一、mysql完整语句顺序
select [ALL|DISTINCT|DISTINCTROW|TOP] {*|talbe.*|[table.]field1[AS alias1][,[table.]field2[AS alias2][,…]]} FROM tableexpression[,…][IN externaldatabase] [WHERE…] [GROUP BY…] [HAVING…] [ORDER BY…]
例子:
完成一个复杂的查询语句,需求如下:
按由高到低的顺序显示个人平均分在70分以上的学生姓名和平均分,为了尽可能地提高平均分,在计算平均分前不包括分数在60分以下的成绩,并且也不计算贱人(jr)的成绩。
分析:
1.要求显示学生姓名和平均分
因此确定第1步
|
1
|
select s_name,avg(score) from student |
2.计算平均分前不包括分数在60分以下的成绩,并且也不计算贱人(jr)的成绩
因此确定第2步
|
1
|
where score>=60 and s_name !=’jr’ |
3.显示个人平均分
相同名字的学生(同一个学生)考了多门科目 因此按姓名分组
确定第3步
|
1
|
group by s_name |
4.显示个人平均分在70分以上
因此确定第4步
|
1
|
having avg(s_score)>=70 |
5.按由高到低的顺序
因此确定第5步
|
1
|
order by avg(s_score) desc |
二、问题
1.where 和group by having 使用 执行顺序 (先where 再 group by having)
当两者结合在一起时,where在前,group by 在后。即先对select xx from xx的记录集合用where进行筛选,然后再使用group by 对筛选后的结果进行分组 使用having字句对分组后的结果进行筛选。
需要注意having和where的用法区别:
1.having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
2.where肯定在group by 之前
3.where后的条件表达式里不允许使用聚合函数,而having可以。
补充:当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是:
1.执行where xx对全表数据做筛选,返回第1个结果集。
2.针对第1个结果集使用group by分组,返回第2个结果集。
3.针对第2个结果集中的每1组数据执行select xx,有几组就执行几次,返回第3个结果集。
4.针对第3个结集执行having xx进行筛选,返回第4个结果集。
5.针对第4个结果集排序。
2.@使用自变量,求行号、排名
SELECT a.*, (@rowNum:=@rowNum+1) AS rank #计算行号 FROM table_score AS a, (SELECT (@rowNum :=0) ) b ORDER BY a.score DESC;
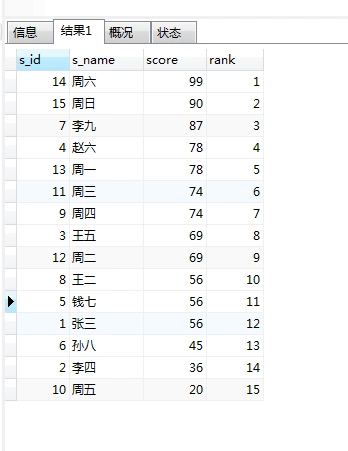
三、题库
常见坑:数据重复、排名不唯一、没有数据、是否为null
1.组合两张表

因为表 Address 中的 personId 是表 Person 的外关键字,所以我们可以连接这两个表来获取一个人的地址信息。
考虑到可能不是每个人都有地址信息,我们应该使用 outer join (包含 left join 和 right join) 而不是默认的 inner join。
select FirstName, LastName, City, State from Person left join Address on Person.PersonId = Address.PersonId
注意:如果没有某个人的地址信息,使用 where 子句过滤记录将失败,因为它不会显示姓名信息。
2.获取第二高的薪水

考虑薪水相同的情况,使用distinct将不同的薪资按降序排序,然后使用 LIMIT 子句获得第二高的薪资。
执行sql 没有找到数据 也是返回null
使用 IFNULL 和 LIMIT 子句
解决 “NULL” 问题的另一种方法是使用 “IFNULL” 函数,如下所示。
MySQL SELECT IFNULL( (SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 1 OFFSET 1), NULL) AS SecondHighestSalary
mysql ISNULL IFNULL NULLIF函数用法
一、ISNULL(expr)
如果expr 为NULL,那么ISNULL() 的返回值为 1,否则返回值为 0。
->select isnull(11); ->0; ->select isnull(null); ->1;
二、IFNULL(expr1,expr2)
1、若expr1不为null,则ifnull()的返回值为expr1;
2、若expr1为null,则返回expr2的值;
->select ifnull(1, 2); ->1; ->select ifnull(null, 2); ->2; ->select ifnull(null, 'test'); ->test;
三、nullif(expr1,expr2)
若expr1等于expr2,则返回null,否则返回expr1
mysql>SELECT NULLIF(1,1); ->NULL mysql>SELECT NULLIF(1,2); ->1
补充:输出第 N 大的项,如果不存在则返回 null
不同之处在于 limit 的参数不能为表达式,所以 N 需要预先减一
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN SET n = N-1; RETURN ( SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT n,1 ); END
3.分数排名

