Kettle的安装和使用
Kettle的安装和使用_厦大数据库实验室博客 (xmu.edu.cn)
Kettle简介
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,数据抽取高效稳定。
Kettle是“Kettle E.T.T.L. Envirnonment“只取首字母的缩写,这意味着它被设计用来帮助你实现你的 ETTL 需要:抽取、转换、装入和加载数据;翻译成中文名称应该叫水壶,名字的起源是开发者希望把各种数据放到一个壶里然后以一种指定的格式流出。
Spoon 是一个图形用户界面,它允许你运行转换或者任务,其中转换是用 Pan 工具来运行,任务是用 Kitchen 来运行。Pan 是一个数据转换引擎,它可以执行很多功能,例如:从不同的数据源读取、操作和写入数据。Kitchen 是一个可以运行利用 XML 或数据资源库描述的任务。通常任务是在规定的时间间隔内用批处理的模式自动运行。
注:在正式进入本教程前,请确保你的计算机已经配置好java环境。
下载并安装Kettle
1.下载Kettle安装包
登陆ubuntu系统,用ubuntu系统的浏览器打开Kettle官网下载最新稳定版kettle压缩包,这里我们下载7.1版本。点击下图中的链接开始下载(压缩包有接近900M),下载完成后文件默认保存在路径~/Downloads或~/下载。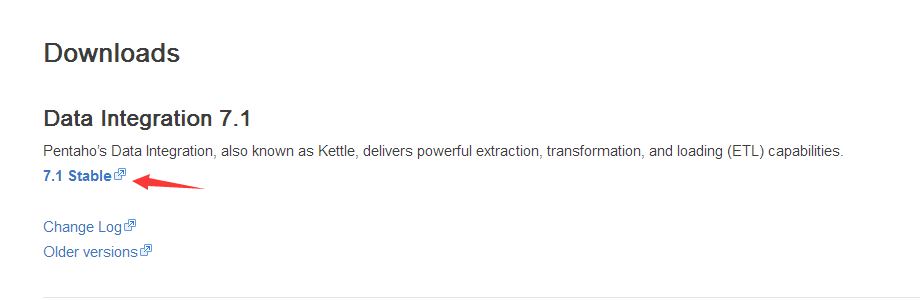
2.新建文件夹/usr/local/kettle
为了把kettle安装在目录/usr/local/kettle,这里我们先新建文件夹,并修改属主权限,以便当前用户可以操作该文件夹。
