calico的核心组件
(1)Felix:Calico的客户端,跑在每台node节点上,主要负责配置路由及ACLs等信息来确保各pod之间的连通状态
(2)etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性;
(3)BGPClient:主要负责把Felix写入kernel的路由信息分发到当前Calico网络,确保节点间通信的有效性;
(4)BGPRoute Reflector(BIRD,BGP路由反射器):大规模部署时使用,通过一个或者多个BGPRoute Reflector来完成集中式的路由分发。
calico原理
calico是一个纯三层的虚拟网络,它没有复用docker的docker0网桥,而是自己实现的, calico网络不对数据包进行额外封装,不需要NAT和端口映射,扩展性和性能都很好。Calico网络提供了DockerDNS服务, 容器之间可以通过hostname访问,Calico在每一个计算节点利用LinuxKernel实现了一个高效的vRouter(虚拟路由)来负责数据转发,它会为每个容器分配一个ip,每个节点都是路由,把不同host的容器连接起来,从而实现跨主机间容器通信。而每个vRouter通过BGP协议(边界网关协议)负责把自己节点的路由信息向整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGProute reflector来完成;Calico基于iptables还提供了丰富而灵活的网络策略,保证通过各个节点上的ACLs来提供多租户隔离、安全组以及其他可达性限制等功能。
Calico网络模式
1.IPIP
把一个IP数据包又套在一个IP包里,即把IP层封装到IP层的一个 tunnel,它的作用其实基本上就相当于一个基于IP层的网桥,一般来说,普通的网桥是基于mac层的,根本不需要IP,而这个ipip则是通过两端的路由做一个tunnel,把两个本来不通的网络通过点对点连接起来。
2.BGP
边界网关协议(BorderGateway Protocol, BGP)是互联网上一个核心的去中心化的自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而是基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议,通俗的说就是将接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP;
BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
calico的ip-ip网络模式
1.ip-ip模式的特点
calico以ipip模式部署完毕后,node上会有一个tunl0的网卡设备,这是ipip做隧道封装用的,也是一种overlay模式的网络。当我们把节点下线,calico容器都停止后,这个设备依然还在,执行 rmmodipip命令可以将它删除。
2.开启/禁用ip-ip
官方提供的calico.yaml模板里,默认打开了ip-ip功能,该功能会在node上创建一个设备tunl0,容器的网络数据会经过该设备被封装一个ip头再转发。这里,calico.yaml中通过修改calico-node的环境变量:CALICO_IPV4POOL_IPIP来实现ipip功能的开关:默认是Always,表示开启;Off表示关闭ipip;calico.yaml文件的部分内容参考备注。
3.演示calico的ipip模式的ping包走向
1)测试环境
master1:172.16.0.1 node1:172.16.0.4 node2:172.16.0.5
master1节点执行如下命令,查看宿主机创建的pod有哪些
master1节点的窗口1:
kubectl get pods -o wide 显示如下

用node1节点上的pod(nfs-provisioner-8d6dbc584-cdfxz)ping node2节点上的pod(fierce-body-redis-metrics-6cf79f9d64-v6zs2)
master1节点操作:
kubectl exec -it nfs-provisioner-8d6dbc584-cdfxz -- /bin/sh
#ping 10.244.4.188
2)ping包的旅程
查看node1节点pod上的路由信息:
master1节点新打开一个窗口2:
kubectl exec -it nfs-provisioner-8d6dbc584-cdfxz -- /bin/sh
#route -n

