# 爬取河南企业信用信息公示系统为案例
# 案例网址 http://gsxt.haaic.gov.cn/index.jspx
下面这个选项一定要勾选

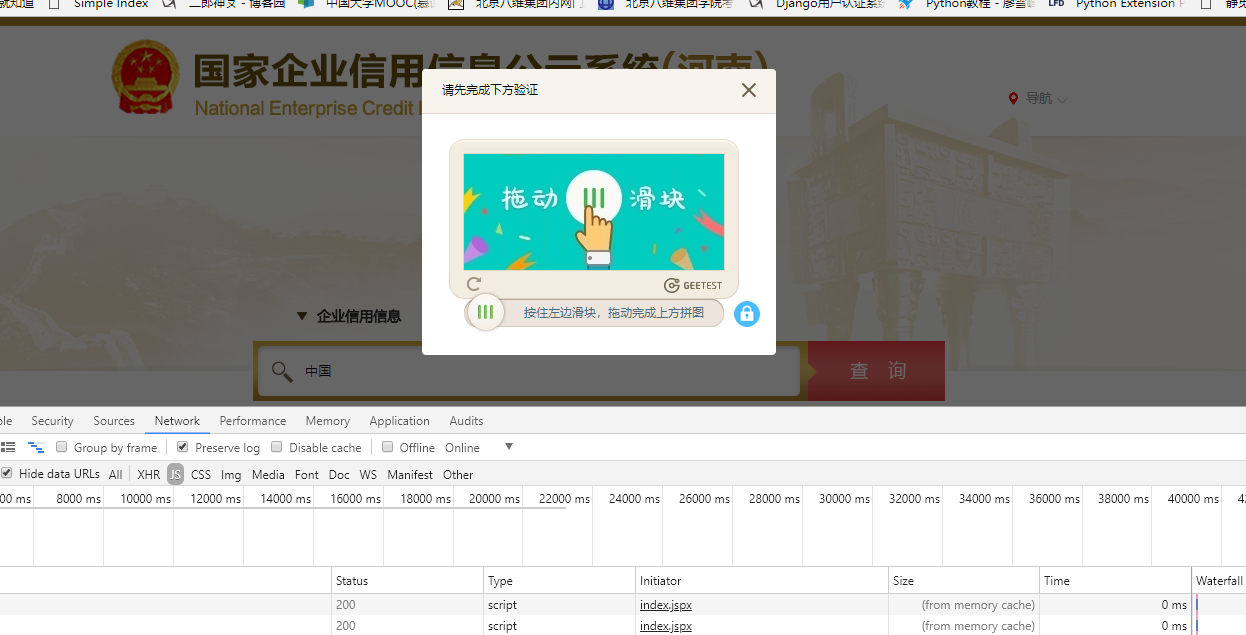
极验打码要的参数

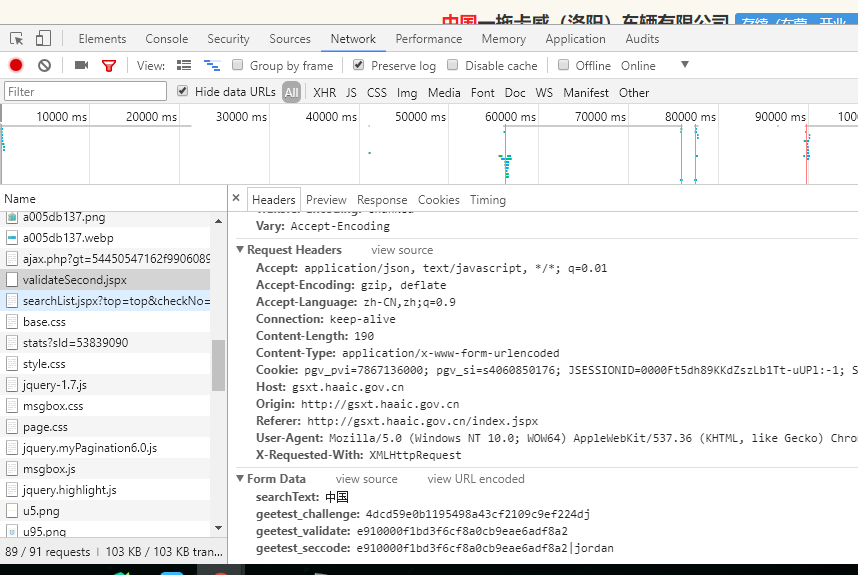
要爬取数据所在的页面
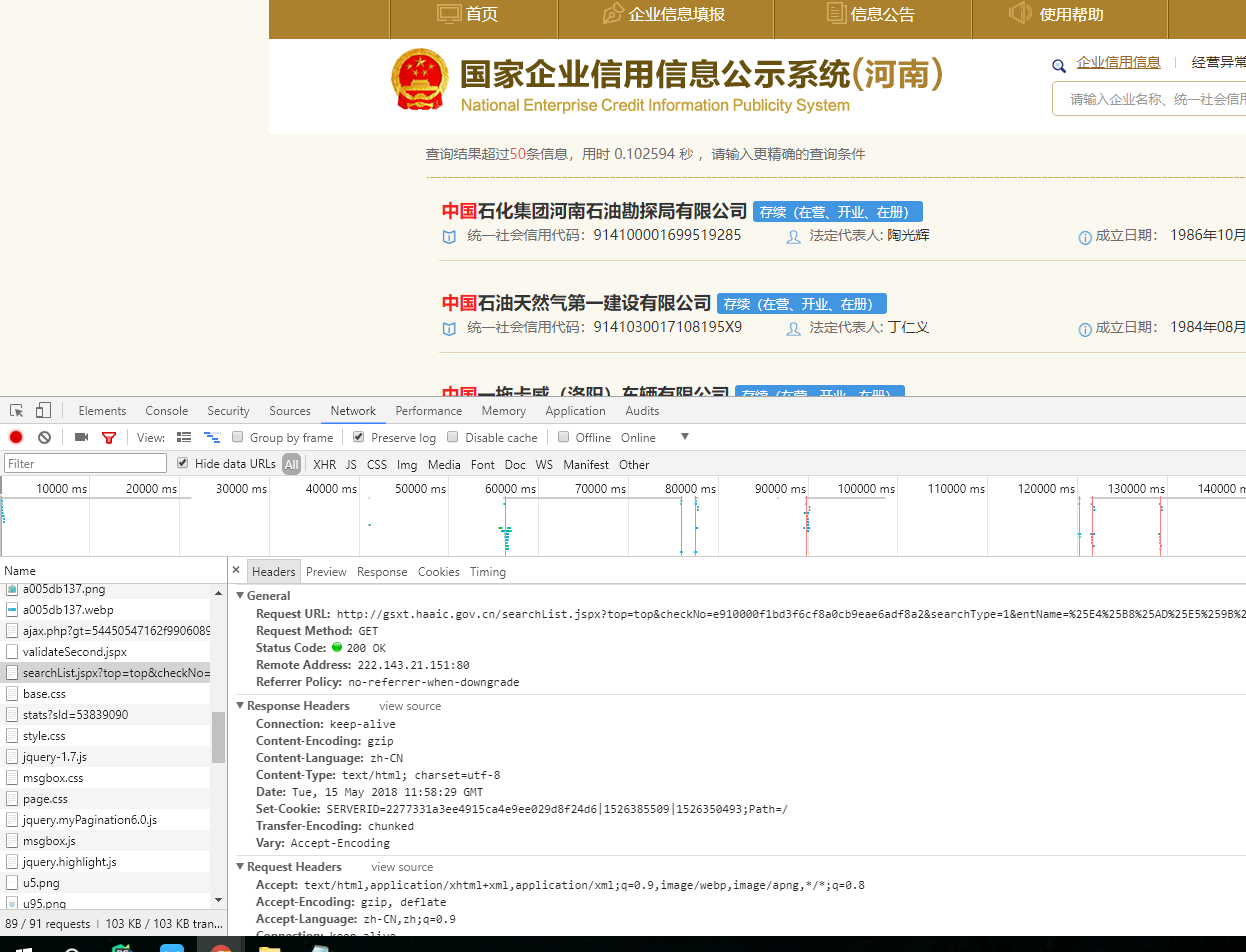
根据上面的截图然后找到相对应的菜蔬 然后下面这个代码就可以实现打印list页面的源代码 ,剩下的就是用解析器解析的部分。
import requests import json from urllib.parse import quote class Qy(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'} self.req = requests.session() def get_html(self,url): try: response = self.req.get(url,headers=self.headers) if response.status_code == 200: return response.text return None except: print('获取challenge和ht信息失败') def parse_html(self,html): html_dic = json.loads(html) url = "http://jiyanapi.c2567.com/shibie?user=username&pass=123456&return=json&ip=>=" + html_dic['gt'] + "&challenge=" + html_dic['challenge'] return self.get_html(url) def get_page_html(self,html_json): url = 'http://gsxt.haaic.gov.cn/validateSecond.jspx' html_dic = json.loads(html_json) data = { 'searchText': '中国', 'geetest_challenge': html_dic['challenge'], 'geetest_validate': html_dic['validate'], 'geetest_seccode': html_dic['validate']+'|jordan', } html = self.req.post(url,headers=self.headers,data=data).text html_di = json.loads(html) name = quote(quote('中国')) url1 = 'http://gsxt.haaic.gov.cn/'+html_di['obj']+'&searchType=1&entName='+name return self.req.get(url,headers=self.headers).text def main(): qy = Qy() # 获取challenge和ht信息 html = qy.get_html('http://gsxt.haaic.gov.cn/registerValidate.jspx') # 使用打码平台进行打码 html_json = qy.parse_html(html) # 获取网页的数据 data = qy.get_page_html(html_json) # 打印网页的数据 print(data) if __name__ == '__main__': main()
