C语言是一个简单的语言。用户针对每一个函数,只能设置一个唯一的函数签名。但是C++而言,就给了我们很多的灵活性:
- 你可以将多个函数设置为相同的名字(overloading)
- 你可以使用内置操作符重载(built-in operators),例如
+以及== - 你可以使用函数模版(function templates)
- 你也可以使用命名空间(namespaces)避免命名冲突
针对C++提供的这些特性,你可以实现str1 + str2返回两个字符串的拼接;同样,你也可以在一对2D点操作的基础上,实现3D点对的操作,重载dot(a, b)来处理不同的类型。你可以写一堆的数组类,并且实现一个sort函数模版,在所有的类上都适用。
但是,在我们充分利用这些特性时,往往很容易将事情推向错误的一面。在某些情况下,编译器在接受我们的代码时,会给出如下的报错:
error C2666: 'String::operator ==': 2 overloads have similar conversions
note: could be 'bool String::operator ==(const String &) const'
note: or 'built-in C++ operator==(const char *, const char *)'
note: while trying to match the argument list '(const String, const char *)'
和很多C++程序员一样,我也经常苦恼与这样的问题。每次出现这样的报错,我总是大脑一片空白,在网上查询更好的理解,然后修改代码知道程序可以运行。在最近的一些项目开发中,我再次被这样的问题阻扰;它变得和我认知中这类问题的理解完全对立,我因此意识到我对于这类问题的理解还不够充分,仍有缺失。
幸运的是,如今是2021年了,网络信息如此发达;在此,我尤其感谢cppreference.com,如今我知道我对于此类问题缺失的理解:一个隐藏算法的清晰全貌,用来在编译时的每一次函数调用。
这也是给定编译器,一个函数调用表达式,准确计算出哪一个函数被调用:

上图这些步骤隐藏在C++标准的背后,每一个C++编译器都要遵循这些规则,并且这一系列的函数调用所涉及的程序表达式计算,都发生在编译时。这也是C++能够支持上面种种特性的原因。
我个人猜想,上图整个算法的意图就是----实施程序员所希望的操作,并且在某种程度上,它是成功的。作为程序员,在大部分时间和开发场景上,是完全可以忽略这些背后的算法;但是,如果涉及开发一个库,你最好了解这些规则。
所以,让我们从入门到放弃(开玩笑)的了解这些背后的算法机制,对于很多有经验的C++程序员,本文聊到的内容都是相当熟悉的东西。此外,我也希望抛砖引玉,给大家带来一些新颖的C++子话题,例如:参数独立查询和SFINAE,但是我们不会特别的深入探讨这些字话题。因此,本文的定位,是给大家带来C++函数调用在编译时的一些列操作策略。
命名查询
我们的旅途始于一个函数调用表达式,例如,采用这个表达式blast(ast, 100),这个表达式很明显是调用一个函数叫做blast,但是实际是哪一个呢?
namespace galaxy {
struct Asteroid {
float radius = 12;
};
void blast(Asteroid* ast, float force);
}
struct Target {
galaxy::Asteroid* ast;
Target(galaxy::Asteroid* ast) : ast{ast} {}
operator galaxy::Asteroid*() const { return ast; }
};
bool blast(Target target);
template <typename T> void blast(T* obj, float force);
void play(galaxy::Asteroid* ast) {
blast(ast, 100);
}
回答这个问题的第一步叫做:命名查询。在这一步,编译器在编译当下此时此刻,查询出所有具有所给定查询名称的函数、函数模版和其他可被引用的标识符,如下图。

如上述流图所示,有三个主要被查询的名称类型,每一个都有各自的规则。
- 成员名称查询:发生在使用
.或者->的情况下,例如:foo->bar。这一类的查询发生在类内局部成员中。 - 有修饰的名称查询:发生在一个名称有
::符号进行修饰,例如:std::sort。这一类的名称是确定的,只要到::符号的左边范围内去查询右边的名称成员。 - 无修饰的名称查询:当编译器看到一个没有修饰的名称,例如:
blast。编译器在此时的上下文中查询各种范围内的匹配名称,具体也有详细的查询规则。
我们的例子中,给出一个没有修饰的名称。那么,当运算一个函数调用表达式,从而查询一个名称操作时,编译器就可能找到多个声明,我们把这些多个声明都叫做候选。上述事例中,编译器可以找到三个候选:

上图中,圈出的第一个候选需要额外关注,因为它表明一个简单的C++特性,也就是:参数依赖查询----ADL。正常情况下,你不希望这个函数作为候选,因为它是声明在galaxy命名空间,而实际所调用的函数来自于galaxy外部的命名空间。并且,程序中没有``using namespace galaxy```指令使得此命名空间内的函数可见,所以,为什么这样的候选成立?
原因就是, 任何时刻,当你使用一个没有修饰符的名称在一个函数调用过程中,并且这个名称不是引用一个类成员,此时ADL引入,可以更加广泛的查询符合的候选。特别的,在一般使用情况下,编译器会在参数类型的命名空间中查询合适的候选函数,也就符合“参数依赖查询”的意思。

完整的ADL规则,有着更加详细的差异描述,但是,可以确定的是,ADL只适用于无修饰的名称。对于有修饰的名称,也就是在单个范围内查询,那么使用ADL规则是没有意义的。ADL同样适用于重载内置操作符,例如:+和==。有趣的是,很多情况下,成员名称查询可以找很多未修饰的名称候选,详细看这篇博文。
函数模版的特殊具柄
通过名称查询的一些候选是函数,另外则是函数模版。对于函数模版存在一个问题:我们无法调用它们,我们只能调用函数。因此,在名称查询后,编译器遍历每一个候选,并试图将每一个函数模版转为函数。
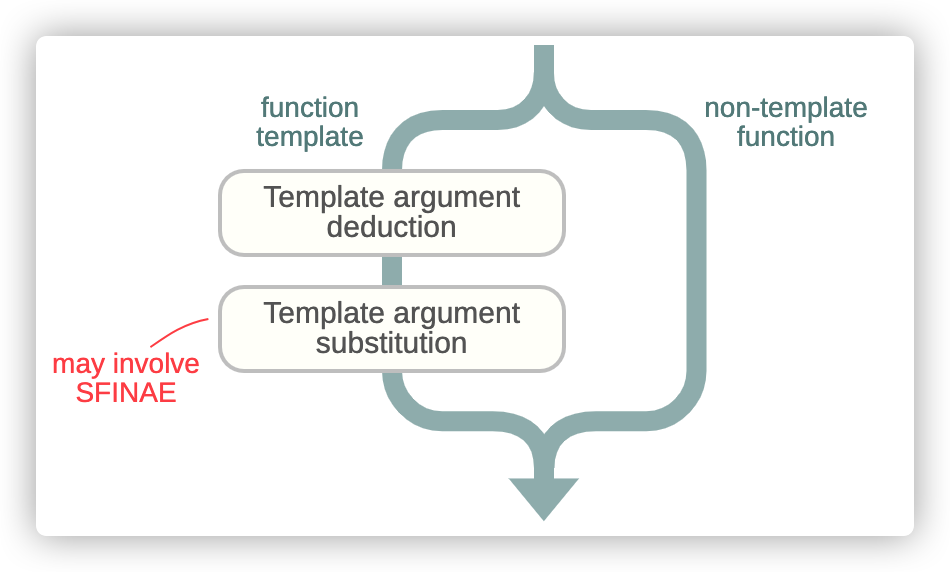