根据路由信息,ping 10.244.4.188,会匹配到第一条路由,第一条的路由意思是:去往任何网段的数据包都发往网关169.254.1.1,然后从eth0网卡发送出去。
路由表中Flags标志的含义:
Uup 表示当前为启动状态
Hhost 表示该路由是到一个主机
GGateway 表示该路由是到一个网关,如果没有说明目的地是直连的
DDynamicaly 表示该路由是由重定向报文创建的
M 表示该路由已被重定向报文修改
node1节点上的路由信息
node1节点操作:route -n
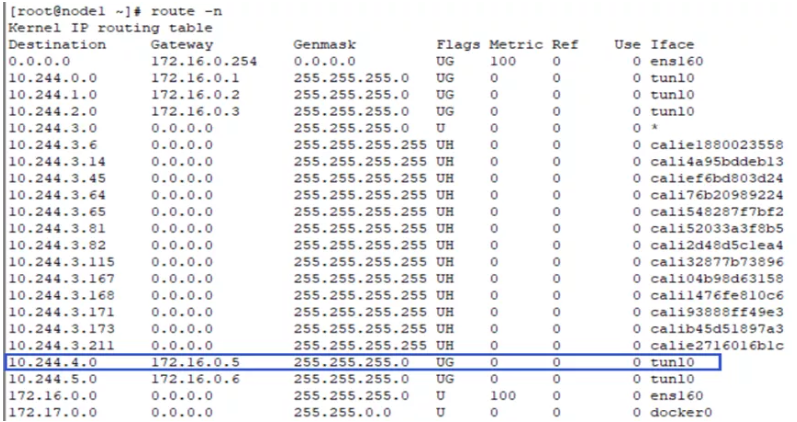
当ping包来到node1节点上,会匹配到路由tunl0。该路由的意思是:去往10.244.4.0/24的网段的数据包都发往网关172.16.0.5。因为pod1(nfs-provisioner-8d6dbc584-cdfxz )在172.16.0.4上,pod2(fierce-body-redis-metrics-6cf79f9d64-v6zs2 )在172.16.0.5上。所以数据包就通过设备tunl0发往到node2节点上。
node2节点上的路由信息
node2节点操作:
route -n

当node2节点网卡收到数据包之后,发现发往的目的ip是10.244.4.188,于是匹配到蓝线的路由。该路由的意思是:10.244.4.188是本机直连设备,去往设备的数据包发往cali52e15d97942。
那么该设备是什么呢?如果到这里你能猜出来是什么,那说明你的网络功底是不错的。这个设备就是vethpair的一端,在创建pod2(fierce-body-redis-metrics-6cf79f9d64-v6zs2 )时calico会给pod2创建一个veth pair设备。一端是pod2的网卡,另一端就是我们看到的cali52e15d97942。下面我们验证一下,在pod2中安装ethtool工具,然后使用ethtool -S eth0,查看veth pair另一端的设备号。
master1节点新打开一个窗口3:
kubectl exec -it fierce-body-redis-metrics-6cf79f9d64-v6zs2 -- /bin/sh
#ethtool -S eth0

pod2网卡另一端的设备号是193,在node2上查看编号为193的网络设备,可以发现该网络设备就是cali52e15d97942 。
node2上操作 #ipaddr 显示如下

所以,node2上的路由,发送cali52e15d97942的数据其实就是发送到pod2的网卡中。ping包的旅行到这里就到了目的地
查看一下pod2中的路由信息,发现该路由信息和pod1中是一样的。
master1节点新打开一个窗口4:
kubectl exec -it fierce-body-redis-metrics-6cf79f9d64-v6zs2 -- /bin/sh
#route -n

顾名思义,IPIP网络就是将IP网络封装在IP网络里,IPIP网络的特点是所有pod的数据流量都从隧道tunl0发送,并且在tunl0这增加了一层传输层的封包。
在node1节点上抓包分析该过程:
node1节点操作:tcpdump -i ens160 -vvv–w ipip.pcap

node1节点操作:把ipip.pcap上传到桌面上,用wireshark打开分析数据包

10.244.3.14:pod1(nfs-provisioner-8d6dbc584-cdfxz )
10.244.4.188:pod2(fierce-body-redis-metrics-6cf79f9d64-v6zs2 )
打开ICMP 32,pod1 ping pod2的数据包,能够看到该数据包一共5层,其中IP所在的网络层有两个,分别是pod之间的网络和主机之间的网络封装。

