Kafka 一般被认为是一个强大的消息总线,可以传递事件流,但没有处理和转换事件的能力。 Kafka 可靠的传递能力让它成为流式处理系统完美的数据来源。很多基于 Kafka 构建的流式处理系统都将 Kafka 作为唯一可靠的数据来源,如 Apache Storm 、 Apache Spark Streaming 、 Apache Flink 、 Apache Samza 等。
从0.10.0版本开始,kafka不仅为每一个流行的流式处理框架提供了可靠的数据来源,还提供了一个强大的流式处理类库,并将其作为客户端类库的一部分,这样,开发人员就可以在应用程序里读取、处理和生成事件,而不需要再依赖外部的处理框架。
一、流式处理
1、数据流(也被称为“事件流”或“流数据”)
数据流是无边界数据集的抽象表示,无边界意味着无限和持续增长。如果事件流的定义里没有提到事件所包含的数据和每秒钟的事件数量,那么它就变得毫无意义。
事件流模型的一些属性:
- 事件流是有序的:事件的发生总是有个先后顺序。
- 不可变的数据记录:事件一旦发生,就不能被改变。
- 事件流是可重播的:这是事件流非常有价值的一个属性。可以借助 Kafka 来捕捉和重播事件流。
2、流式处理
三种范式比较:
- 请求与响应:这是延迟最小的一种范式,响应时间处于亚毫秒到毫秒之间,而且响应时间一般非常稳定。这种处理模式一般是阻塞的,应用程序向处理系统发出请求,然后等待响应。在数据库领域,这种范式就是线上交易处理 ( OLTP)。
- 批处理:这种范式具有高延迟和高吞吐量的特点。处理系统按照设定的时间启动处理进程,比如每天的下午两点开始启动,每小时启动一次等。它读取所有的输入数据(从上一次执行之后的所有可用数据,或者从月初开始的所有数据等),输出结果,然后等待下一次启动。
