由于需求和资源的限制,将热数据存在tmpfs上(有资源的话可以用SSD),冷数据存在普通磁盘上。
首先说一下一下tmpfs 虚拟内存文件系统:
特点:它的存储空间在VM(virtual memory)。
VM是由linux内核里面的vm子系统管理的,由RM(Real Memory)和swap组成,RM的大小就是物理内存的大小,而Swap的大小是由自己决定的。
Swap是通过硬盘虚拟出来的内存空间,因此它的读写速度相对RM(Real Memory)要慢许多,当一个进程申请一定数量的内存时,如内核的vm子系统发现没有足够的RM时,就会把RM里面的一些不常用的数据交换到Swap里面,如果需要重新使用这些数据再把它们从Swap交换到RM里面。如果有足够大的物理内存,可以不划分Swap分区。
Swap是通过硬盘虚拟出来的内存空间,因此它的读写速度相对RM(Real Memory)要慢许多,当一个进程申请一定数量的内存时,如内核的vm子系统发现没有足够的RM时,就会把RM里面的一些不常用的数据交换到Swap里面,如果需要重新使用这些数据再把它们从Swap交换到RM里面。如果有足够大的物理内存,可以不划分Swap分区。
tmpfs默认的大小是RM的一半,假如你的物理内存是1024M,那么tmpfs默认的大小就是512M。一般情况下,是配置的小于物理内存大小的。
tmpfs配置的大小并不会真正的占用这块内存,如果/dev/shm/下没有任何文件,它占用的内存实际上就是0字节;如果它最大为1G,里头放有100M文件,那剩余的900M仍然可为其它应用程序所使用,但它所占用的100M内存,是不会被系统回收重新划分的。
当删除tmpfs中文件,tmpfs 文件系统驱动程序会动态地减小文件系统并释放 VM 资源。
mount tmpfs /mnt/tmpfs -t tmpfs
默认情况下,tmpfs会mount到/dev/shm目录。使用tmpfs,就是说你可以使用这个目录,这个目录就是tmpfs,如你写临时文件到此目录,这些文件实际上是在VM中。
为防止tmpfs使用了全部VM,有时候要限制其大小。比如要创建一个最大为32 MB的tmpfs文件系统:
mount tmpfs /dev/shm -t tmpfs -o size=32m
mount -t tmpfs none /tmp:所有/tmp目录下的写入其实都写在内存中 。但tmpfs文件系统不知道临时文件系统的可用内存数量改如何限制。所以要为/tmp目录设置指定数量内存:mount -t tmpfs -o size=1g none /tmp(将分配给/tmp目录1G内存空间,这样可以避免/tmp写入超过1G的内容)由于没有挂载之前/tmp目录下的文件也许正在被使用,因此挂载之后系统也许有的程序不能正常工作。可以写入/etc/fstab,这样重启后也有效。
可以通过df -h来查看文件空间使用情况
内存文件系统可以在服务器重启后自动挂载
tmpfs上的数据断电会丢失
方案一:
热数据一个索引(在内存文件中,断电会丢失),所以热数据需要备份一个索引(数据在磁盘中,断电不会丢失)
说明:
说明:
数据量:25,200,002条,热数据中source不写rt_feature字段,共24.5G,热数据备份中source写rt_feature字段,共91G
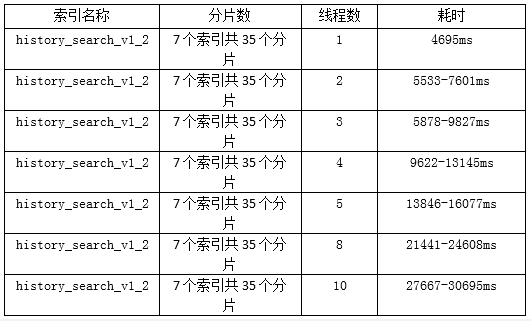
1、分片数及搜索效率
1、分片数及搜索效率
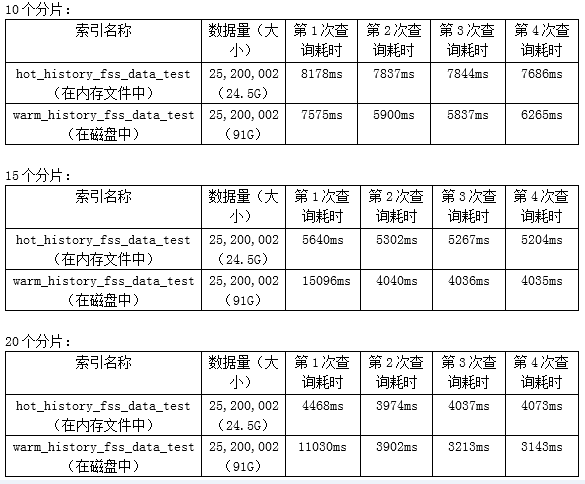
2、数据备份与恢复
如果热数据(hot_history_fss_data_test)丢失,可以从热数据备份中(warm_history_fss_data_test)用reindex的方式进行恢复。
15个分片时,数据恢复耗时12分钟
20个分片时,数据恢复耗时11分钟(如果从磁盘reindex到磁盘(有特征),需要耗时70分钟)
如果热数据(hot_history_fss_data_test)丢失,可以从热数据备份中(warm_history_fss_data_test)用reindex的方式进行恢复。
15个分片时,数据恢复耗时12分钟
20个分片时,数据恢复耗时11分钟(如果从磁盘reindex到磁盘(有特征),需要耗时70分钟)
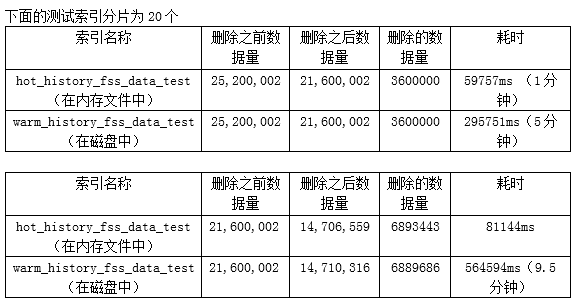
3、数据的删除
因为只有一个索引,所以数据的删除只能先过滤过期的数据,然后将这些数据删除,删除语句如下:
curl -XPOST "http://10.45.157.111:9200/warm_history_fss_data_test2/history_data/_delete_by_query"?pretty -d'{"query":{"bool":{"filter":{"range":{"enter_time":{"gt":"2016-07-01 00:00:00","lt":"2016-07-01 00:00:00||+1M","format":"yyyy-MM-dd HH:mm:ss","time_zone":"+08:00"}}}}}}'
因为只有一个索引,所以数据的删除只能先过滤过期的数据,然后将这些数据删除,删除语句如下:
curl -XPOST "http://10.45.157.111:9200/warm_history_fss_data_test2/history_data/_delete_by_query"?pretty -d'{"query":{"bool":{"filter":{"range":{"enter_time":{"gt":"2016-07-01 00:00:00","lt":"2016-07-01 00:00:00||+1M","format":"yyyy-MM-dd HH:mm:ss","time_zone":"+08:00"}}}}}}'
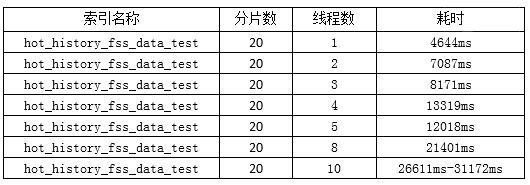
4、并发性
方案二:热数据采用滚动建索引的方式,每400万数据创建一个新的索引,每个索引5个分片
25,200,002条数据滚动建索引的情况如下:
hot_history_fss_data_test-00001:4,039,000 (3.96G)
hot_history_fss_data_test-00002:4,089,000(4.01G)
hot_history_fss_data_test-00003:4,024,000(3.95)
hot_history_fss_data_test-00004:4,045,000 (3.97G)
hot_history_fss_data_test-00005:4,047,000(3.97G)
hot_history_fss_data_test-00006:4,050,000(3.97G)
hot_history_fss_data_test-00007:906,002(921M)
上述索引有一个共同的索引别名:history_search_v1_2
25,200,002条数据滚动建索引的情况如下:
hot_history_fss_data_test-00001:4,039,000 (3.96G)
hot_history_fss_data_test-00002:4,089,000(4.01G)
hot_history_fss_data_test-00003:4,024,000(3.95)
hot_history_fss_data_test-00004:4,045,000 (3.97G)
hot_history_fss_data_test-00005:4,047,000(3.97G)
hot_history_fss_data_test-00006:4,050,000(3.97G)
hot_history_fss_data_test-00007:906,002(921M)
上述索引有一个共同的索引别名:history_search_v1_2
1、搜索效率

2、数据的备份与恢复
热数据的备份和热数据一样,也是滚动创建索引,数据恢复时,每一个索引都进行reindex,由于两份数据时同时写的,一个在内存中一个在磁盘中,写入的速度不一样,创建新索引的时间也不一样,可能两份数据会有一些误差,但对实际使用应该没有很大的影响。
热数据的备份和热数据一样,也是滚动创建索引,数据恢复时,每一个索引都进行reindex,由于两份数据时同时写的,一个在内存中一个在磁盘中,写入的速度不一样,创建新索引的时间也不一样,可能两份数据会有一些误差,但对实际使用应该没有很大的影响。
3、数据的删除
由于是滚动创建了多个索引,所以数据删除时可以直接删除整个索引,用ES提供的curator可以完成滚动创建和删除的功能
curator --config /home/czl/tmpfs/curator/curator.yml /home/czl/tmpfs/curator/rollover_action_file.yml>>/home/czl/tmpfs/curator/create-Index.log 2>&1
由于是滚动创建了多个索引,所以数据删除时可以直接删除整个索引,用ES提供的curator可以完成滚动创建和删除的功能
curator --config /home/czl/tmpfs/curator/curator.yml /home/czl/tmpfs/curator/rollover_action_file.yml>>/home/czl/tmpfs/curator/create-Index.log 2>&1
4、并发性