在某些场景的架构里,可能需要用到多个集群,我们把集群间的数据复制叫作镜像,Kafka 内置的跨集群复制工具叫作 MirrorMaker。
一、跨集群镜像的使用场景
区域集群和中心集群:有时候一个公司会有多个数据中心,该公司在每个城市都有一个数据中心,它们收集所在城市的供需信息,并调整商品价格。这些信息将会被镜像到一个中心集群上,业务分析员就可以在上面生成整个公司的收益报告。
冗余(DR):一个 Kafka 集群足以支撑所有的应用程序,不过你可能会担心集群因某些原因变得不可用,所以你希望有第二个 Kafka 集群,它与第一个集群有相同的数据,如果发生了紧急情况,可以将应用程序重定向到第二个集群上。
云迁移:有很多公司将它们的业务同时部署在本地数据中心和云端。
二、多集群架构
以下是在进行跨数据中心通信时需要考虑的一些问题。
- 高延迟:Kafka 集群之间的通信延迟随着集群间距离的增长而增加。
- 有限的带宽:单个数据中心的广域网带宽远比我们想象的要低得多,而且可用的带宽时刻在发生变化。另外,高延迟让如何利用这些带宽变得更加困难。
- 高成本:不管你是在本地还是在云端运行 Kafka,集群之间的通信都需要更高的成本。
在发生网络分区时,消费者无法从 Kafka 读取数据,数据会驻留在Kafka 里,直到通信恢复正常。因此,网络分区不会造成任何数据丢失。不过,因为带宽有限,如果一个数据中心的多个应用程序需要从另一个数据中心的 Kafka 服务器上读取数据,我们倾向于为每一个数据中心安装一个 Kafka 集群,并在这些集群间复制数据,而不是让不同的应用程序通过广域网访问数据。
1、Hub和 Spoke架构
这种架构适用于一个中心 Kafka 集群对应多个本地 Kafka 集群的情况。
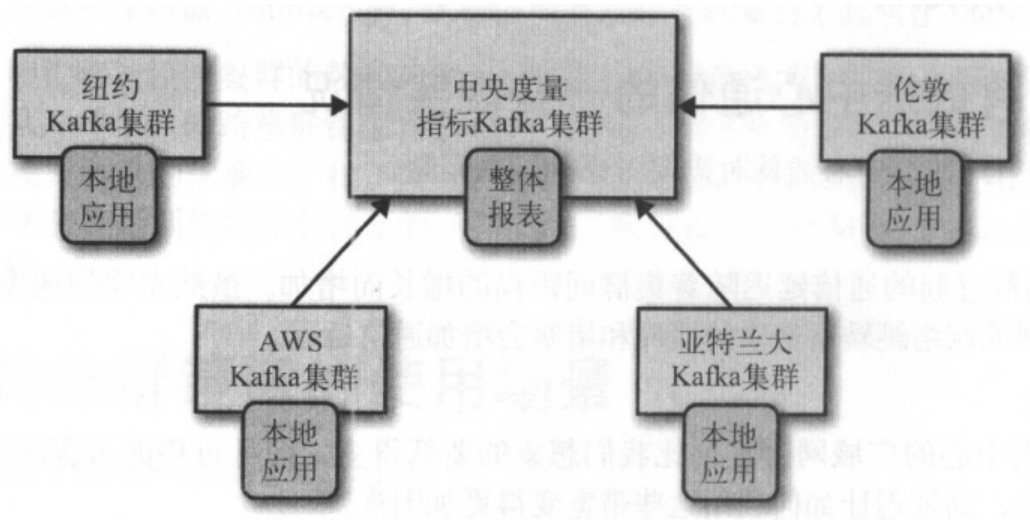
这种架构有一个简单的变种,如果只有一个本地集群,那么整个架构里就只剩下两个集群:一个首领和一个跟随者
这种架构的好处在于,数据只会在本地的数据中心生成,而且每个数据中心的数据只会被镜像到中央数据中心一次。只处理单个数据中心数据的应用程序可以被部署在本地数据中心里,而需要处理多个数据中心数据的应用程序则需要被部署在中央数据中心里。因为数据复制是单向的,而且消费者总是从同一个集群读取数据,所以这种架构易于部署、配置和监控。不足是一个数据中心的应用程序无法访问另一个数据中心的数据。
2、双活架构
当有两个或多个数据中心需要共享数据并且每个数据中心都可以生产和读取数据时,可以使用双活( Active-Active )架构。

这种架构的主要好处在于,它可以为就近的用户提供服务,具有性能上的优势,而且不会因为数据的可用性问题(在 Hub 和 Spoke 架构中就有这种问题)在功能方面作出牺牲。第二个好处是冗余和弹性。因为每个数据中心具备完整的功能, 一旦一个数据中心发生失效,就可以把用户重定向到另一个数据中心。这种重定向完全是网络的重定向,因此是一种最简单、最透明的失效备援方案。
这种架构的主要问题在于,如何在进行多个位置的数据异步读取和异步更新时避免冲突。比如镜像技术方面的问题一一如何确保同一个数据不会被无止境地来回镜像?而数据一致性方面的问题则更为关键。下面是可能遇到的问题。
