {
int docId = docs[i].doc;//得到查询结果文档的id(Lucene内部分配的id)
Document doc = searcher.Doc(docId);//根据文档id来获得文档对象Document
PZYM.Shop.Model.Books book = new PZYM.Shop.Model.Books();
book.Title = doc.Get("title");
//book.ContentDescription = doc.Get("content");//未使用高亮
//搜索关键字高亮显示 使用盘古提供高亮插件
book.ContentDescription = Common.SplitContent.HightLight(Request.QueryString["SearchKey"], doc.Get("content"));
book.Id = Convert.ToInt32(doc.Get("id"));
bookResult.Add(book);
}
Repeater1.DataSource = bookResult;
Repeater1.DataBind();
}
}
}
使用的分词方法与关键字变红 SplitContent.cs
using System.Collections.Generic;
using System.IO;
using Lucene.Net.Analysis;
using Lucene.Net.Analysis.PanGu;
using PanGu;
namespace Web.Common {
public class SplitContent {
public static string[] SplitWords(string content) {
List<string> strList = new List<string>();
Analyzer analyzer = new PanGuAnalyzer();//指定使用盘古 PanGuAnalyzer 分词算法
TokenStream tokenStream = analyzer.TokenStream("", new StringReader(content));
Lucene.Net.Analysis.Token token = null;
while((token = tokenStream.Next()) != null) { //Next继续分词 直至返回null
strList.Add(token.TermText()); //得到分词后结果
}
return strList.ToArray();
}
//需要添加PanGu.HighLight.dll的引用
/// <summary>
/// 搜索结果高亮显示
/// </summary>
/// <param name="keyword"> 关键字 </param>
/// <param name="content"> 搜索结果 </param>
/// <returns> 高亮后结果 </returns>
public static string HightLight(string keyword, string content) {
//创建HTMLFormatter,参数为高亮单词的前后缀
PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter =
new PanGu.HighLight.SimpleHTMLFormatter("<font style="font-style:normal;color:#cc0000;"><b>", "</b></font>");
//创建 Highlighter ,输入HTMLFormatter 和 盘古分词对象Semgent
PanGu.HighLight.Highlighter highlighter =
new PanGu.HighLight.Highlighter(simpleHTMLFormatter,
new Segment());
//设置每个摘要段的字符数
highlighter.FragmentSize = 1000;
//获取最匹配的摘要段
return highlighter.GetBestFragment(keyword, content);
}
}
}
重点类的说明
Analyzer类:LuceneNet中分词算法的基类 任何自定义算法都需继承它
FSDirectory类: 指定索引库文件存放文件位置 是Directory的子类(它有两个子类 还有一个RAMDirecory,它用来指定将索引库文件存放在内存中)
IndexReader:对索引进行读取的类
静态方法bool IndexExists(Directory directory)--判断目录directory是否是一个索引目录
IndexWriter:对索引进行写的类
静态方法bool IsLocked(Directory directory)--判断目录是否锁定
它在对索引目录写之前会把目录锁定,两个IndexWrite无法同时操作一个索引文件
IndexWrite在进行写操作的时候会自动加锁
Close自动解锁
Unlock手动解锁(通常用在程序异常退出 IndexWrite还没来得及close)
Document类:要检索的文档 相当于一条记录
Add(Field field)向文档中添加字段
Filed类:构造函数(字段名,字段值,是否存储原文,是否对该字段创建索引,存储索引词间距)
是否存储原文:Field.Store.YES 存储原值(如显示原内容必须为YES) Field.Store.NO不存储原值 Field.Store.YES压缩存储
是否创建索引:Field.Index.NOT_ANALYZED不创建索引 Field.Index.ANALYZED创建索引(利于检索)
IndexSearcher:搜索类 Searcher类的子类
Search(查询条件Query,过滤条件Filter,检索见过存放容器Collector)
Query类:所有查询条件父类(子类都具有Add方法)
子类PhraseQuery:多个关键词的拼接类 关键词间是且的关系
query.Add(new Term("字段名", 关键词))
query.Add(new Term("字段名2", 关键词2))
类似于:where 字段名 contains 关键词 and 字段名2 contains 关键词2
子类BooleanQuery:类似PharseQuery 通过它实现关键词间的或关系(MUST必须有 Should可有可无 MUST_NOT必须没有 详见BookList2.aspx.cs代码)
存在问题
上述只是Lucene.Net的简单使用
接下来我们深入探讨上述使用过程中存在的一些问题以及指的改进的地方:
Q1:创建索引事件耗时的操作,尤其是在数据量很大的情况下,索引库生成耗时是个问题
Q2:真实项目中肯定不可能存在创建索引按钮,那创建索引的事件什么时候触发,由谁触发呢?