- sudo mkdir -p /usr/local/kettle #递归方式新建文件夹
- sudo chown -R dblab /usr/local/kettle #修改文件夹属主,使得dblab用户可以操作该文件夹
3.解压zip包
利用下列命令解压下载好的zip包,同时指定解压后的文件保存路径为/usr/local/kettle。
- unzip ~/Downloads/pdi-ce-7.1.0.0-12.zip -d /usr/local/kettle #解压zip包,并将解压后的文件保存到/usr/local/kettle
4.复制MySQL驱动JAR包
后续需要连接MySQL数据库,因此需要相关的驱动JAR包。首先从官网下载MySQL驱动JAR包(两种压缩格式均可,笔者下载的是zip压缩格式),下载完成默认保存在目录~/Downloads或~/下载,利用下列命令将其解压,并将jar包复制到/usr/local/kettle/data-integration/lib
- cd ~/Downloads
- unzip mysql-connector-java-5.1.40.zip #解压到当前文件夹
- cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/kettle/data-integration/lib #复制mysql驱动包到/usr/local/kettle/data-integration/lib
5.启动kettle
kettle的安装目录/usr/local/kettle下的文件夹data-integration里包含两个kettle工具启动的脚本命令,spoon.bat和spoon.sh,其中spoon.bat适用于windows系统,通过双击.bat文件来启动图形化界面,而spoon.sh适用于Linux系统,通过在终端执行下列命令来启动图形化界面。
- cd /usr/local/kettle/data-integration
- ./spoon.sh #执行脚本
截图如下: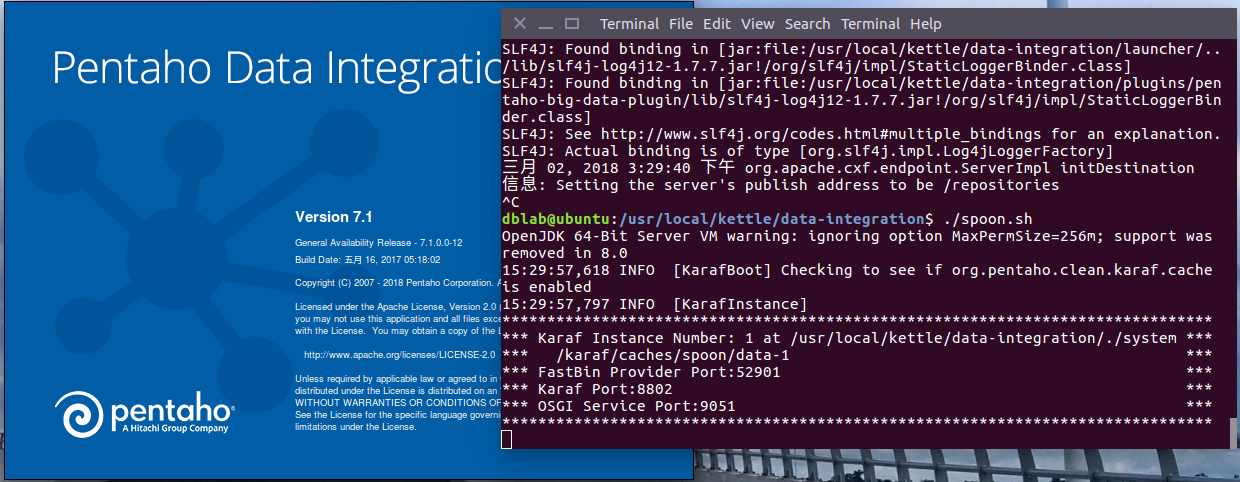
如果上述命令无法执行,提示无执行权限,请先执行下列命令为spoon.sh赋予执行权限。
- chmod +x spoon.sh
启动之后,可能会弹框提示:用户缺少某某包,可能会导致程序无法正常使用。如果出现该提示,先关闭图形化界面,输入下列命令逐一安装这些包。
- #示例:缺少libwebkitgtk-1.0包
- sudo apt-get install libwebkitgtk-1.0
安装完成后,再次启动kettle工具即可。
使用Kettle
这里我们通过一个案例来了解kettle的使用,选取MySQL作为数据源。
案例背景
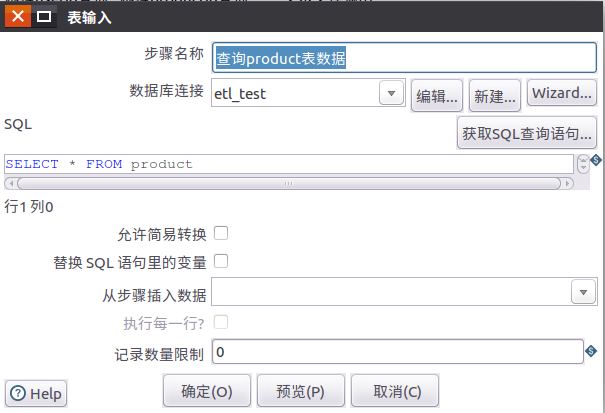
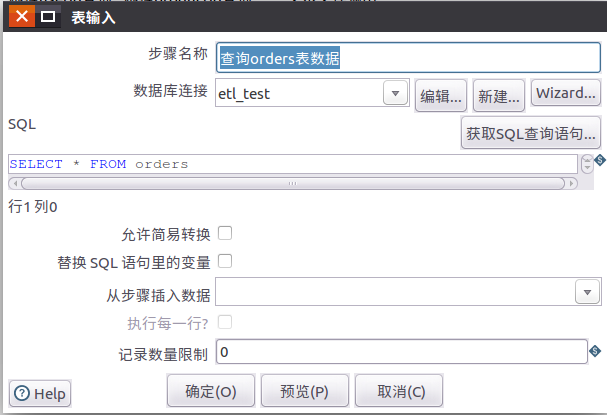
找出不同性别,不同年龄,不同职业的用户对于哪类产品比较感兴趣,为建立数据仓库,进行数据挖掘和OLAP分析做准备。根据客户user,订单orders,产品表product中的数据,利用kettle处理生成对应的数据文件,并且可以用job来调用整个流程。