- 流式处理:这种范式介于上述两者之间。大部分的业务不要求亚毫秒级的响应,不过也接受不了要等到第二天才知道结果。流式处理是指实时地处理一个或多个事件流。流的定义不依赖任何一个特定的框架、 API 或特性。只要持续地从一个无边界的数据集读取数据,然后对它们进行处理并生成结果,那就是在进行流式处理。重点是,整个处理过程必须是持续的。
3、时间窗口
大部分针对流的操作都是基于时间窗口的,比如移动平均数、 一周内销量最好的产品、系统的 99 百分位,计算股价的 5 分钟移动平均数等。两个流的合并操作也是基于时间窗口的,我们会合并发生在相同时间片段上的事件。
- 窗口的大小。是基于 5 分钟进行平均,还是 15 分钟,或者一天。窗口越小,就能越快地发现变更,不过噪声也越多。窗口越大,变更就越平滑,不过延迟也越严重,如果价格涨了,需要更长的时间才能看出来。
- 窗口移动的频率(“移动间隔”)。 5 分钟的平均数可以每分钟变化一次,或者每秒钟变化一次,或者每当有新事件到达时发生变化。如果“移动间隔”与窗口大小相等,这种情况被称为“滚动窗口”。如果窗口随着每一条记录移动,这种情况被称为“滑动窗口”。
- 窗口的可更新时间多长。假设计算了 00:00 到 00:05 之间的移动平均数, 一个小时之后又得到了一些“事件时间”是 00:02 的事件,那么需要更新 00:00 到 00:05 这个窗口的结果吗?或者就这么算了?理想情况下,可以定义一个时间段,在这个时间段内, 事件可以被添加到与它们相应的时间片段里。如果事件处于 4 个小时以内,那么就更新它们 ,否则就忽略它们。
二、流式处理的设计模式
1、单个事件处理
处理单个事件是流式处理最基本的模式。这个模式也叫 map 或 filter 模式,因为它经常被用于过滤无用的事件或者用于转换事件( map 这个术语是从 Map-Reduce 模式中来的, map阶段转换事件, reduce 阶段聚合转换过的事件)。在这种模式下,应用程序读取流中的事件 ,修改它们,然后把事件生成到另一个流上。