Q3:如代码中的Q一样 多个用户共同操作索引库时的并发问题
解答上述三个问题
A1.耗时的操作当然另起一个后台线程来完成撒
A2.在网站Application_Start的时,利用A1中的后台线程循环监听Books表的增删改操作,在对Books表的增删改成功之后,对索引库相对应的数据做出增删改操作
A3.并发问题最好的解决方式--建立请求队列,单线程处理队列,类似于操作系统的中的生产者消费者模式
调整后
IndexManager.cs类中定义后台线程 循环监听请求队列 负责对索引库的更新操作
using System.Collections.Generic;
using System.IO;
using System.Threading;
using System.Web;
using Lucene.Net.Analysis.PanGu;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.Store;
using PZYM.Shop.Model;
namespace Web.LuceneNet {
public class IndexManager {
public static readonly IndexManager bookIndex = new IndexManager();
public static readonly string indexPath = HttpContext.Current.Server.MapPath("~/IndexData");
private IndexManager() {
}
//请求队列 解决索引目录同时操作的并发问题
private Queue<BookViewMode> bookQueue = new Queue<BookViewMode>();
/// <summary>
/// 新增Books表信息时 添加邢增索引请求至队列
/// </summary>
/// <param name="books"></param>
public void Add(Books books) {
BookViewMode bvm = new BookViewMode();
bvm.Id = books.Id;
bvm.Title = books.Title;
bvm.IT = IndexType.Insert;
bvm.Content = books.ContentDescription;
bookQueue.Enqueue(bvm);
}
/// <summary>
/// 删除Books表信息时 添加删除索引请求至队列
/// </summary>
/// <param name="bid"></param>
public void Del(int bid) {
BookViewMode bvm = new BookViewMode();
bvm.Id = bid;
bvm.IT = IndexType.Delete;
bookQueue.Enqueue(bvm);
}
/// <summary>
/// 修改Books表信息时 添加修改索引(实质上是先删除原有索引 再新增修改后索引)请求至队列
/// </summary>
/// <param name="books"></param>
public void Mod(Books books) {
BookViewMode bvm = new BookViewMode();
bvm.Id = books.Id;
bvm.Title = books.Title;
bvm.IT = IndexType.Modify;
bvm.Content = books.ContentDescription;
bookQueue.Enqueue(bvm);
}
public void StartNewThread() {
ThreadPool.QueueUserWorkItem(new WaitCallback(QueueToIndex));
}
//定义一个线程 将队列中的数据取出来 插入索引库中
private void QueueToIndex(object para) {
while(true) {
if(bookQueue.Count > 0) {
CRUDIndex();
} else {
Thread.Sleep(3000);
}
}
}
/// <summary>
/// 更新索引库操作
/// </summary>
private void CRUDIndex() {
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NativeFSLockFactory());
bool isExist = IndexReader.IndexExists(directory);
if(isExist) {
if(IndexWriter.IsLocked(directory)) {
IndexWriter.Unlock(directory);
}
}
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isExist, IndexWriter.MaxFieldLength.UNLIMITED);
while(bookQueue.Count > 0) {
Document document = new Document();
BookViewMode book = bookQueue.Dequeue();
if(book.IT == IndexType.Insert) {
document.Add(new Field("id", book.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
document.Add(new Field("title", book.Title, Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
document.Add(new Field("content", book.Content, Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document);
} else if(book.IT == IndexType.Delete) {
writer.DeleteDocuments(new Term("id", book.Id.ToString()));
} else if(book.IT == IndexType.Modify) {
//先删除 再新增
writer.DeleteDocuments(new Term("id", book.Id.ToString()));
document.Add(new Field("id", book.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
document.Add(new Field("title", book.Title, Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
document.Add(new Field("content", book.Content, Field.Store.YES, Field.Index.ANALYZED,
Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document);
}
}
writer.Close();
directory.Close();
}
}
public class BookViewMode {
public int Id {
get;
set;
}