数据准备
1.启动MySQL
- service mysql start #启动mysql服务,默认mysql服务是随开机启动的,此步可省
- mysql -u root -p
2.创建数据库kettle
- mysql> create database kettle;
3.创建user,product,orders表,并插入测试数据
注:下列命令是在mysql shell中执行,每段sql语句(除#号注释行以外)都可以整段复制粘贴执行,无须逐句复制。
- use kettle;
- #------------创建表user
- DROP TABLE IF EXISTS `user`;
- CREATE TABLE `user` (
- `userid` int(10) DEFAULT NULL COMMENT '用户ID',
- `username` varchar(10) DEFAULT NULL COMMENT '用户姓名',
- `usersex` varchar(1) DEFAULT NULL COMMENT '性别',
- `userposition` varchar(20) DEFAULT NULL COMMENT '职业',
- `userage` int(3) DEFAULT NULL COMMENT '年龄'
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- #------------插入数据
- INSERT INTO `user` VALUES ('1', '陈XX', '女', '学生', '20');
- INSERT INTO `user` VALUES ('2', '王XX', '男', '工程师', '30');
- INSERT INTO `user` VALUES ('3', '李XX', '女', '医生', '40');
- #------------创建表product
- DROP TABLE IF EXISTS `product`;
- CREATE TABLE `product` (
- `productid` int(10) DEFAULT NULL COMMENT '产品ID',
- `productname` varchar(20) DEFAULT NULL COMMENT '产品名称'
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- #------------插入数据
- INSERT INTO `product` VALUES ('1', '手机');
- INSERT INTO `product` VALUES ('2', '电脑');
- INSERT INTO `product` VALUES ('3', '水杯');
- #------------创建表orders
- DROP TABLE IF EXISTS `orders`;
- CREATE TABLE `orders` (
- `orderid` int(10) DEFAULT NULL COMMENT '订单ID',
- `userid` int(10) DEFAULT NULL COMMENT '用户ID',
- `productid` int(10) DEFAULT NULL COMMENT '产品ID',
