完整代码:https://github.com/zle1992/Reinforcement_Learning_Game

开山之作: 《Playing Atari with Deep Reinforcement Learning》(NIPS)
http://export.arxiv.org/pdf/1312.5602

《Human-level control through deep reinforcementlearnin》 https://www.cs.swarthmore.edu/~meeden/cs63/s15/nature15b.pdf
使用2个网络,减少了相关性,每隔一定时间,替换参数。
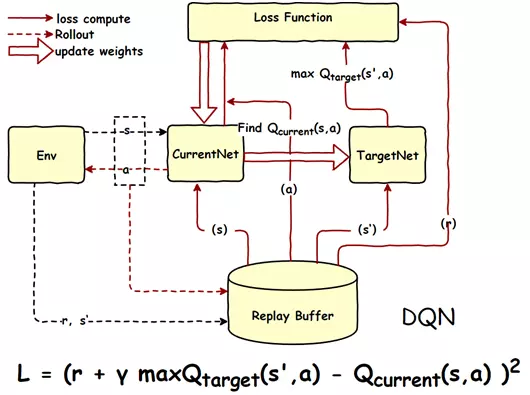
《Deep Reinforcement Learning with Double Q-learning》 https://arxiv.org/pdf/1509.06461.pdf

1 import os 2 import numpy as np 3 import tensorflow as tf 4 from abc import ABCMeta, abstractmethod 5 np.random.seed(1) 6 tf.set_random_seed(1) 7 8 import logging # 引入logging模块 9 logging.basicConfig(level=logging.DEBUG, 10 format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') # logging.basicConfig函数对日志的输出格式及方式做相关配置 11 # 由于日志基本配置中级别设置为DEBUG,所以一下打印信息将会全部显示在控制台上 12 13 tfconfig = tf.ConfigProto() 14 tfconfig.gpu_options.allow_growth = True 15 session = tf.Session(config=tfconfig) 16 17 18 class DoubleDQNet(object): 19 __metaclass__ = ABCMeta 20 """docstring for DeepQNetwork""" 21 def __init__(self, 22 n_actions, 23 n_features, 24 learning_rate, 25 reward_decay, 26 replace_target_iter, 27 memory_size, 28 e_greedy, 29 e_greedy_increment, 30 e_greedy_max, 31 output_graph, 32 log_dir, 33 use_doubleQ , 34 model_dir, 35 ): 36 super(DoubleDQNet, self).__init__() 37 38 self.n_actions = n_actions 39 self.n_features = n_features 40 self.learning_rate=learning_rate 41 self.gamma=reward_decay 42 self.replace_target_iter=replace_target_iter 43 self.memory_size=memory_size 44 self.epsilon=e_greedy 45 self.epsilon_max=e_greedy_max 46 self.epsilon_increment=e_greedy_increment 47 self.output_graph=output_graph 48 self.lr =learning_rate 49 50 self.log_dir = log_dir 51 self.use_doubleQ =use_doubleQ 52 self.model_dir = model_dir 53 # total learning step 54 self.learn_step_counter = 0 55 56 57 self.s = tf.placeholder(tf.float32,[None]+self.n_features,name='s') 58 self.s_next = tf.placeholder(tf.float32,[None]+self.n_features,name='s_next') 59 60 61 62 63 64 self.r = tf.placeholder(tf.float32,[None,],name='r') 65 self.a = tf.placeholder(tf.int32,[None,],name='a') 66 67 68 self.q_eval = self._build_q_net(self.s, scope='eval_net', trainable=True) 69 self.q_next = self._build_q_net(self.s_next, scope='target_net', trainable=False) 70 #self.q_eval4next = tf.stop_gradient(self._build_q_net(self.s_next, scope='eval_net4next', trainable=True)) 71 self.q_eval4next = self._build_q_net(self.s_next, scope='eval_net4next', trainable=False) 72 73 74 75 76 77 78 79 if self.use_doubleQ: 80 81 82 value_i = tf.to_int32(tf.argmax(self.q_eval4next,axis=1)) 83 range_i = tf.range(tf.shape(self.a)[0], dtype=tf.int32) 84 index_a = tf.stack([range_i, value_i], axis=1) 85 86 87 maxq = tf.gather_nd(params=self.q_next,indices=index_a) 88 89 else: 90 maxq = tf.reduce_max(self.q_next, axis=1, name='Qmax_s_') # shape=(None, ) 91 92 93 with tf.variable_scope('q_target'): 94 #只更新最大的那一列 95 self.q_target = self.r + self.gamma * maxq 96 with tf.variable_scope('q_eval'): 97 a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1) 