上面,我们给出的示例中,存在一个候选就是函数模版:
template <typename T> void blast(T* obj, float force);
这个函数模版仅有一个模版参数T,因此,当调用者blast(ast, 100)没有指定任何模版参数,但是,编译器又必须将函数模版转为函数,所以需要搞清楚类型T,这也就是模版参数推理。在这一步,编译器将由调用者传入的函数参数和函数模版所期望的函数参数所对比;如果任何未指定的模版参数被引用了,例如:T,那么,编译器就尝试使用左边的信息去推理它。
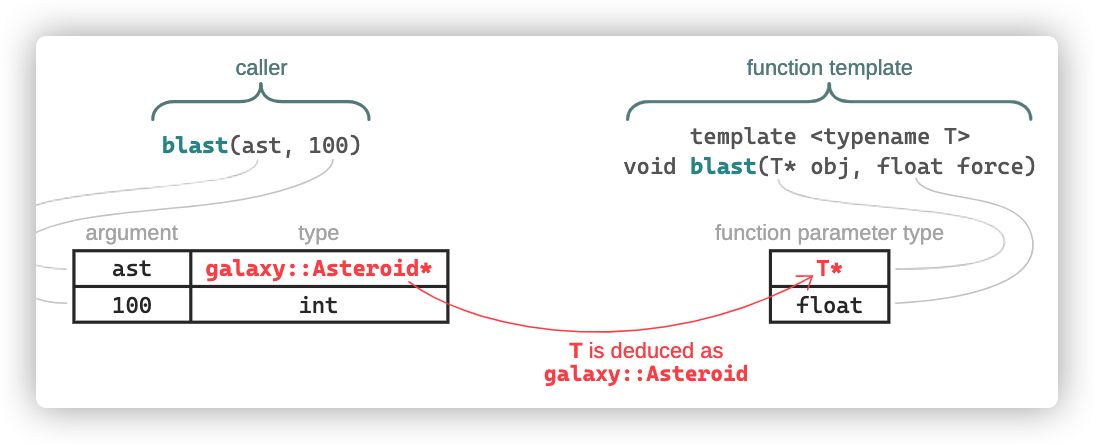
上图中,编译器将T推理为galaxy::Asteroid,因为只有这样做,可以将多一个函数参数T*匹配到参数ast。模版参数推理规则总结,详细的介绍了相关内容。但是,在一些情况下,如果模版推理不能有效进行,也就是编译器找不到合适的模版参数匹配到调用者参数类型,那么函数模版就被从候选者列表中移除。
在候选列表中的所有函数模版生命周期到这一步结束:模版参数替换。在这一步,编译器接受函数模版声明,并用对应的模版参数替换掉每个模版参数出现的地方。在我们的例子中,模版参数T被它所推理的galaxy::Asteroid类型替换掉,如果这一步成功实施,我们最终可以获得能够被调用的函数签名----而不在是函数模版。