public string Title {
get;
set;
}
public string Content {
get;
set;
}
public IndexType IT {
get;
set;
}
}
//操作类型枚举
public enum IndexType {
Insert,
Modify,
Delete
}
}
BookList2.aspx与BookList.aspx大同小异 这里不给出了
BookList2.aspx.cs 对数据库数据新增 修改 删除等操作
using System;
using System.Collections.Generic;
using System.IO;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.Search;
using Lucene.Net.Store;
using PZYM.Shop.BLL;
using PZYM.Shop.Model;
namespace Web.LuceneNet {
public partial class BookList2 : System.Web.UI.Page {
protected void Page_Load(object sender, EventArgs e) {
string btnInsert = Request.QueryString["btnInsert"];
string btnSearch = Request.QueryString["btnSearch"];
if(!string.IsNullOrEmpty(btnInsert)) {
//数据新增至索引库
InsertToIndex();
}
if(!string.IsNullOrEmpty(btnSearch)) {
//搜索
SearchFromIndexData();
}
}
//临时数据代替表单提交
private void InsertToIndex() {
//创建一条临时数据
Books book = new Books();
book.Author = "痞子一毛";
book.Title = "piziyimao";
book.CategoryId = 1;
book.ContentDescription = "不是所有痞子都叫一毛不是所有痞子都叫一毛不是所有痞子都叫一毛不是所有痞子都叫一毛";
book.PublisherId = 1;
book.ISBN = "124365";
book.WordsCount = 1000000;
book.UnitPrice = 88;
book.CategoryId = 1;
book.Clicks = 10;
book.PublishDate = DateTime.Now;
BooksManager bm = new BooksManager();
//IndexManager.bookIndex.Add()数据新增 索引库更新测试
//int insertId;
//if((insertId = bm.Add(book)) > 0) {
// book.Id = insertId;
// IndexManager.bookIndex.Add(book);
//}
//IndexManager.bookIndex.Mod()数据修改 索引库更新测试
book.Id = 10001;//数据库生成主键ID
book.ContentDescription = "侬好哇, 记住不是所有痞子都叫一毛哟";
bm.Update(book);
IndexManager.bookIndex.Mod(book);
}
/// <summary>
/// 从索引库中检索关键字
/// </summary>
private void SearchFromIndexData() {
string indexPath = Context.Server.MapPath("~/IndexData");
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
//--------------------------------------这里配置搜索条件
//PhraseQuery query = new PhraseQuery();
//foreach(string word in Common.SplitContent.SplitWords(Request.QueryString["SearchKey"])) {
// query.Add(new Term("content", word));//这里是 and关系
//}
//query.SetSlop(100);
//关键词Or关系设置
BooleanQuery queryOr = new BooleanQuery();
TermQuery query = null;
foreach(string word in Common.SplitContent.SplitWords(Request.QueryString["SearchKey"])) {
query = new TermQuery(new Term("content", word));
queryOr.Add(query, BooleanClause.Occur.SHOULD);//这里设置 条件为Or关系
}
//--------------------------------------
TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true);
//searcher.Search(query, null, collector);
searcher.Search(queryOr, null, collector);
ScoreDoc[] docs = collector.TopDocs(0, 10).scoreDocs;//取前十条数据 可以通过它实现LuceneNet搜索结果分页
List<PZYM.Shop.Model.Books> bookResult = new List<PZYM.Shop.Model.Books>();
for(int i = 0; i < docs.Length; i++) {
int docId = docs[i].doc;
Document doc = searcher.Doc(docId);
PZYM.Shop.Model.Books book = new PZYM.Shop.Model.Books();
book.Title = doc.Get("title");
book.ContentDescription = Common.SplitContent.HightLight(Request.QueryString["SearchKey"], doc.Get("content"));
book.Id = Convert.ToInt32(doc.Get("id"));
bookResult.Add(book);
}
Repeater1.DataSource = bookResult;
Repeater1.DataBind();
}
}
}
Global.ascx中设置
protected void Application_Start(object sender, EventArgs e) {
IndexManager.bookIndex.StartNewThread();
}
Lucene.Net博文与资源下载
http://www.cnblogs.com/birdshover/category/152283.html
http://www.360doc.com/content/13/0509/08/5054188_284048627.shtml