求排名的方法(可能有并列情况)
方法1 自查询
我们可以先提取出大于等于X的所有分数集合H,将H去重后的元素个数就是X的排名。比如你考了99分,但最高的就只有99分,那么去重之后集合H里就只有99一个元素,个数为1,因此你的Rank为1。
例如:比如你考了98分,,你同学a也考了98分,找到大于等于你的成绩,一个99分,一个98分,一个98分,去重复,就一个99,一个98,count一下总数,第二名,如果有三个同学考了97呢,同理,99,98,98,97,97,97 后面比这个少的,已经死在了筛选条件,去重,99,98,97,count=3
首先sql的执行顺序是from, where,select,其次找出排名也就相当于找出大于等于该数的不重复数字有几个(数相同排名相同).用group by 是因为需要对每个数据进行排名
-- 方法: 自连接 -- 目的:对于一个成绩,查找出大于等于它的成绩(去重)的数量即为其排名,整理排序即得结果 SELECT a.Score AS Score, COUNT(DISTINCT b.Score) AS Rank -- 注意按题目要求去重复值 FROM Scores AS a, Scores AS b WHERE b.Score >= a.Score -- 表b中有x个非重复值大于等于表a当前值,则表a当前成绩排名为x GROUP BY a.id -- 由于成绩即使重复也要显示,故通过id分组 ORDER BY a.Score DESC
方法2 使用变量
先假设分数唯一的情况
SELECT a.score as Score,@rank := @rank + 1 as Rank FROM `score` as a ,(select @rank := 0) as b ORDER BY a.score desc
再考虑可能并列情况
首先根据任务进行分析,目的进行连续的并列排序,并且以整型的字段返回。
语句执行顺序为 from -> oder by -> select (这是每个查询执行的顺序,子查询也一样) 对分数进行判断,相同即排名不变,不相同排名加一。
使用if语句进行判断,ex:if(a>1,A,B) 如果为真返回A,反之返回B
SELECT Score, Rank FROM (SELECT Score, @curRank := IF(@prevRank = Score, @curRank+0,@curRank:=@curRank+1) AS Rank, @prevRank := Score FROM Scores, ( SELECT @curRank :=0, @prevRank := NULL ) r ORDER BY Score DESC) s
4.连续出现的数字
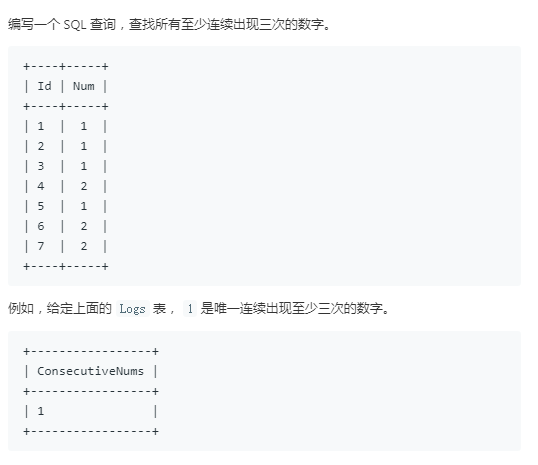
方法1
下面是学生的成绩表(表名score,列名:学号、成绩),使用SQL查找所有至少连续出现3次的成绩。
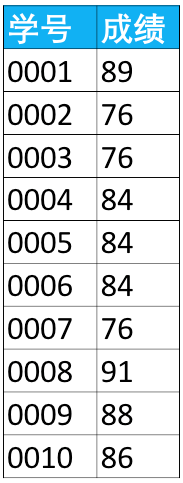
例如,“成绩”这一列里84是连续出现3次的成绩。
【解题思路】
1.什么是连续出现3次?
假设“学号”是按顺序排列的(如果不是,可以使用增加一列,让学号是按序号顺序排列的),所以每一学号与上一学号相差1。例如下图的3个学号是连续学号,他们之间的关系是:
某一学号(0002)=下一位的学号(0003)-1
下一位学号(0003)=下下位学号(0004)-1