- `buytime` datetime DEFAULT NULL COMMENT '购买时间'
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- #------------插入数据
- INSERT INTO `orders` VALUES ('1', '1', '1', '2017-06-01 15:02:02');
- INSERT INTO `orders` VALUES ('2', '1', '2', '2017-06-02 15:02:22');
- INSERT INTO `orders` VALUES ('3', '1', '3', '2017-06-02 15:02:36');
- INSERT INTO `orders` VALUES ('4', '2', '1', '2017-06-06 15:02:52');
- INSERT INTO `orders` VALUES ('5', '3', '2', '2017-06-09 16:55:24');
- INSERT INTO `orders` VALUES ('6', '2', '2', '2017-07-14 14:01:36');
建立并执行作业
首先利用下列命令启动kettle
- cd /usr/local/kettle/data-integration
- ./spoon.sh
接下来,开始使用kettle完成案例内容:将MySQL数据源里的三张表用户指定的信息输入到kettle,通过JOB执行转换,并输出一个文本文件。
1.建立作业JOB
1.1 新建转换并保存转换文件
右键-新建转换。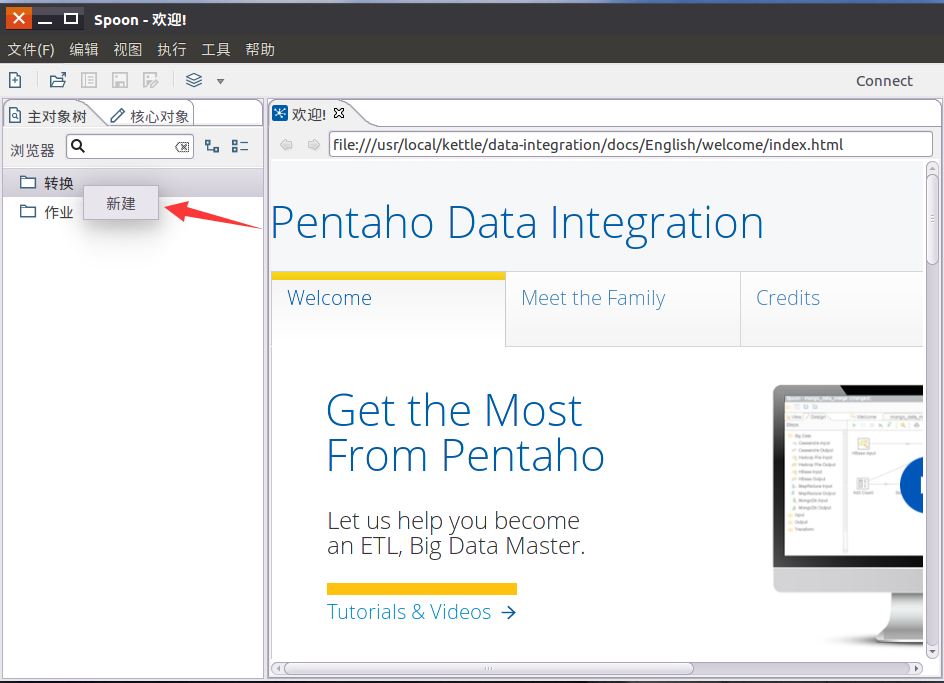
保存新建的转换文件,指定名称和保存路径。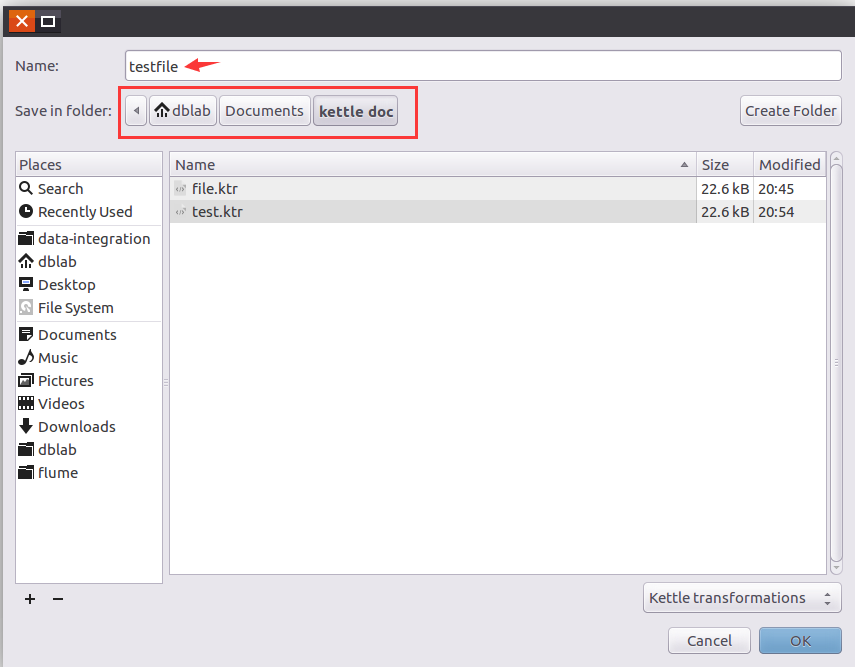
1.2 连接数据库
选择MySQL作为数据源,双击“DB连接”,输入相关的认证信息,如数据库名、用户名和密码等。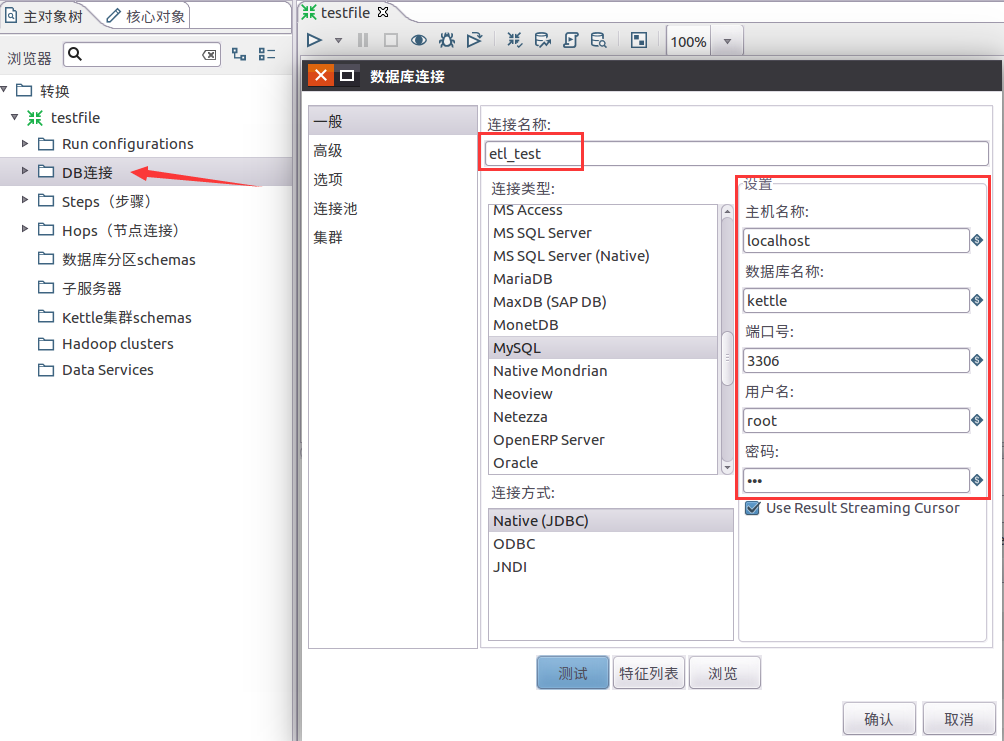
点击测试按钮,测试是否连接数据库成功,如果连接成功,会弹出如下信息。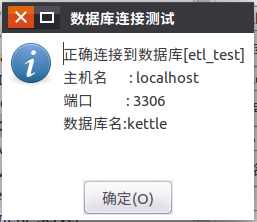
如果弹出如下信息,说明缺少mysql驱动包,请按照上一节的第4小节下载mysql驱动包,并复制到目录/usr/local/kettle/data-integration/lib,重新启动kettle即可。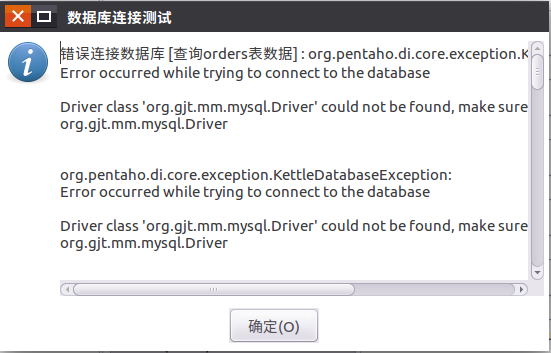
1.3 切换到核心对象,拖动3个表输入控件到设计区域
表输入控件位于:核心对象-输入-表输入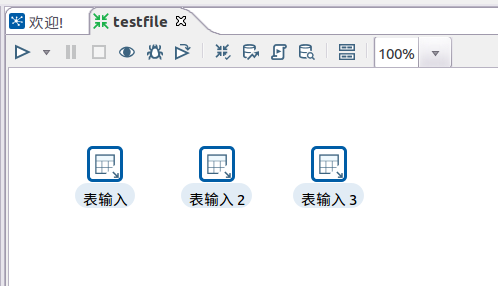
1.4 双击表输入控件,设置表输入控件的属性信息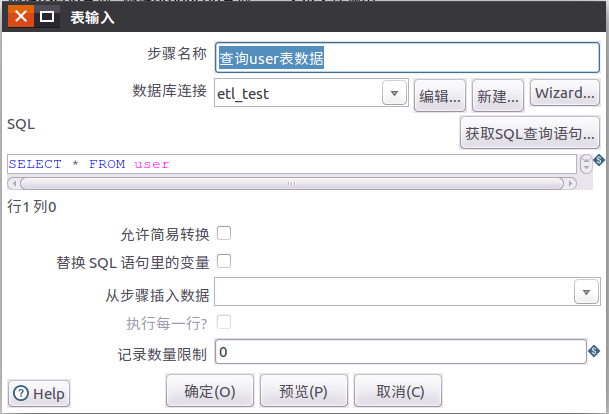
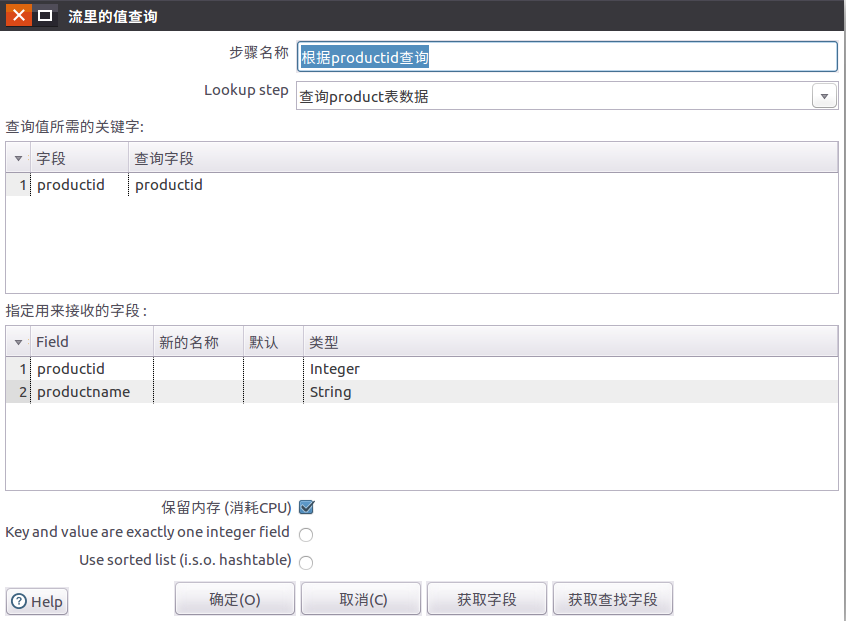
1.5 拖动2个流查询到设计区域,并设置流查询的属性信息
流查询控件位于:核心对象-查询-流查询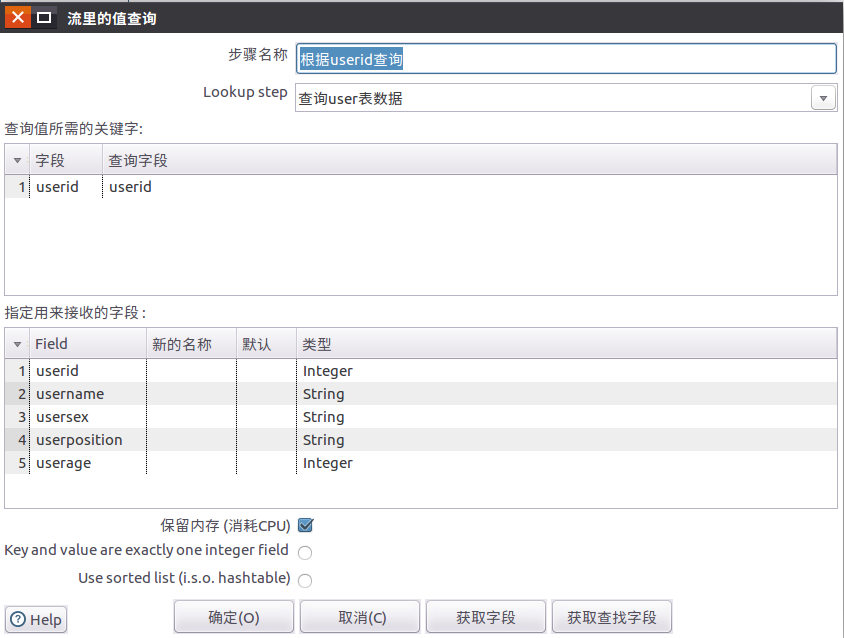