- 如果用户向一个数据中心发送数据,同时从第二个数据中心读取数据,那么在用户读取数据之前,他发送的数据有可能还没有被镜像到第二个数据中心。因此,在使用这种架构时,开发人员经常会将用户“粘”在同一个数据中心上,以确保用户在大多数情况下使用的是同一个数据中心的数据(除非他们从远程进行连接或者数据中心不可用) 。
- 一个用户在一个数据中心订购了书 A ,而第二个数据中心几乎在同一时间收到了该用户订购书 B 的订单,在经过数据镜像之后,每个数据中心都包含了这两个事件。两个数据中心的应用程序需要知道如何处理这种情况。我们是否应该从中挑选一个作为“正确”的事件?又或者把两个都看成是正确的事件,将两本书都发给用 户,然后设立一个部门专门来处理退货问题? Amazon 就是使用这种方式来处理冲突的。
如果能够很好地处理在从多个位置异步读取数据和异步更新数据时发生的冲突问题,那么我们强烈建议使用这种架构。这种架构是我们所知道的最具伸缩性、弹性、灵活性和成本优势的解决方案。
双活镜像(特别是当数据中心的数量超过两个)的挑战之处在于,每两个数据中心之间都需要进行镜像,而且是双向的。如果有 5 个数据中心,那么就需要维护至少 20 个镜像进程,还有可能达到 40 个,因为为了高可用,每个进程都需要冗余 。
另外,我们还要避免循环镜像,相同的事件不能无止境地来回镜像。对于每一个“逻辑主题”,我们可以在每个数据中心里为它创建一个单独的主题,并确保不要从远程数据中心复制同名的主题。例如,对于逻辑主题“users”,我们在一个数据中心为其创建“SF.users”主题,在另一个数据中心为其创建“NYC.users”主题。镜像进程将 SF 的“ SF.users”镜像到 NYC ,同时将 NYC 的“NYC.users”镜像到 SF。这样一来,每一个事件只会被镜像一次,不过在经过镜像之后,每个数据中心同时拥有了 SF.users 和 NYC.users 这两个主题,也就是说,每个数据中心都拥有相同的用户数据。消费者如果要读取所有的用户数据,就需要以“*.users”的方式订阅主题。我们也可以把这种方式理解为数据中心的命名空间,比如在这个例子里,NYC 和 SF 就是命名空间 。
3、主备架构
有时候,使用多个集群只是为了达到灾备的目的。你可能在同一个数据中心安装了两个集群,它们包含相同的数据,平常只使用其中的一个。当提供服务的集群完全不可用时,就可以使用第二个集群。

这种架构的好处是易于实现,而且可以被用于任何一种场景。你可以安装第二个集群,然后使用镜像进程将第一个集群的数据完整镜像到第二个集群上,不需要担心数据的访问和冲突问题,也不需要担心它会带来像其他架构那样的复杂性。
这种架构的不足在于,它浪费了一个集群。Kafka 集群间的失效备援比我们想象的要难得多。从目前的情况来看,要实现不丢失数据或无重复数据的 Kafka 集群失效备援是不可能的。
1)数据丢失和不一致性
因为 Kafka 的各种镜像解决方案都是异步的,所以灾备集群总是无法及时地获取主集群的最新数据。如果你的Kafka集群每秒钟可以处理100万个消息,而在主集群和灾备集群之间有5ms的延迟,那么在最好的情况下,灾备集群每秒钟会有5000个消息的延迟,所以,不在计划内的失效备援会造成数据的丢失。
2)失效备援之后的起始偏移量
