
原文链接:https://arxiv.org/pdf/1705.03633.pdf
Visual Reasoning
传统的神经网络常被称为“黑箱”,其完成任务的过程是端到端的,由训练数据经过大量参数拟合直接得到预测结果,这其中的逻辑推理过程是不清晰的。研究者希望能够打破黑箱,探索神经网络在完成VQA (Visual Question Answering) 时能够显式的表达出推理过程,并根据这些推理阶段进行训练。这就是视觉推理(Visual Reasoning)。
CLEVR
斯坦福大学李飞飞团队提出了CLEVR数据集,专门针对视觉推理任务。
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning

如上图,CLEVR中的图片包括不同形状、大小、材料、颜色、位置的几何体,问题本身较为复杂,比如“大球左边的棕色金属物体左边的圆柱体是什么尺寸?”、“大物体和金属球的数量一样吗”。为了分析这种问题,需要分别找出大物体和金属球、计算数量、比较数量,这是一个三步的推理过程。


CLEVR数据集除了提供图片、问题、答案之外,也提供了上述推理过程中每一步的ground-truth,这样在训练过程中我们既可以评判模型的预测结果,也可以分析它的推理能力。
传统的VQA模型在CLEVR上的表现并不好,说明传统的端到端结构并不具备推理能力。
Structure
李飞飞团队在这篇论文中提出了一个模型来解决上述问题。

思路是将逻辑推理中的每一步当做一个单独的program,由Program Generator生成,最后用Execution Engine按顺序执行这些程序。
Program Generator是一个Seq-to-Seq的LSTM网络,输入问题,生成对应的程序(本文中均是ResNet)。每个小程序都是一个神经网络模块,且输出的Feature具有相同的维度。在这个前提下,Execution Engine可以直接将这些小程序串起来,在最开始输入图片信息经过CNN提取特征,在最后输出结果。
例如图中的例子,问题是“立方体是否比黄色物体多”,Program Generator首先生成对应的小程序(筛选形状-立方体、计数、筛选颜色-黄色、计数、比较大小),输入图片经过CNN提取特征,然后依次经过各个小程序得到结果。
Experiments
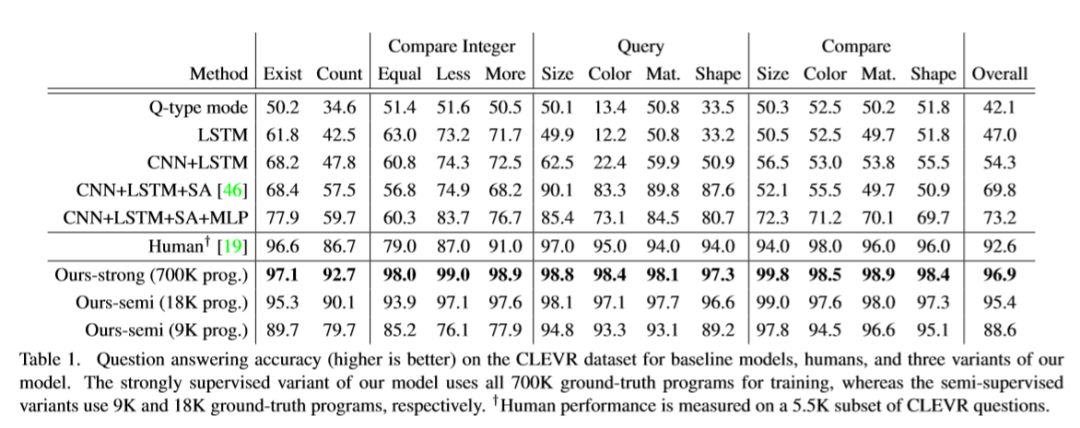
首先作者比较了稳重的模型与其他模型在CLEVR上的不同问题(存在性、计数、比较大小、询问颜色形状、比较颜色形状)上的准确率,ground-truth program指在监督学习时回答某个问题所需的ground-truth的推理过程(即generator生成的小程序模块)。
下方三行分别对应不同的ground-truth program数量,即监督学习/半监督学习的程度。可以看到,在强监督下本文的模型甚至超过了人类的正确率。

之后作者分析了模型在不同条件下的结果。先在条件A下训练模型,在A、B条件下分别测试。之后在条件B下微调模型(并没有使用ground-truth program),再在A、B条件下进行测试。折线图显示了在条件B微调时使用不同数据量的影响。
Qualitative Results

上图统计了feature map的分数之和以显示可视化效果。加下划线的区域为新加的模块,颜色亮的部分表示当前推理过程中所关注的热点区域。

图中提供了CLEVR数据集中的问题示例,以及新模型预测的程序与答案。绿色、黄色、红色分别代表预测程序与问题语义完全匹配、匹配度较高、无法匹配。