根据数据包的封装顺序,应该是在pod1 ping pod2的ICMP包外面多封装了一层主机之间的数据包。
之所以要这样做是因为tunl0是一个隧道端点设备,在数据到达时要加上一层封装,便于发送到对端隧道设备中。
两层IP封装的具体内容
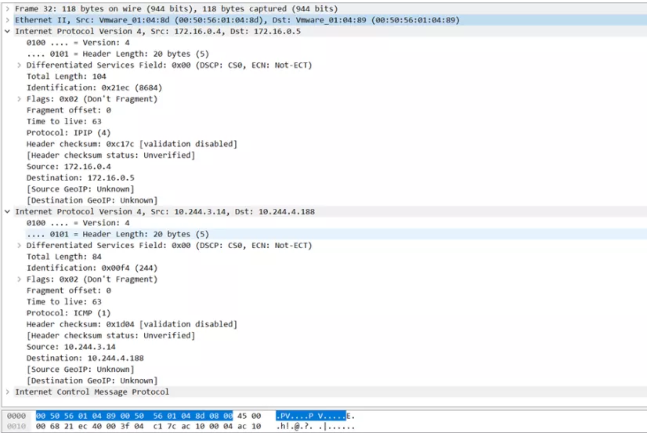
IPIP的连接方式:

calico的BGP网络模式
1.BGP网络模式
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议;BGP,通俗的讲就是将接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP;
BGP机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。世纪互联BGP技术具备动态优选路由的能力,一点接入,轻松部署,创造无界的互联网络;并可多线互备,智能选路,线路互为冗余,具有较高的可靠性;随着客户业务的不断增加,可方便扩充线路,保障客户业务持续需求。
1)开启BGP网络模式
修改calico.yaml文件,把IPIP模式禁用即可
-name: CALICO_IPV4POOL_IPIP
value: off
2)对比
BGP网络相比较IPIP网络,最大的不同之处就是没有了隧道设备 tunl0。前面介绍过IPIP网络pod之间的流量发送tunl0,然后tunl0发送对端设备。BGP网络中,pod之间的流量直接从网卡发送目的地,减少了tunl0这个环节。
node1节点上路由信息。从路由信息来看,没有tunl0设备
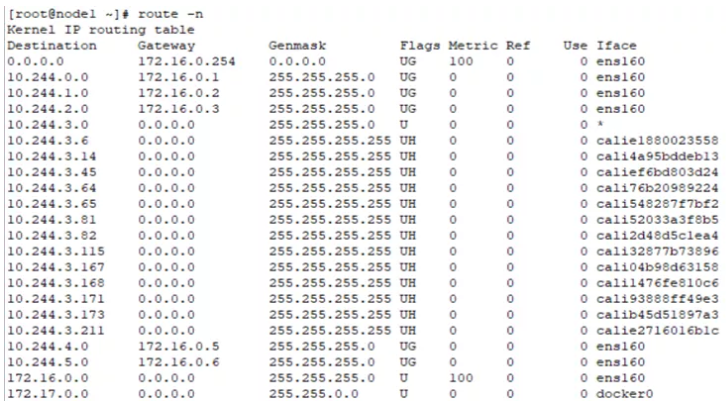
2.测试环境
master1:172.16.0.1 node1:172.16.0.4 node2:172.16.0.5
master1节点执行如下命令,查看宿主机创建的pod有哪些
master1节点的窗口1:
kubectl get pods -o wide 显示如下

用node1节点上的pod(nfs-provisioner-8d6dbc584-cdfxz)ping node2节点上的pod(fierce-body-redis-metrics-6cf79f9d64-v6zs2)
master1节点操作:
kubectl exec -it nfs-provisioner-8d6dbc584-cdfxz -- /bin/sh
#ping 10.244.4.188
1)ping包的走向
查看node1节点pod上的路由信息:
master1节点新打开一个窗口2:
kubectl exec -it nfs-provisioner-8d6dbc584-cdfxz -- /bin/sh
#route -n