2、使用本地状态
大部分流式处理应用程序关心的是如何聚合信息,特别是基于时间窗口进行聚合。例如,找出每天最低和最高的股票交易价格并计算移动平均数。要实现这些聚合操作,需要维护流的状态。在本例中,为了计算每天的最小价格和平均价格,需要将最小值和最大值保存下来,并将它们与每一个新值进行对比。这些操作可以通过本地状态(而不是共享状态)来实现,可以使用 Kafka 分区器来确保具有相同股票代码的事件总是被写入相同的分区。 应用程序的每个实例从分配给它们的分区上获取事件,应用程序的每一个实例都可以维护一个股票代码子集的状态。

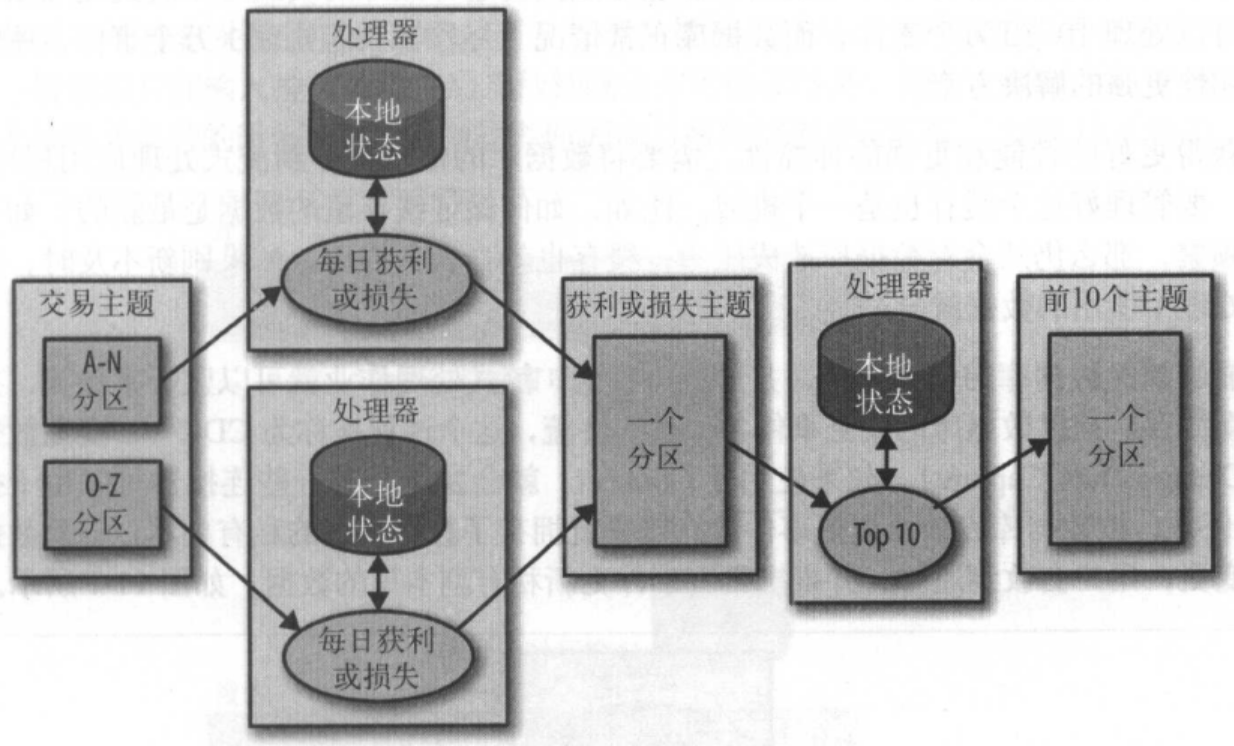
3、多阶段处理和重分区
本地状态对按组聚合操作起到很大的作用。但如果需要使用所有可用的信息来获得一个结果呢? 例如,假设要发布每天的“前 10 支”股票,这 10 支股票需要从每天的交易股票中挑选出来。我们需要一个两阶段解决方案。首先,计算每支股票当天的涨跌,这个可以在每个实例上进行。然后将结果写到一个包含了单个分区的新主题上。另一个单独的应用实例读取这个分区, 找出当天的前 10 支股票。新主题只包含了每支股票的慨要信息 ,比其他包含交易信息的主题要小很多,所以流量很小,使用单个应用实例就足以应付。
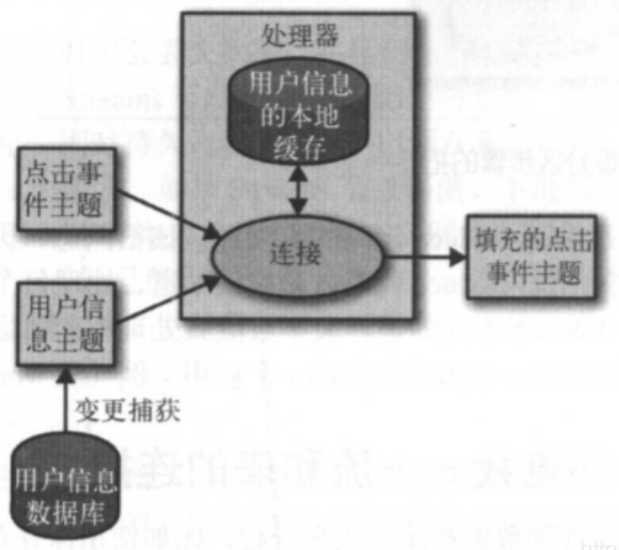
4、使用外部查找一一流和表的连接