98 self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices) # shape=(None, ) 99 with tf.variable_scope('loss'): 100 self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error')) 101 with tf.variable_scope('train'): 102 self._train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss) 103 104 105 106 t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net') 107 e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net') 108 en_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net4next') 109 110 with tf.variable_scope("hard_replacement"): 111 self.target_replace_op=[tf.assign(t,e) for t,e in zip(t_params,e_params)] 112 113 with tf.variable_scope("hard_replacement2"): 114 self.target_replace_op2=[tf.assign(t,e) for t,e in zip(en_params,e_params)] 115 116 self.sess = tf.Session() 117 if self.output_graph: 118 tf.summary.FileWriter(self.log_dir,self.sess.graph) 119 120 self.sess.run(tf.global_variables_initializer()) 121 122 self.cost_his =[0] 123 self.cost = 0 124 125 self.saver = tf.train.Saver() 126 127 if not os.path.exists(self.model_dir): 128 os.mkdir(self.model_dir) 129 130 checkpoint = tf.train.get_checkpoint_state(self.model_dir) 131 if checkpoint and checkpoint.model_checkpoint_path: 132 self.saver.restore(self.sess, checkpoint.model_checkpoint_path) 133 print ("Loading Successfully") 134 self.learn_step_counter = int(checkpoint.model_checkpoint_path.split('-')[-1]) + 1 135 @abstractmethod 136 def _build_q_net(self,x,scope,trainable): 137 raise NotImplementedError 138 139 def learn(self,data): 140 141 self.sess.run(self.target_replace_op2) 142 # check to replace target parameters 143 if self.learn_step_counter % self.replace_target_iter == 0: 144 self.sess.run(self.target_replace_op) 145 print(' target_params_replaced ') 146 147 batch_memory_s = data['s'] 148 batch_memory_a = data['a'] 149 batch_memory_r = data['r'] 150 batch_memory_s_ = data['s_'] 151 152 153 154 _, cost = self.sess.run( 155 [self._train_op, self.loss], 156 feed_dict={ 157 self.s: batch_memory_s, 158 self.a: batch_memory_a, 159 self.r: batch_memory_r, 160 self.s_next: batch_memory_s_, 161 162 }) 163 #self.cost_his.append(cost) 164 self.cost = cost 165 # increasing epsilon 166 if self.epsilon < self.epsilon_max: 167 self.epsilon += self.epsilon_increment 168 else: 169 self.epsilon = self.epsilon_max 170 171 172 173 self.learn_step_counter += 1 174 # save network every 100000 iteration 175 if self.learn_step_counter % 10000 == 0: 176 self.saver.save(self.sess,self.model_dir,global_step=self.learn_step_counter) 177 178 179 180 def choose_action(self,s): 181 s = s[np.newaxis,:] 182 aa = np.random.uniform() 183 #print("epsilon_max",self.epsilon_max) 184 if aa < self.epsilon: 185 action_value = self.sess.run(self.q_eval,feed_dict={self.s:s}) 186 action = np.argmax(action_value) 187 else: 188 action = np.random.randint(0,self.n_actions) 189 return action
参考:
https://github.com/simoninithomas/Deep_reinforcement_learning_Course
https://github.com/spiglerg/DQN_DDQN_Dueling_and_DDPG_Tensorflow/blob/master/modules/dqn.py