当然,存在一些情况下,模版参数替换失败。假设下面的情况,相同的函数模版接受一个第三个参数:
template <typename T> void blast(T* obj, float force, typename T::units mass=5000);
那么,编译器会使用galaxy::Asteroid来替换T::units中的T。而结果表达式就是,galaxy::Asteroid::Units,这样是无效的,因为galaxy::Asteroid没有一个叫做Units的成员,因此,此次的模版参数替换失败。
当模版参数替换失败,那么函数模版就被移除出候选列表;在C++历史中的某些时刻,人们意识到这样的特性是可以挖掘利用的,这样的发现导致了整个模版元编程技术的出现,常被称作SFINAE(substitution failure is not an error)。
重载解析
在这个阶段,通过名称查询的所有函数模版都已经消失,我们获得了一组干净、漂亮的候选函数,它们也同样被称为重载组。下面就是我们例子中的重载组:

接下来两步就是缩小这个集合,通过决定哪个候选函数可以保留,也就是说,哪一个候选函数可以处理函数调用。
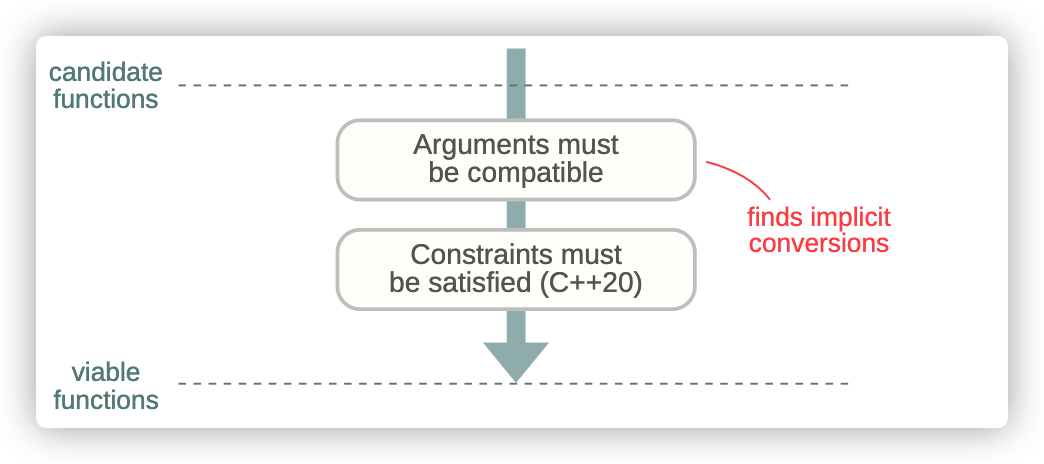
或许,最显而易见的要求就是,参数必须匹配;这也就是说,一个保留函数,应该能够接受调用者的参数。如果,调用者的参数类型和实际的函数参数类型不匹配,它至少是可以实现隐式转换每个参数到与之要对应的参数类型。让我们看看给出的例子中的候选函数,是否有与之匹配的参数:

候选1
调用者第一个参数类型是galaxy::Asteroid*,可以实现完全匹配。调用者第二个参数类型是int,可以通过隐式转化实现到float类型的转化,因此,候选1的参数是匹配的。
候选2
调用者第一个参数类型是galaxy::Asteroid*,可以隐式的转为函数参数类型Taeget,因为Target有一个转化构造函数,可以接受galaxy::Asteroid*类型的参数。然而,调用者传入了两个参数,候选2只可以接受一个参数,可以候选2被剔除。
候选3
候选3的参数类型等同于候选1,所以,它也是匹配的。
最后的决策
在这一步,我们的例子只剩下最后两个保留的函数:

实际上,如果上图两个候选中,任意一个被保留下来,那么它就是最后执行函数调用的具柄。但是由于最后还有两个候选,编译器必须在多个候选中进一步进行操作:它必须决定哪一个是更好的候选函数。为了成为最好的候选函数,它们当中必须有一个更加的匹配,这就是由决胜者规则序列决定的:

下面给出三条决胜者规则:
首要决胜者:参数最匹配者胜出
C++强调了调用者参数类型和函数参数类型匹配程度的重要性,宽泛来说,编译器倾向选择函数需要较少隐式类型转换的的候选函数。这条规则决定了我们在使用std::vector中的const和non-const版本的选择。
在我们的例子中,由于两个候选函数的参数类型都一致,所以,第一条规则都满足。
第二决胜者:非模版参数胜出
如果第一条规则没有决出胜负,那么C++倾向于调用非模版函数。在我们的例子中,由于候选1是非模版函数,而候选2是模版函数,因此,我们的最优函数就是:
void galaxy::blast(galaxy::Asteroid* ast, float force)
值得重申的是,如果有一个模版函数在参数类型上更加匹配,那么该模版函数胜出,也就是说,决胜者规则的优先级是按顺序递降的。
第三决胜者:更加特定的模版胜出
我们的例子中,最优的候选函数已经获得,但是如果没有得的话,那么我们就要参考第三决胜者规则。这条规则中,C++倾向于调用“更加特定”的模版函数,例如,考虑下面两个函数模版:
template <typename T> void blast(T obj, float force);
template <typename T> void blast(T* obj, float force);
在进行模版参数推理步骤时,第一个函数模版接受任意类型作为它的第一个参数,而第二个函数模版仅仅接受指针类型。因此,第二个函数模版被称为更加特定。因此,编译器倾向于选择第二个候选函数作为最优函数。
函数调用解析之后
在此时,编译器已经准确知道了哪一个函数应该作为表达式blast(ast, 100)的句柄了。在许多例子中,虽然,编译器在解析函数调用后还有很多工作要完成:
- 如果被调用的函数是一个类成员,编译器必须检查类成员的访问修饰符,来判断是否有权访问调用者。
- 如果被调用函数是一个模版函数,编译器必须实例化这个模版函数。
- 如果被调用的函数是虚函数,编译器需要生成特殊的机器指令,实现在运行时保证重载准确调用。