2.如果这3个连续学号的成绩相等,就是题目要求的“至少连续出现3次的成绩”。
3.利用“自连接(自身连接)“的思路
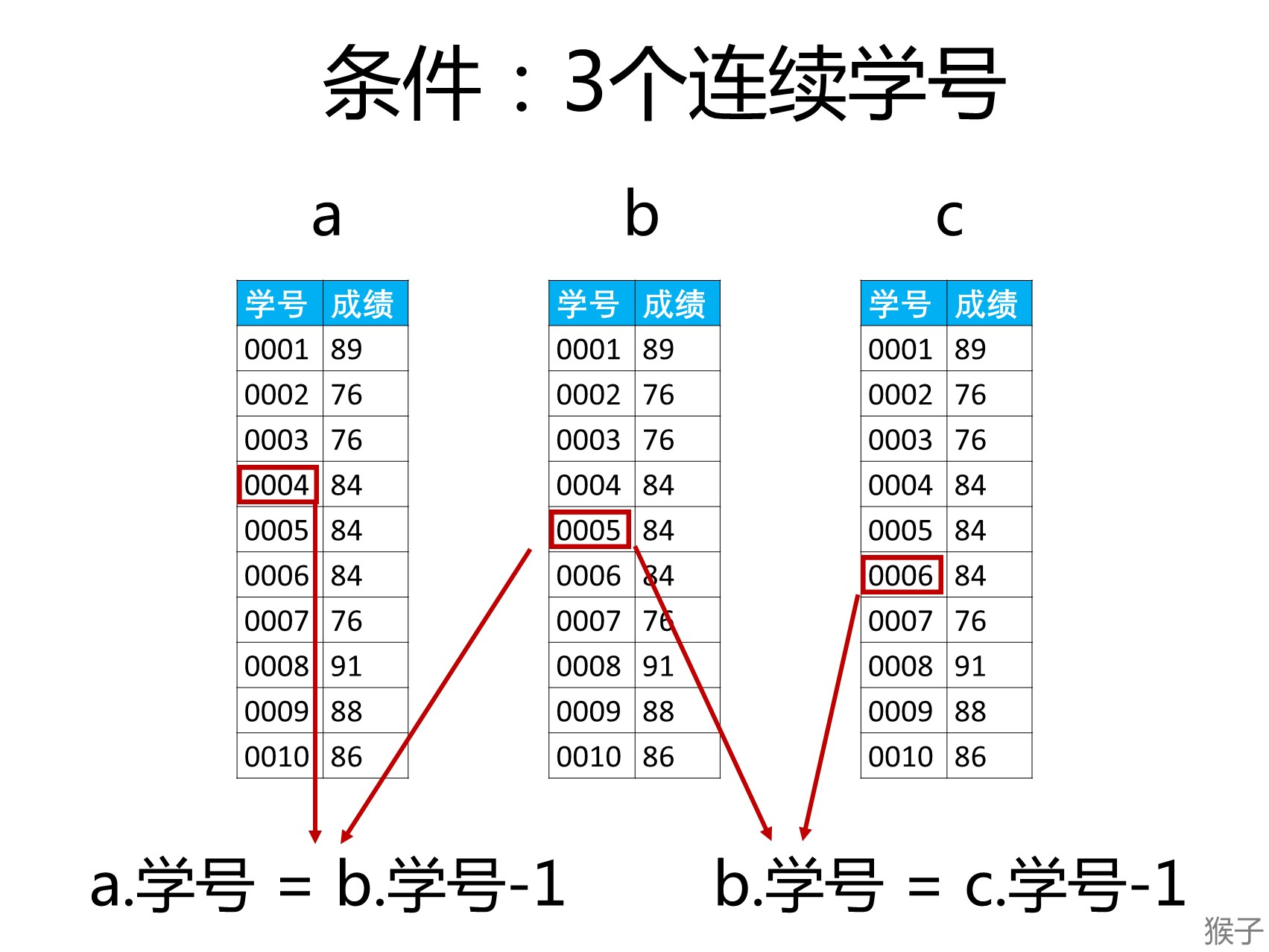
自连接(自身连接)的本质是把一张表复制出多张一模一样的表来使用。SQL语法:
将成绩表(score)复制3分,分别命名为a、b、c
我们需要找到这3个表中3个连续的学号,这个条件如下
a.学号 = b.学号-1 and b.学号 = c.学号-1
还要让这3个学号连续的人“成绩相等”,这个条件如下
a.成绩 = b.成绩 and b.成绩 = c.成绩
将步骤2和步骤3的条件合并起来就是下面SQL里的where字句:
select *
from score as a,
score as b,
score as c;
where a.学号 = b.学号 - 1
and b.学号 = c.学号 - 1
and a.成绩 = b.成绩
and b.成绩 = c.成绩;
步骤4)前面步骤已经将连续3人相等的成绩找出,现在用distinct去掉自连接产生的重复数。最终SQL如下:
select distinct a.成绩 as 最终答案
from score as a,
score as b,
score as c;
where a.学号 = b.学号 - 1
and b.学号 = c.学号 - 1
and a.成绩 = b.成绩
and b.成绩 = c.成绩;
【本题考点】
• 本题考察的是连续出现,会有同学忽略“连续”二字
• 考察对自关联的灵活应用
• 从题目连续3次成绩相等,判断出“成绩相等”和“学号连续”这2个条件。考察构建“连续学号成绩相等”的思维构建能力
方法2
思路:
1、由于要获取至少连续三次出现的数字,看到这个题肯定是会变的,如果是至少连续出现四次呢(100次呢),咱们连接四个表(连接一千个?)?这种方法肯定是不可取的。
2、找规律,找出这连续起来的数字有什么规律呢,我们会发现连续的数字是相同的数字,但是id有可能不是连续的,我们就需要通过对结果集进行再次编号,让其变成连续的。
原始数据:

3、首先我们获取到对每条数据编号从1开始使用row_number()函数使用id来排序既row_number() over(order by id)

结果为:
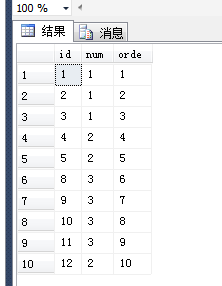
4、然后我们通过另一种方式排序将,这些num值一样的进行排序,然后对其编号同样使用row_bumber()使用num来分组使用id排序 over(partition by num order by id)

结果为:
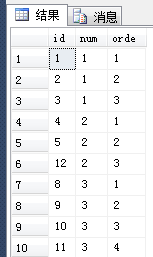
5、通过3、4步骤我们能得到什么呢,两个相减之后我们可以得到,只要是相等的,则相减的值是一样的。而且如果不连续的话相减值也不一样。

结果为:
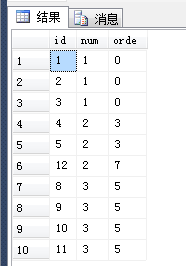
这样是不是一目了然呢,最后在通过num和orde两个共同分组找到一样的一共有几个,我们就可以找到连续的了。

结果为:

5.超过经理收入的员工

方法1
SELECT a.Name AS 'Employee' FROM Employee AS a, Employee AS b WHERE a.ManagerId = b.Id AND a.Salary > b.Salary
方法2
SELECT a.NAME AS Employee FROM Employee AS a JOIN Employee AS b ON a.ManagerId = b.Id AND a.Salary > b.Salary ;
6.查找重复的电子邮箱

方法一:使用 GROUP BY 和临时表
算法
重复的电子邮箱存在多次。要计算每封电子邮件的存在次数,我们可以使用以下代码。
select Email, count(Email) as num from Person group by Email;

以此作为临时表,我们可以得到下面的解决方案。
select Email from ( select Email, count(Email) as num from Person group by Email ) as statistic where num > 1
踩坑点

