PostgreSQL是一种关系型数据库管理系统 (RDBMS)。这意味着它是一种用于管理存储在关系中的数据的系统。
一、准备一个测试数据库
1、docker 安装 pg
docker run -d --name postgres --restart always \ -e POSTGRES_USER=pg \ -e POSTGRES_PASSWORD=5740## \ -e ALLOW_IP_RANGE=0.0.0.0/0 \ -v /home/postgres/data:/var/lib/postgresql -p 5432:5432 postgres:10
-e ALLOW_IP_RANGE=0.0.0.0/0,这个表示允许所有ip访问,如果不加,则非本机 ip 访问不了
-e POSTGRES_USER= xx 用户名
-e POSTGRES_PASS=xx 指定密码
2、启动一个pgadmin
docker run --name pgadmin -p 5080:80 \ -e 'PGADMIN_DEFAULT_EMAIL=zjz@qq.com' \ -e 'PGADMIN_DEFAULT_PASSWORD=123456' \ -e 'PGADMIN_CONFIG_ENHANCED_COOKIE_PROTECTION=True' \ -e 'PGADMIN_CONFIG_LOGIN_BANNER="Authorised users only!"' \ -e 'PGADMIN_CONFIG_CONSOLE_LOG_LEVEL=10' \ -d dpage/pgadmin4:4.17
二、高级查询操作
1、求平均值与AS
AS子句是如何给输出列重新命名的
SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
2、where子句:一个查询可以使用WHERE子句“修饰”,它指定需要哪些行。
WHERE子句包含一个布尔(真值)表达式,只有那些使布尔表达式为真的行才会被返回。在条件中可以使用常用的布尔操作符(AND、OR和NOT)。
select * from weather where temp_lo = 46 AND prcp > 0.4;
3、ORDER BY
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照升序对记录进行排序。
如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
SELECT * FROM weather ORDER BY prcp; SELECT * FROM weather ORDER BY temp_lo, prcp;
4、查询的结果中消除重复的行 DISTINCT
SELECT DISTINCT temp_lo FROM weather;
5、多表联合查询
SELECT * FROM weather, cities WHERE city = name;

当天气和城市表(weather, cities )city字段和name字段相同时,查询结果。
5、把name字段去掉,显示更加美观
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;

6、列的名字都不一样,所以规划器自动地找出它们属于哪个表。
如果在两个表里有重名的列,你需要限定列名来说明你究竟想要哪一个,如:
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather, cities
WHERE cities.name = weather.city;
7、 INNER JOIN
SELECT *
FROM weather INNER JOIN cities ON (weather.city = cities.name);
8、左外连接 LEFT OUTER JOIN
想让查询干的事是扫描weather表, 并且对每一行都找出匹配的cities表行。如果我们没有找到匹配的行,那么我们需要一些“空值”代替cities表的列。 这种类型的查询叫外连接 (我们在此之前看到的连接都是内连接)。
SELECT *
FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name);