在切换到灾备集群的过程中,最具挑战性的事情莫过于如何让应用程序知道该从什么地方开始继续处理数据。Kafka 消费者有一个配置选项,用于指定在没有上一个提交偏移量的情况下该作何处理。消费者要么从分区的起始位置开始读取数据,要么从分区的末尾开始读取数据。
如果使用新的 Kafka 消费者( 0.9 或以上版本),消费者会把偏移量提交到一个 叫 作__consumer_offsets 的主题上。如果对这个主题进行了镜像,那么当消费者开始读取灾备集群的数据时,它们就可以从原先的偏移量位置开始处理数据。就算在主题创建之后立即开始镜像,让主集群和灾备集群的主题偏移量都从 0 开始,生产者在后续进行重试时仍然会造成偏移量的偏离。简而言之,目前的 Kafka 镜像解决方案无法为主集群和灾备集群保留偏移量。
3)基于时间的失效备援
如果使用的是新版本( 0.10.0 及以上版本)的 Kafka 消费者, 每个消息里都包含了一个时间戳,这个时间戳指明了消息发送给 Kafka 的时间。 在更新版本的 Kafka (0.10.1.0及以上版本)里, broker 提供了一个索引和一个 API ,用于根据时间戳查找偏移量。于是,假设你正在进行失效备援,并且知道失效事件发生在凌晨 4:05 ,那么就可以让消费者从 4:03 的位置开始处理数据。在两分钟的时间差里会存在一些重复数据,不过这种方式仍然比其他方案要好得多 。
问题是,如何让消费者从凌晨 4:03 的位置开始处理数据呢?可以让应用程序来完成这件事情。 我们为用户提供一个配置参数 ,用于指定从什么时间点开始处理数据。如果用户指定了时间,应用程序可以通过新的 API 获取指定时间的偏移量,然后从这个位置开始处理数据。
4)在失效备援之后
假设失效备援进行得很顺利,灾备集群也运行得很正常,现在需要对主集群做一些改动,比如把它变成灾备集群。
如果能够通过简单地改变镜像进程的方向,让它将数据从新的主集群镜像到旧的主集群上面, 事情就完美了 !不过,这里还存在两个问题。
- 怎么知道该从哪里开始镜像?我们同样需要解决与镜像程序里的消费者相关的问题。而且不要忘了,所有的解决方案都有可能出现重复数据或者丢失数据,或者两者兼有。
- 之前讨论过,旧的主集群可能会有一些数据没有被镜像到灾备集群上,如果在这个时候把新的数据镜像回来,那么历史遗留数据还会继续存在,两个集群的数据就会出现不一致 。
基于上述的考虑,最简单的解决方案是清理旧的主集群,删掉所有的数据和偏移量,然后从新的主集群上把数据镜像回来,这样可以保证两个集群的数据是一致的 。
三、Kafka的 MirrorMaker
Kafka 提供了一个简单的工具,用于在两个数据中心之间镜像数据。这个工具叫MirrorMaker,它包含了一组消费者(因为历史原因,它们在 MirrorMaker 文档里被称为流),这些消费者属于同一个群组,并从主题上读取数据。每个 MirrorMaker 进程都有一个单独的生产者。
镜像过程很简单:MirrorMaker 为每个消费者分配一个线程,消费者从源集群的主题和分区上读取数据,然后通过公共生产者将数据发送到目标集群上。默认情况下,消费者每 60 秒通知生产者发送所有的数据到 Kafka,并等待 Kafka的确认 。 然后消费者再通知源集群提交这些事件相应的偏移量。这样可以保证不丢失数据(在源集群提交偏移量之前, Kafka 对消息进行了确认),而且如果 MirrorMaker 进程发生崩溃,最多只会出现 60 秒的重复数据。