Every derived table must have its own alias意思是每个派生出来的表必须有一个自己的别名
一般是在多表查询或者子查询的时候会出现这个错误,因为在嵌套查询中,子查询的结果是作为一个派生表给上一级进行查询,所以子查询的结果必须有一个别名。
方法二:使用 GROUP BY 和 HAVING 条件
向 GROUP BY 添加条件的一种更常用的方法是使用 HAVING 子句,该子句更为简单高效。
所以我们可以将上面的解决方案重写为:
select Email from Person group by Email having count(Email) > 1;
7.从不订购的客户

方法1:
我们可以使用下面的代码来获得这样的列表。
select customerid from orders;
然后,我们可以使用 NOT IN 查询不在此列表中的客户。
select customers.name as 'Customers' from customers where customers.id not in ( select customerid from orders );
方法2:
select Name as Customers from Customers c left join Orders o on c.Id=o.CustomerId where o.CustomerId is null
坑点:只能采用IS NULL或IS NOT NULL,而不能采用=, <, <>, !=这些操作符来判断NULL。
8.超过经理收入的员工
方法 1:使用 WHERE 语句
算法
如下面表格所示,表格里存有每个雇员经理的信息,我们也许需要从这个表里获取两次信息。
SELECT * FROM Employee AS a, Employee AS b ;
注意:关键词 'AS' 是可选的

前 3 列来自表格 a ,后 3 列来自表格 b
从两个表里使用 Select 语句可能会导致产生 笛卡尔乘积 。在这种情况下,输出会产生 4*4=16 个记录。然而我们只对雇员工资高于经理的人感兴趣。所以我们应该用 WHERE 语句加 2 个判断条件。
SELECT * FROM Employee AS a, Employee AS b WHERE a.ManagerId = b.Id AND a.Salary > b.Salary ;
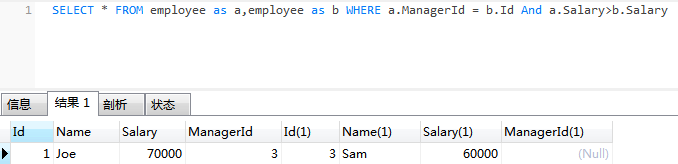
由于我们只需要输出雇员的名字,所以我们修改一下上面的代码,得到最终解法:
SELECT a.Name AS 'Employee' FROM Employee AS a, Employee AS b WHERE a.ManagerId = b.Id AND a.Salary > b.Salary ;
- 使用not null来剔除一些无用的记录。
- 下面是基于该思路的实现,执行效率要明显高于其他,如果在数据量大的情况下效果应该更明显;
select e1.Name as Employee
from Employee e1 ,Employee e2
where e1.ManagerId is not null and
e1.ManagerId = e2.Id
and e1.Salary > e2.Salary;方法 2:使用 JOIN 语句
实际上, JOIN 是一个更常用也更有效的将表连起来的办法,我们使用 ON 来指明条件。
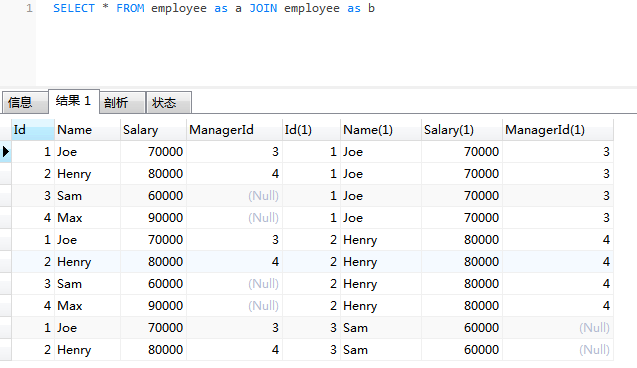
SELECT a.NAME AS Employee FROM Employee AS a JOIN Employee AS b ON a.ManagerId = b.Id AND a.Salary > b.Salary ;
9.部门工资最高的员工

考虑同部门最高工资的不止一个
连用in
SELECT Department.name AS 'Department', Employee.name AS 'Employee', Salary FROM Employee JOIN Department ON Employee.DepartmentId = Department.Id WHERE (Employee.DepartmentId , Salary) IN ( SELECT DepartmentId, MAX(Salary) FROM Employee GROUP BY DepartmentId ) ;
10.部门工资前三高的所有员工