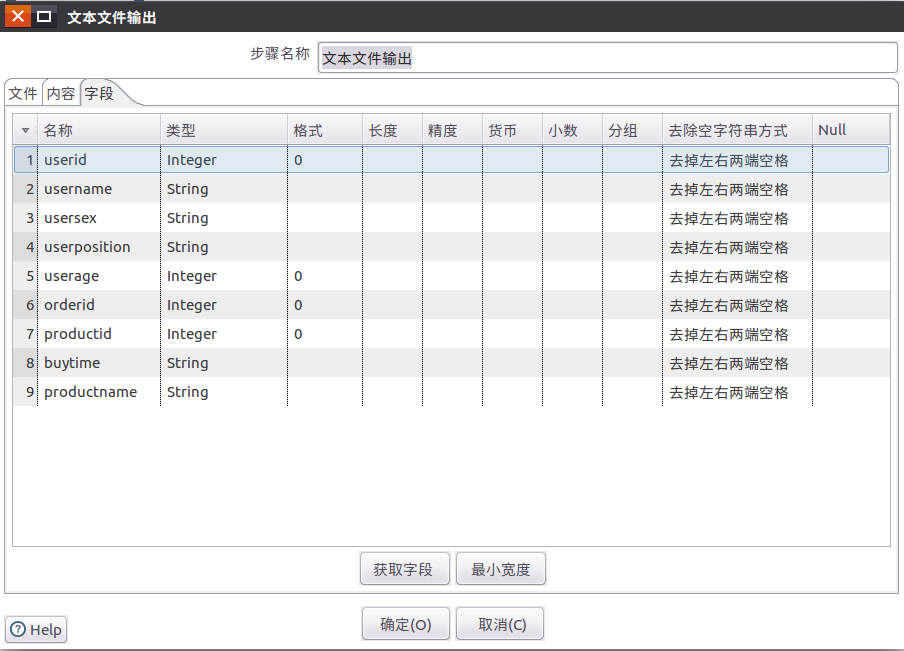
1.6 拖动1个文本文件输出到设计区域,并设置输出的属性信息
文本文件输出控件位于:核心对象-输出-文件文件输出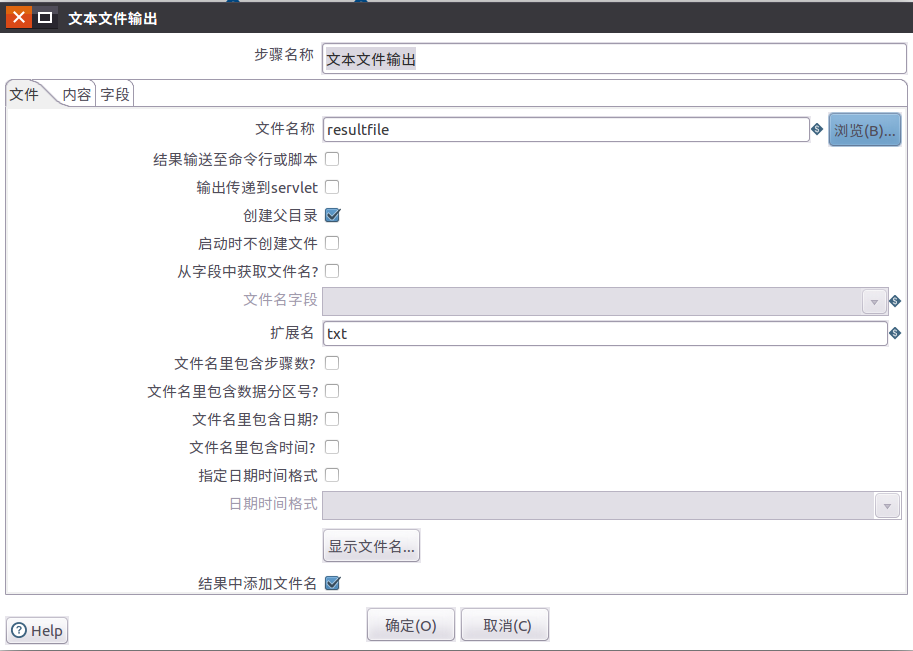
1.7 连接控件
按住shift键,长按鼠标左键移动鼠标,可以连接两个控件,按如下图所示关联个控件。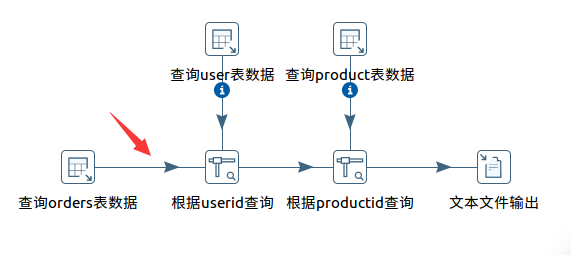
2.执行JOB
2.1 点击启动按钮执行JOB
点击设计区域上方的小三角形按钮,启动作业。
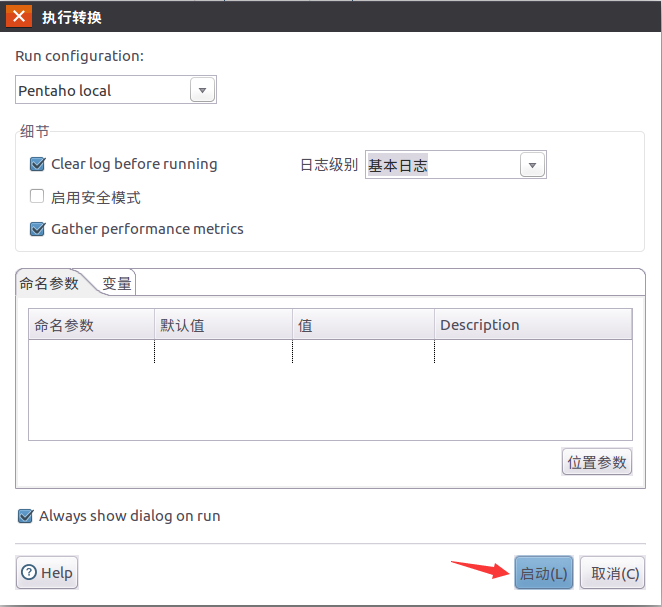
执行完成后出现下列界面表示执行成功。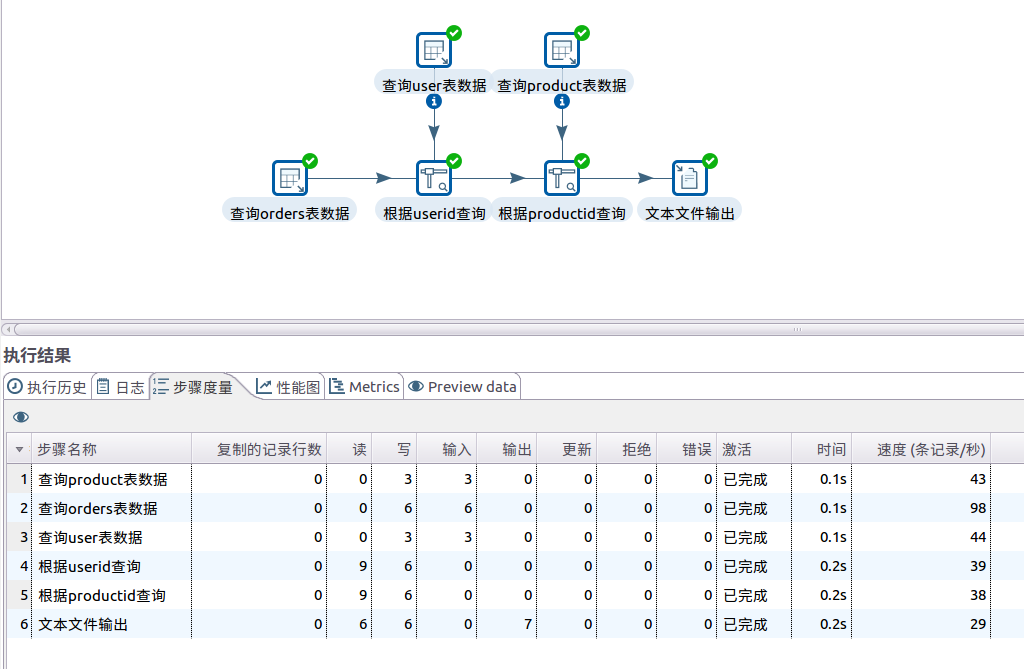
如果出现下列界面表示作业建立出错,可以从日志栏获取相关错误信息。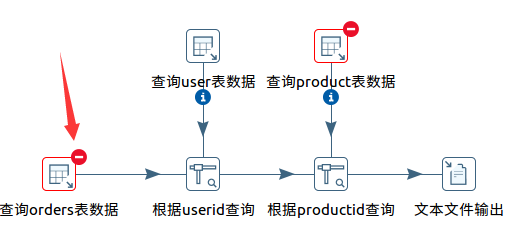
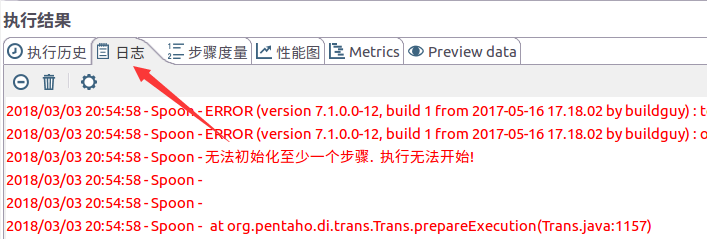
2.2 查看执行结果
如果运行成功,目录/usr/local/kettle/data-integration下生成一个txt文件resultfile.txt,查看resultfile.txt其内容如下,表示执行成功,已经成功将MySQL数据库的这三张表的数据导出为指定格式的文件。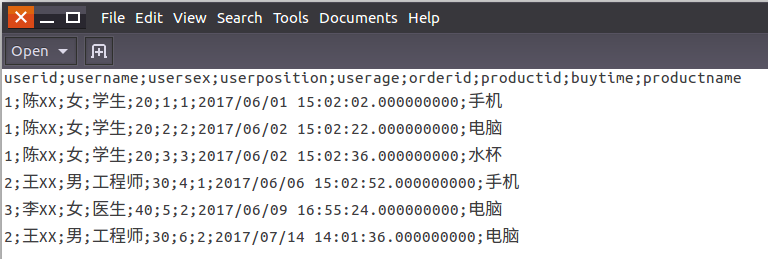
至此我们就完成了将MySQL的数据转化为kettle指定的文件格式,实验成功!