有时候,流式处理需要将外部数据和流集成在一起,比如使用保存在外部数据库里的规则来验证事务,或者将用户信息填充到点击事件当中。很明显,为了使用外部查找来实现数据填充,可以这样做:对于事件流里的每一个点击事件,从用户信息表里查找相关的用户信息,从中抽取用户的年龄和性别信息,把它们包含在点击事件里,然后将事件发布到另一个主题上,这种方式最大的问题在于,外部查找会带来严重的延迟,一般在 5~15ms 之间,外部数据存储也无法接受这种额外的负载一一流式处理系统每秒钟可以处理 10~50 万个事件,而数据库正常情况下每秒钟只能处理 1 万个事件,所以需要伸缩性更强的解决方案。
为了获得更好的性能和更强的伸缩性,需要将数据库的信息缓存到流式处理应用程序里,能够捕捉数据库的变更事件,并形成事件流,流式处理作业就可以监听事件流,并及时更新缓存。
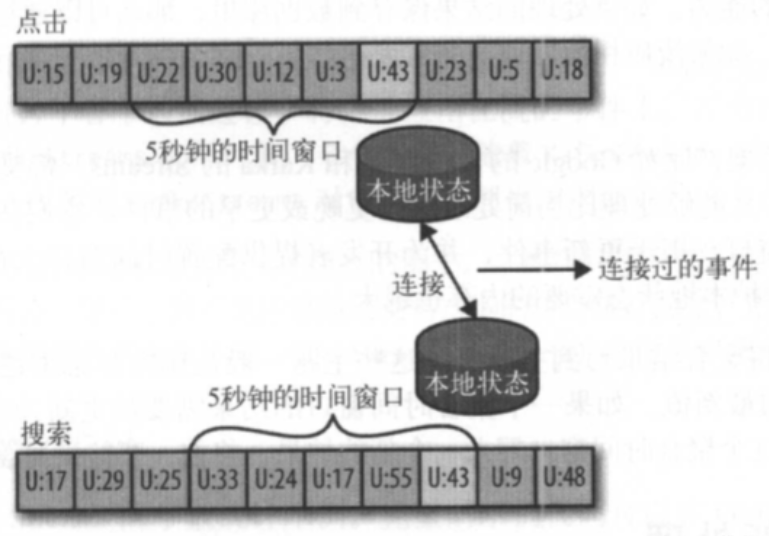
5、流与流的连接
如果要连接两个流,那么就是在连接所有的历史事件一一将两个流里具有相同键和发生在相同时间窗口内的事件匹配起来。这就是为什么流和流的连接也叫作基于时间窗口的连接。
三、Kafka Streams的架构概览
1、构建拓扑
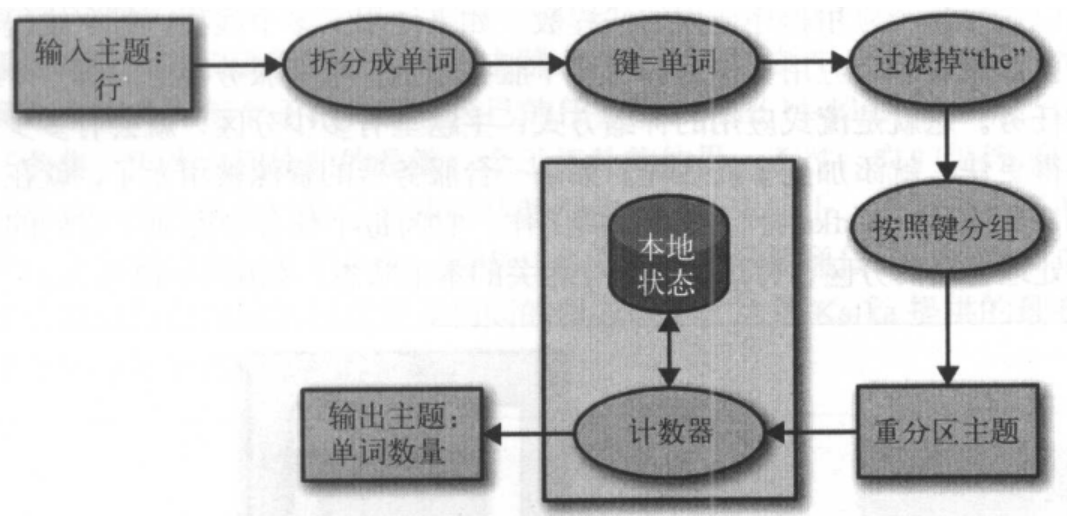
每个流式应用程序至少会实现和执行一个拓扑。拓扑(在其他流式处理框架里叫作DAG,即有向无环图)是一个操作和变换的集合,每个事件从输入到输出都会流经它。拓扑是由处理器组成的,这些处理器是拓扑图里的节点(用椭圆表示)。大部分处理器都实现了一个数据操作一一过滤、映射、聚合等。数据源处理器从主题上读取数据,并传给其他组件,而数据池处理器从上一个处理器接收数据,并将它们生成到主题上。拓扑总是从一个或多个数据源处理器开始,并以一个或多个数据池处理器结束。
2、对拓扑进行伸缩
Streams 通过在单个实例里运行多个线程和在分布式应用实例间进行负载均衡来实现伸缩。用户可以在一台机器上运行 Streams 应用,并开启多个线程,也可以在多台机器上运行Streams 应用。不管采用何种方式,所有的活动线程将会均衡地处理工作负载。