11.删除重复邮箱
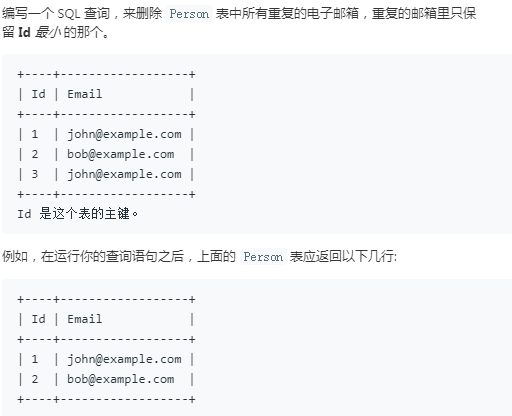
方法
DELETE p1 FROM Person p1, Person p2 WHERE p1.Email = p2.Email AND p1.Id > p2.Id
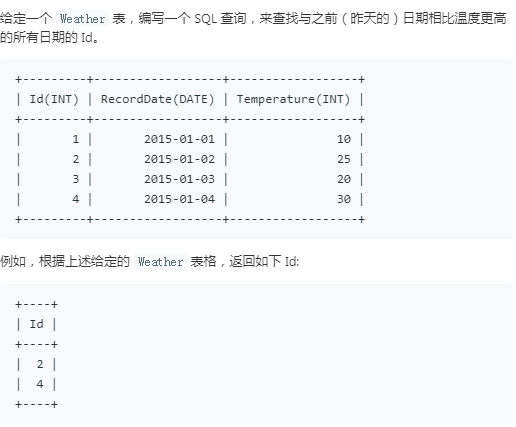
12.上升的温度
13.行程和用户
14.游戏玩法分析I
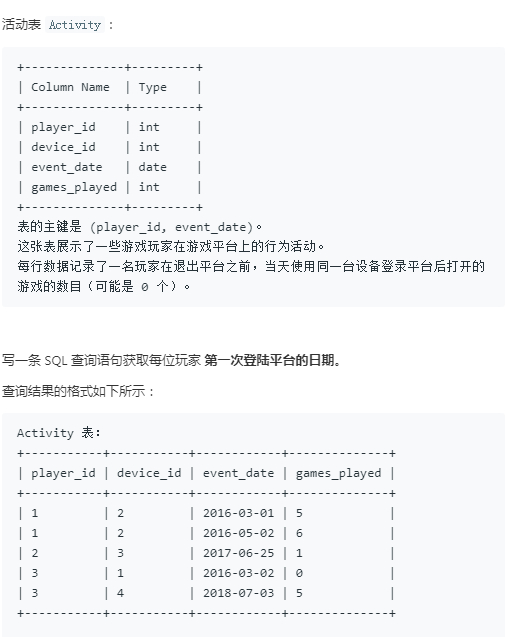
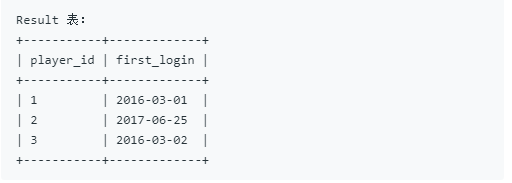
方法:min 函数对时间也是可行的。
select player_id, MIN(event_date) as first_login from Activity group by player_id;
15.游戏玩法分析Il

注意:
1.min方法只会返回结果一条记录,而其他字段没有指定,则默认取第一条
例如:


2.group by 分组,如果没有用聚合,默认取第一条
例如:


方法1
select player_id,device_id from activity where (player_id,event_date) in (select player_id,min(event_date) from activity group by player_id)
方法2
select a.player_id,a.device_id from Activity as a inner join (select player_id,min(event_date) as event_date from Activity group by player_id ) as b on a.event_date = b.event_date and a.player_id = b.player_id
16.游戏玩法分析Ill
17.游戏玩法分析IV
18.员工薪水中位数
19.至少有5名直接下属的经理
20.给定数字的频率查询中位数
21.当选者
22.员工奖金
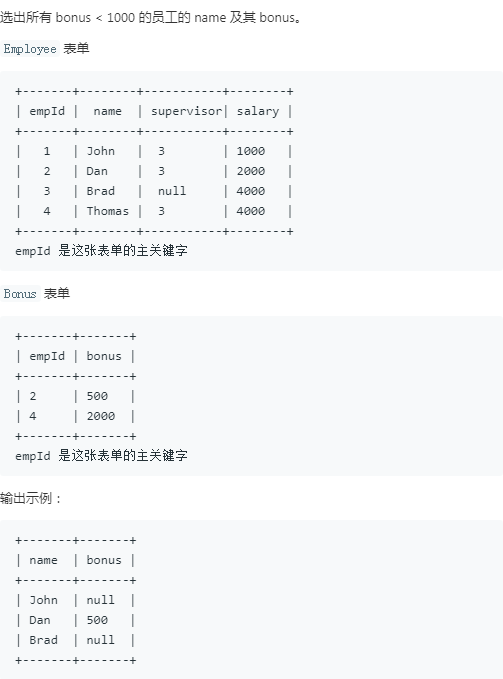
注意:
1.样例结果包含null
2.使用on 过滤条件可以在右边的empId为null 时仍然显示左表的数据, 但是bonus 为null 则不显示, 所以在where 中添加b.bonus避免bonus 为null 时不显示左表的数据.
方法1:
SELECT Employee.name, Bonus.bonus FROM Employee LEFT JOIN Bonus ON Employee.empid = Bonus.empid WHERE bonus < 1000 OR bonus IS NULL ;
方法2:
select name,bonus from employee left join bonus on employee.empId = bonus.empId where bonus is null or bonus <1000
方法3:
select e.`name`, b.bonus from Employee e left join Bonus b on e.empId = b.empId where ifnull(b.bonus, 0) < 1000
//ifnull(bonus,0)表示如果列bonus为空,则赋值为0.
23.查询回答率最高的问题
24.查询员工的累计薪水
25.统计各专业学生人数
26.寻找用户推荐人
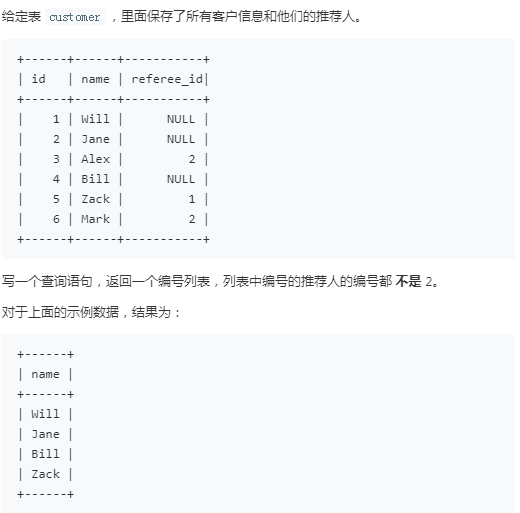
注意:null值不能与其他值进行比较,只能使用is null或is not null来进行判断
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 false,即 NULL = NULL 返回false 。
MySQL 中处理 NULL 使用 IS NULL 和 IS NOT NULL 运算符。
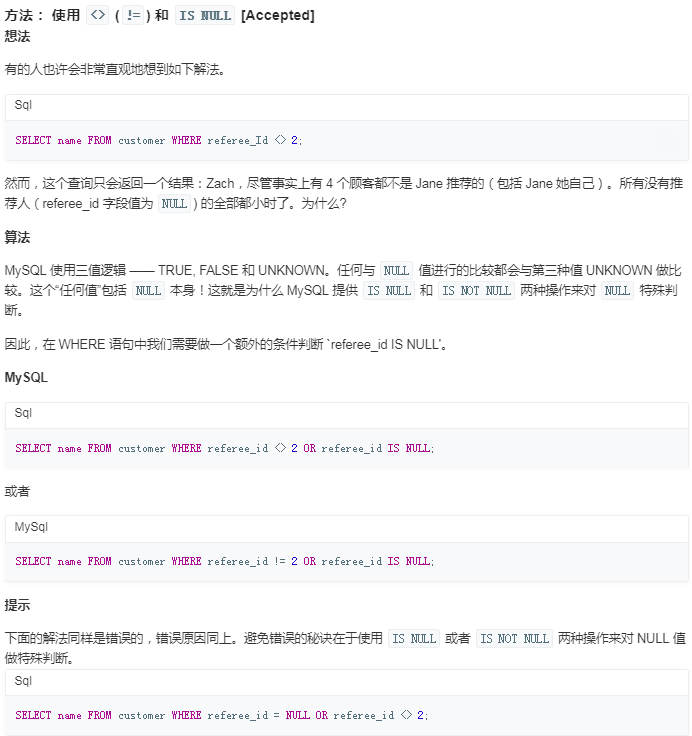
select name from customer where referee_id != 2 or referee_id is null
27.2016年的投资
28.订单最多的客户


