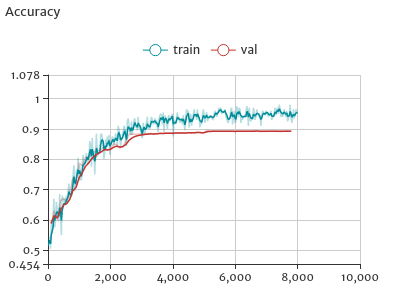
pycaffe训练的完整组件示例
为什么写这篇博客
1. 需要用到pycaffe
因为用到的开源代码基于Caffe;要维护的项目基于Caffe。基本上是用Caffe的Python接口。
2. 训练中想穿插验证并输出关注的指标
比如每训练完1个epoch就应该在完整的validation集合上执行evaluation,输出测量出的、关注的指标,例如AP、Accuracy、F1-score等。Caffe通过solver.prototxt中配置test_net能执行测试,但基本只能输出Accuracy而且是各个test_batch上的平均Accuracy,而不是想关注的验证集整体上的AP(见Solver.cpp源码)
3. 训练中期望有可视化输出
Caffe训练输出在屏幕终端,也可自行重定向到日志文件。的确可以自行解析日志文件,并结合flask搭建web页面实时显示输出。但是这不够标准和鲁棒。期望有专门的可视化工具,避免自己造难用的轮子。
本文给出很简陋的pyCaffe和VisualDL结合的例子。
解决方案
用pycaffe接管训练接口
通过自行编写python代码来执行训练,而不是用$CAFFE_ROOT/build/tools/caffe train --solver solver.prototxt的方式来启动。
- solver.prototxt中需要配置test_net, test_iter, test_interval,保证solver有test_net对象
- test_interval设置为999999999,以避开Solver.cpp中执行的TestAll()函数,转而在python代码中手动判断和执行validation
- 执行validation之前注意test_net.share_with(train_net)
- 利用solver.step(1)执行训练网络的一次迭代,利用solver.test_net[0].forward()执行测试网络的一次前传
- 利用
net.blobs['prob'].data的形式取出网络输出 - 利用sklearn.metrics包,将取出的数据执行evaluation
- 利用VisualDL等可视化工具,将取出的数据执行绘图
依赖项
VisualDL,是PaddlePaddle和ECharts团队联合推出的,应该是对抗谷歌的Tensorboarde的。相信ECharts的实力。
sudo pip install visualdl
看起来VisualDL和Tensorboard类似,不过对于Caffe,用不了Tensorboard,能用VisualDL也是好事。
参考代码
solve.py
#!/usr/bin/env python2
# coding: utf-8
"""
inspired and adapted from:
- https://github.com/shelhamer/fcn.berkeleyvision.org
- https://github.com/rbgirshick/py-faster-rcnn
- https://github.com/PaddlePaddle/VisualDL/blob/develop/docs/quick_start_en.md
"""
from __future__ import print_function
import _init_paths
import caffe
import argparse
import os
import sys
from datetime import datetime
import cv2
from caffe.proto import caffe_pb2
import google.protobuf as pb2
import google.protobuf.text_format
import numpy as np
import perfeval
from visualdl import LogWriter #for visualization during training
def parse_args():
"""Parse input arguments"""
parser = argparse.ArgumentParser(description='Train a classification network')
parser.add_argument('--solver', dest='solver',
help='solver prototxt',
default=None, type=str, required=True)
parser.add_argument('--weights', dest='pretrained_model',
help='initialize with pretrained model weights',
default=None, type=str)
if len(sys.argv) == 1:
parser.print_help()
sys.exit(1)
args = parser.parse_args()
return args
class SolverWrapper:
"""对于Solver进行封装,便于外部调用"""
def __init__(self, solver_prototxt, num_epoch, num_example, pretrained_model=None):
self.solver = caffe.SGDSolver(solver_prototxt)
if pretrained_model is not None:
print('Loading pretrained model weights from {:s}'.format(pretrained_model))
self.solver.net.copy_from(pretrained_model)
self.solver_param = caffe_pb2.SolverParameter()
with open(solver_prototxt, 'rt') as f:
pb2.text_format.Merge(f.read(), self.solver_param)
self.cur_epoch = 0
self.test_interval = 100 #用来替代self.solver_param.test_interval
self.logw = LogWriter("catdog_log", sync_cycle=100)
with self.logw.mode('train') as logger:
self.sc_train_loss = logger.scalar("loss")
self.sc_train_acc = logger.scalar("Accuracy")
with self.logw.mode('val') as logger:
self.sc_val_acc = logger.scalar("Accuracy")