Streams 引擎将拓扑拆分成多个子任务来并行执行。拆分成多少个任务取决于 Streams 引擎,同时也取决于主题的分区数量。每个任务负责一些分区:任务会订阅这些分区,并从分区读取事件数据,在将结果写到数据池之前,在每个事件上执行所有的处理步骤。这些任务是 Streams 引擎最基本的并行单元,因为每个任务可以彼此独立地执行。
1)运行相同拓扑的两个任务——每个读取主题的一个分区
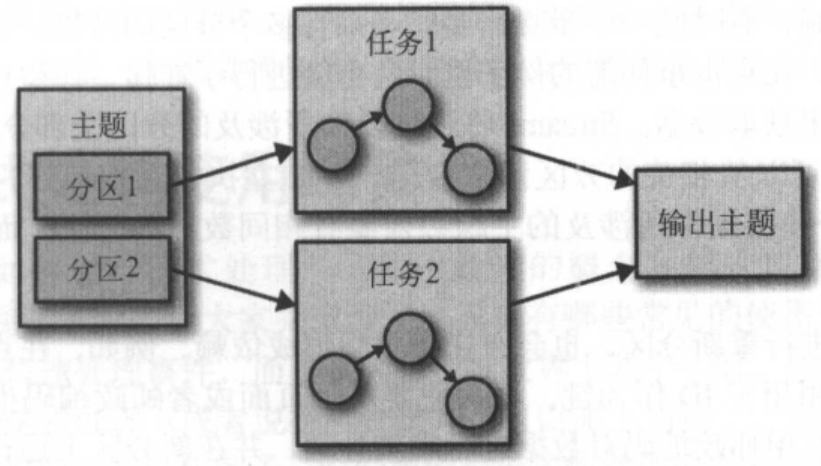
2)处理任务可以运行在多个线程和多个服务器上
开发人员可以选择每个应用程序使用的线程数。如果使用了多个线程,每个线程将会执行一部分任务。如果有多个应用实例运行在多个服务器上,每个服务器上的每一个线程都会执行不同的任务。这就是流式应用的伸缩方式:主题里有多少分区,就会有多少任务。如果想要处理得更快,就添加更多的线程。如果一台服务器的资源被用光了,就在另一台服务器上启动应用实例。Kafka 会自动地协调工作,它为每个任务分配属于它们的分区,每个任务独自处理自己的分区,并维护与聚合相关的本地状态。
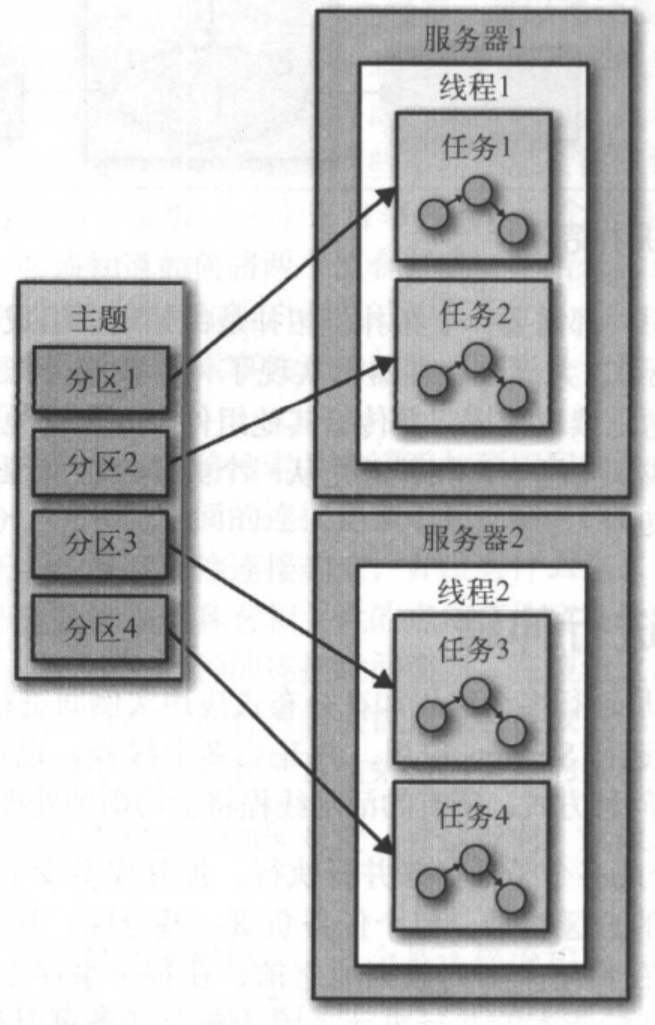
3)处理主题分区事件的两组任务
有时候一个步骤需要处理来自多个分区的结果,这样就会在任务之间形成依赖。例如,在点击事件流的例子里对两个流进行了连接,在生成结果之前,需要从每一个流的分区里获取数据 。Streams 将连接操作所涉及的分区全部分配给相同的任务,这样,这个任务就可以从相关的分区读取数据,井独立执行连接操作。这也就是为什么Streams 要求同一个连接操作所涉及的主题必须要有相同数目的分区,而且要基于连接所使用的键进行分区。如果应用程序需要进行重新分区,也会在任务之间形成依赖。