SELECT customer_number FROM orders GROUP BY customer_number ORDER BY COUNT(*) DESC LIMIT 1
29.大的国家
30.超过5名学生的课
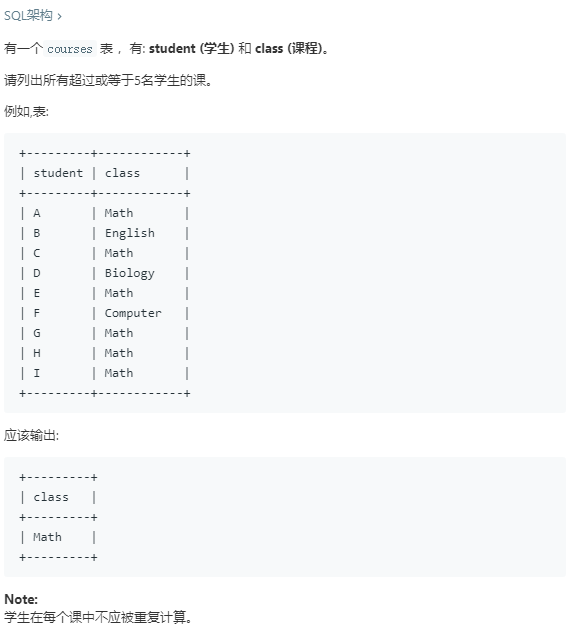

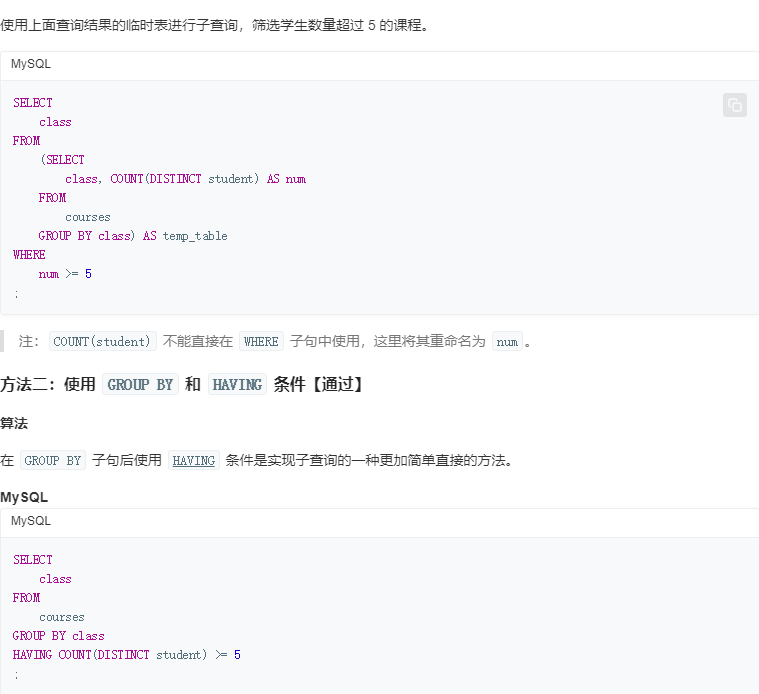
31.


32.体育馆的人流量
33.好友申请 II :谁有最多的好友
34.连续空余座位
35.销售员
36.树节点
37.判断三角形
38.平面上的最近距离
39.直线上的最近距离
40.二级关注者

方法1
select followee as follower ,count( distinct follower ) as num from follow where followee in (select distinct follower from follow ) group by followee
方法2
select f1.follower,count(distinct(f2.follower)) num from follow f1,follow f2 where f1.follower=f2.followee group by f1.follower