查询是一个左外连接, 因为在连接操作符左部的表中的行在输出中至少要出现一次, 而在右部的表的行只有在能找到匹配的左部表行是才被输出。 如果输出的左部表的行没有对应匹配的右部表的行,那么右部表行的列将填充空值(null)。
9、右外连接
10、全外连接
11、自连接:把weather表重新标记为 W1 和 W2 以区分连接的左部和右部。·
SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
W2.city, W2.temp_lo AS low, W2.temp_hi AS high
FROM weather W1, weather W2
WHERE W1.temp_lo < W2.temp_lo
AND W1.temp_hi > W2.temp_hi;
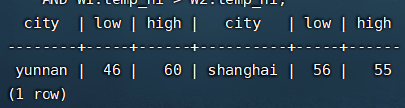
12、使用别名,在其它查询里节约一些敲键,比如:
SELECT *
FROM weather w, cities c
WHERE w.city = c.name;
13、聚集函数
PostgreSQL支持聚集函数。 一个聚集函数从多个输入行中计算出一个结果。 比如,我们有在一个行集合上计算count(计数)、sum(和)、avg(均值)、max(最大值)和min(最小值)的函数。
我们可以用下面的语句找出所有记录中最低温度中的最高温度:
SELECT max(temp_lo) FROM weather;
14、聚集max不能被用于WHERE子句中(存在这个限制是因为WHERE子句决定哪些行可以被聚集计算包括;因此显然它必需在聚集函数之前被计算)。
可以使用子查询: 因为子查询是一次独立的计算,它独立于外层的查询计算出自己的聚集。
SELECT city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
15、HAVING 过滤、LIKE操作符进行模式匹配
只给出那些所有temp_lo值曾都低于 40的城市。最后,如果我们只关心那些名字以“S”开头的城市,我们可以用:
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%' -- (1)
GROUP BY city
HAVING max(temp_lo) < 40;
16、更新update 、set
UPDATE weather
SET temp_hi = temp_hi - 4, temp_lo = temp_lo - 4
WHERE date = '1995-11-27';
17、删除delete
DELETE FROM weather WHERE city = 'Hayward'; DELETE FROM tablename;
如果没有一个限制,DELETE将从指定表中删除所有行,把它清空。做这些之前系统不会请求你确认!
18、视图(快捷键)
假设天气记录和城市为止的组合列表对我们的应用有用,但我们又不想每次需要使用它时都敲入整个查询。可以在该查询上创建一个视图,这会给该查询一个名字,我们可以像使用一个普通表一样来使用它:
CREATE VIEW myview AS
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
19、外键(primary key、 references )
希望确保在cities表中有相应项之前任何人都不能在weather表中插入行。这叫做维持数据的引用完整性。
在过分简化的数据库系统中,可以通过先检查cities表中是否有匹配的记录存在,然后决定应该接受还是拒绝即将插入weather表的行。这种方法有一些问题且并不方便,于是PostgreSQL可以为我们来解决:
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
尝试插入一个非法值
INSERT INTO weather1 VALUES ('Berkeley', 45, 53, 0.0, '1994-11-28');
ERROR: insert or update on table "weather1" violates foreign key constraint "weather1_city_fkey"
DETAIL: Key (city)=(Berkeley) is not present in table "cities1".
外键的行为可以很好地根据应用来调整。
20、 事务
事务是所有数据库系统的基础概念。事务最重要的一点是它将多个步骤捆绑成了一个单一的、要么全完成要么全不完成的操作。步骤之间的中间状态对于其他并发事务是不可见的,并且如果有某些错误发生导致事务不能完成,则其中任何一个步骤都不会对数据库造成影响。
例如,考虑一个保存着多个客户账户余额和支行总存款额的银行数据库。假设我们希望记录一笔从Alice的账户到Bob的账户的额度为100.00美元的转账。在最大程度地简化后,涉及到的SQL命令是:
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
UPDATE branches SET balance = balance - 100.00
WHERE name = (SELECT branch_name FROM accounts WHERE name = 'Alice');
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
UPDATE branches SET balance = balance + 100.00
WHERE name = (SELECT branch_name FROM accounts WHERE name = 'Bob');
在PostgreSQL中,开启一个事务需要将SQL命令用BEGIN和COMMIT命令包围起来。
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
-- etc etc
COMMIT;
如果,在事务执行中我们并不想提交(或许是我们注意到Alice的余额不足),我们可以发出ROLLBACK命令而不是COMMIT命令,这样所有目前的更新将会被取消。
PostgreSQL实际上将每一个SQL语句都作为一个事务来执行。如果我们没有发出BEGIN命令,则每个独立的语句都会被加上一个隐式的BEGIN以及(如果成功)COMMIT来包围它。一组被BEGIN和COMMIT包围的语句也被称为一个事务块。
21、窗口函数
一个窗口函数在一系列与当前行有某种关联的表行上执行一种计算。这与一个聚集函数所完成的计算有可比之处。但是窗口函数并不会使多行被聚集成一个单独的输出行,这与通常的非窗口聚集函数不同。取而代之,行保留它们独立的标识。在这些现象背后,窗口函数可以访问的不仅仅是查询结果的当前行。
下面是一个例子用于展示如何将每一个员工的薪水与他/她所在部门的平均薪水进行比较:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary; depname | empno | salary | avg -----------+-------+--------+----------------------- develop | 11 | 5200 | 5020.0000000000000000 develop | 7 | 4200 | 5020.0000000000000000 develop | 9 | 4500 | 5020.0000000000000000 develop | 8 | 6000 | 5020.0000000000000000 develop | 10 | 5200 | 5020.0000000000000000 personnel | 5 | 3500 | 3700.0000000000000000 personnel | 2 | 3900 | 3700.0000000000000000 sales | 3 | 4800 | 4866.6666666666666667 sales | 1 | 5000 | 4866.6666666666666667 sales | 4 | 4800 | 4866.6666666666666667 (10 rows)
最开始的三个输出列直接来自于表empsalary,并且表中每一行都有一个输出行。第四列表示对与当前行具有相同depname值的所有表行取得平均值(这实际和非窗口avg聚集函数是相同的函数,但是OVER子句使得它被当做一个窗口函数处理并在一个合适的窗口帧上计算。)。
一个窗口函数调用总是包含一个直接跟在窗口函数名及其参数之后的OVER子句。这使得它从句法上和一个普通函数或非窗口函数区分开来。OVER子句决定究竟查询中的哪些行被分离出来由窗口函数处理。OVER子句中的PARTITION BY子句指定了将具有相同PARTITION BY表达式值的行分到组或者分区。对于每一行,窗口函数都会在当前行同一分区的行上进行计算。
可以通过OVER上的ORDER BY控制窗口函数处理行的顺序(窗口的ORDER BY并不一定要符合行输出的顺序。)。
22、继承
继承是面向对象数据库中的概念。它展示了数据库设计的新的可能性。
CREATE TABLE cities ( name text, population real, altitude int -- (in ft) ); CREATE TABLE capitals ( state char(2) ) INHERITS (cities);
在这种情况下,一个capitals的行从它的父亲cities继承了所有列(name、population和altitude)。列name的类型是text,一种用于变长字符串的本地PostgreSQL类型。州首都有一个附加列state用于显示它们的州。在PostgreSQL中,一个表可以从0个或者多个表继承
SQL 连接(JOIN) | 菜鸟教程 (runoob.com)
PostgreSQL 连接(JOIN) | 菜鸟教程 (runoob.com)
PostgreSQL=>递归查询 - funnyZpC - 博客园 (cnblogs.com)
PostgreSQL:递归查询应用场景 | PostgreSQL 中文网
PostgreSQL: 如何连接 Group By 结果集的行? | PostgreSQL 中文网
PostgreSQL: 关于 Left Join 的基础知识 | PostgreSQL 中文网
PostgreSQL:如何查询表的字段信息? | PostgreSQL 中文网
PostgreSQL:分区表的相关查询 | PostgreSQL 中文网
PostgreSQL:如何查询库中包含某个字段的所有表。 | PostgreSQL 中文网
PostgreSQL用户应掌握的高级SQL特性 | PostgreSQL 中文网
PostgreSQL技术之家: PostgreSQL新手指引 (pgsql.tech)
SQL ORDER BY 子句 (w3school.com.cn) 必看
PostgreSQL技术之家: PostgreSQL新手指引 (pgsql.tech) 必看
两位pg大佬:
PostgreSQL培训系列直播—第四章 第1节 应用开发者指南-技术公开课-阿里云开发者社区 (aliyun.com)