根据node1节点上pod的路由信息,ping包通过eth0网卡发送到node1节点上。
node1节点操作:route -n 显示如下
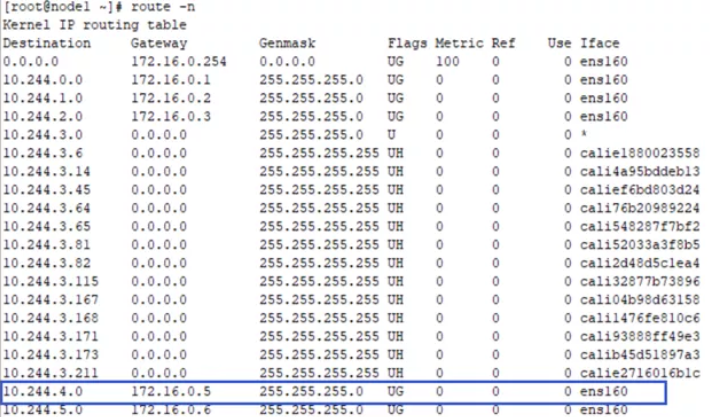
上面是node1节点上的路由信息。根据匹配到的10.244.4.0路由,该路由的意思是:去往网段10.244.4.0/24 的数据包都发往网关172.16.0.5。而172.16.0.5就是node2节点。所以,该数据包直接发送到了node2节点。
node2上操作: route–n 显示如下
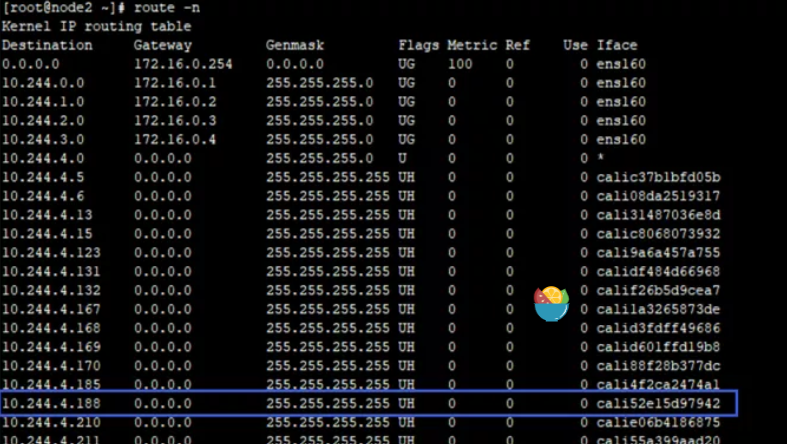
上面是node2节点上的路由信息。根据匹配到的10.244.4.188的路由,数据将发送给 cali52e15d97942设备,该设备和上面分析的是一样,为node2节点上的pod2(fierce-body-redis-metrics-6cf79f9d64-v6zs2 )的vethpair 的一端。数据就直接发送给pod2的网卡。
当pod2对ping包做出回应之后,数据到达node2节点上,匹配到10.244.3.0的路由,该路由说的是:去往网段10.244.3.0/24 的数据,发送给网关 172.16.0.4。数据包就直接通过网卡ens160,发送到node1节点上。

通过在node1节点上抓包,查看经过的流量,筛选出ICMP,找到pod1 ping pod2的数据包。
node1节点上操作:
tcpdump -i ens160 -vvv-wbgp.pcap

把上面的bgp.pcap上传到桌面
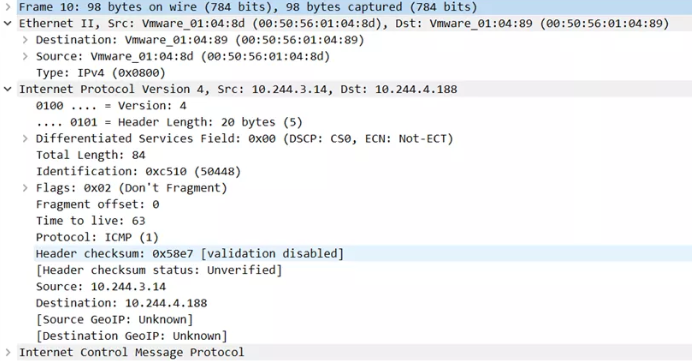
可以看到BGP网络下,没有使用IPIP模式,数据包是正常的封装。

值得注意的是mac地址的封装。10.244.3.14是pod1的ip,10.244.4.188是pod2的ip。而源mac地址是node1节点网卡的mac,目的mac是node2节点的网卡的mac。这说明,在node1节点的路由接收到数据,重新构建数据包时,使用arp请求,将node2节点的mac拿到,然后封装到数据链路层。
2)BGP的连接方式:
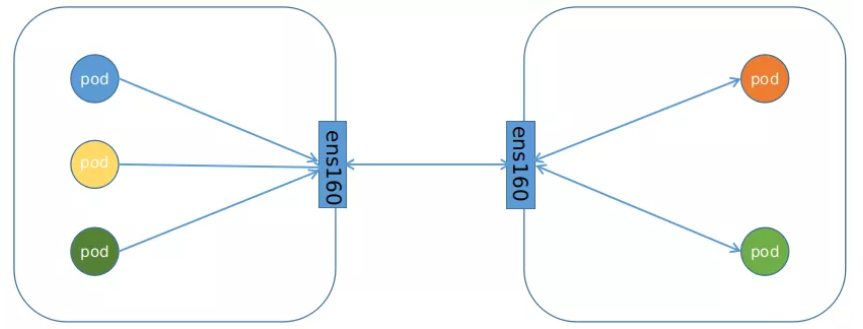
3.calico的两种网络模式对比
IPIP网络:
流量:tunlo设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景,外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低
BGP网络:
流量:使用路由信息导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生host-gw,效率高
4.Calico网络优点
1)在网络连接过程中性能高:
Calico配置第3层网络,该网络使用BGP路由协议在主机之间路由数据包,不需要将数据包包装在额外的封装层中。
2)支持网络策略:
网络策略是其最受追捧的功能之一。此外,Calico还可以与服务网格Istio集成,以便在服务网格层和网络基础架构层中解释和实施集群内工作负载的策略,这意味着用户可以配置强大的规则,描述Pod应如何发送和接受流量,提高安全性并控制网络环境。
5.Calico网络缺点
(1) 缺点租户隔离问题
Calico 的三层方案是直接在 host 上进行路由寻址,那么对于多租户如果使用同一个pod网络就面临着地址冲突的问题。
(2) 路由规模问题
通过路由规则可以看出,路由规模和 pod 分布有关,如果 pod离散分布在host 集群中,势必会产生较多的路由项。
(3) iptables 规则规模问题
1台Host 上可能虚拟化十几或几十个容器实例,过多的 iptables 规则造成复杂性和不可调试性,同时也存在性能损耗。
6.flannel和calico网络性能分析,官方指标如下
flannel host-gw = flannel vxlan-directrouting = calico bgp> calico ipip > flannel vxlan-vxlan>flannel-udp
官方推荐使用的网络方案:
所有节点在同一个网段推荐使用calico的bgp模式和flannel的host-gw模式
性能总结分析:
Flannel的vxlan模式:封包解包采用的是内置在linux内核里的标准协议,虽然它的封包结构比UDP模式复杂,但由于所有数据封包、解包过程均在内核中完成,实际的传输速度要比UDP模式快许多
Flannel的host-gw模式:Flannel通过在各个节点上的Agent进程,将容器网络的路由信息刷到主机的路由表上,这样一来所有的主机就都有整个容器网络的路由数据了;Host-gw的方式没有引入像Overlay中的额外装包解包操作,完全是普通的网络路由机制,它的效率与虚拟机直接的通信相差无几,但是要求所有host在二层互联
转载原文:https://mp.weixin.qq.com/s/DgidS4n9rnkOX_2vJ7MrRg