self.sc_val_mAP = logger.scalar("mAP")
def train_model(self):
"""执行训练的整个流程,穿插了validation"""
cur_iter = 0
test_batch_size, num_classes = self.solver.test_nets[0].blobs['prob'].shape
num_test_images_tot = test_batch_size * self.solver_param.test_iter[0]
while cur_iter < self.solver_param.max_iter:
#self.solver.step(self.test_interval)
for i in range(self.test_interval):
self.solver.step(1)
loss = self.solver.net.blobs['loss'].data
acc = self.solver.net.blobs['accuracy'].data
step = self.solver.iter
self.sc_train_loss.add_record(step, loss)
self.sc_train_acc.add_record(step, acc)
self.eval_on_val(num_classes, num_test_images_tot, test_batch_size)
cur_iter += self.test_interval
def eval_on_val(self, num_classes, num_test_images_tot, test_batch_size):
"""在整个验证集上执行inference和evaluation"""
self.solver.test_nets[0].share_with(self.solver.net)
self.cur_epoch += 1
scores = np.zeros((num_classes, num_test_images_tot), dtype=float)
gt_labels = np.zeros((1, num_test_images_tot), dtype=float).squeeze()
for t in range(self.solver_param.test_iter[0]):
output = self.solver.test_nets[0].forward()
probs = output['prob']
labels = self.solver.test_nets[0].blobs['label'].data
gt_labels[t*test_batch_size:(t+1)*test_batch_size] = labels.T.astype(float)
scores[:,t*test_batch_size:(t+1)*test_batch_size] = probs.T
ap, acc = perfeval.cls_eval(scores, gt_labels)
print('====================================================================
')
print(' Do validation after the {:d}-th training epoch
'.format(self.cur_epoch))
print('>>>>', end=' ') #设定标记,方便于解析日志获取出数据
for i in range(num_classes):
print('AP[{:d}]={:.2f}'.format(i, ap[i]), end=', ')
mAP = np.average(ap)
print('mAP={:.2f}, Accuracy={:.2f}'.format(mAP, acc))
print('
====================================================================
')
step = self.solver.iter
self.sc_val_mAP.add_record(step, mAP)
self.sc_val_acc.add_record(step, acc)
if __name__ == '__main__':
args = parse_args()
solver_prototxt = args.solver
num_epoch = args.num_epoch
num_batch = args.num_batch
pretrained_model = args.pretrained_model
# init
caffe.set_mode_gpu()
caffe.set_device(0)
sw = SolverWrapper(solver_prototxt, num_epoch, num_batch, pretrained_model)
sw.train_model()
perfeval.py
#!/usr/bin/env python2
# coding: utf-8
from __future__ import print_function
import numpy as np
import sklearn.metrics as metrics
def cls_eval(scores, gt_labels):
"""
分类任务的evaluation
@param scores: cxm np-array, m为样本数量(例如一个epoch)
@param gt_labels: 1xm np-array, 元素属于{0,1,2,...,K-1},表示K个类别的索引
"""
num_classes, num_test_imgs = scores.shape
pred_labels = scores.argmax(axis=0)
ap = np.zeros((num_classes, 1), dtype=float).squeeze()
for i in range(num_classes):
cls_labels = np.zeros((1, num_test_imgs), dtype=float).squeeze()
for j in range(num_test_imgs):
if gt_labels[j]==i:
cls_labels[j]=1
ap[i] = metrics.average_precision_score(cls_labels, scores[i])
acc = metrics.accuracy_score(gt_labels, pred_labels)
return ap, acc
样例输出
首先需要开启训练,比如:
python solve.py
然后启动VisualDL:
visualDL --logdir=catdog_log --port=8080
打开浏览器获取训练的实时更新的绘图输出:http://localhost:8080。这里仅截图展示: