不多说,直接上代码。
MapReduce 计数器是什么?
计数器是用来记录job的执行进度和状态的。它的作用可以理解为日志。我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况。
MapReduce 计数器能做什么?
MapReduce 计数器(Counter)为我们提供一个窗口,用于观察 MapReduce Job 运行期的各种细节数据。对 MapReduce 性能调优很有帮助,MapReduce 性能优化的评估大部分都是基于这些 Counter 的数值表现出来的。
MapReduce 都有哪些内置计数器?
MapReduce 自带了许多默认 Counter,现在我们来分析这些默认 Counter 的含义,方便大家观察 Job 结果,如输入的字节数、输出的字节数、Map 端 输入/输出的字节数和条数、Reduce 端的输入/输出的字节数和条数等。下面我们只需了解这些内置计数器,知道计数器组名称(groupName)和计数器名称(counterName),以后使用计数器会查找groupName和counterName即可。
任务计数器
在任务执行过程中,任务计数器采集任务的相关信息,每个作业的所有任务的结果会被聚集起来。例如,MAP_INPUT_RECORDS 计数器统计每个 map 任务输入记录的总数, 并在一个作业的所有 map 任务上进行聚集,使得最终数字是整个作业的所有输入记录的总数。任务计数器由其关联任务维护,并定期发送给 TaskTracker,再由 TaskTracker 发送给 JobTracker。因此,计数器能够被全局地聚集。下面我们分别了解各种任务计数器。
1、MapReduce 任务计数器
MapReduce 任务计数器的 groupName为org.apache.hadoop.mapreduce.TaskCounter,它包含的计数器如下表所示,计数器名称列的括号()内容即为counterName。
| 计数器名称 |
说明 |
|---|
| map 输入的记录数(MAP_INPUT_RECORDS) | 作业中所有 map 已处理的输入记录数。每次 RecorderReader 读到一条记录并将其传给 map 的 map() 函数时,该计数器的值增加。 |
| map 跳过的记录数(MAP_SKIPPED_RECORDS) | 作业中所有 map 跳过的输入记录数。 |
| map 输入的字节数(MAP_INPUT_BYTES) | 作业中所有 map 已处理的未经压缩的输入数据的字节数。每次 RecorderReader 读到一条记录并 将其传给 map 的 map() 函数时,该计数器的值增加。 |
| 分片(split)的原始字节数(SPLIT_RAW_BYTES) | 由 map 读取的输入-分片对象的字节数。这些对象描述分片元数据(文件的位移和长度),而不是分片的数据自身,因此总规模是小的。 |
| map 输出的记录数(MAP_OUTPUT_RECORDS) | 作业中所有 map 产生的 map 输出记录数。每次某一个 map 的Context 调用 write() 方法时,该计数器的值增加。 |
| map 输出的字节数(MAP_OUTPUT_BYTES) | 作业中所有 map 产生的 未经压缩的输出数据的字节数。每次某一个 map 的 Context 调用 write() 方法时,该计数器的值增加。 |
| map 输出的物化字节数(MAP_OUTPUT_MATERIALIZED_BYTES) | map 输出后确实写到磁盘上的字节数;若 map 输出压缩功能被启用,则会在计数器值上反映出来。 |
| combine 输入的记录数(COMBINE_INPUT_RECORDS) | 作业中所有 Combiner(如果有)已处理的输入记录数。Combiner 的迭代器每次读一个值,该计数器的值增加。 |
| combine 输出的记录数(COMBINE_OUTPUT_RECORDS) | 作业中所有 Combiner(如果有)已产生的输出记录数。每当一个 Combiner 的 Context 调用 write() 方法时,该计数器的值增加。 |
| reduce 输入的组(REDUCE_INPUT_GROUPS) | 作业中所有 reducer 已经处理的不同的码分组的个数。每当某一个 reducer 的 reduce() 被调用时,该计数器的值增加。 |
| reduce 输入的记录数(REDUCE_INPUT_RECORDS) | 作业中所有 reducer 已经处理的输入记录的个数。每当某个 reducer 的迭代器读一个值时,该计数器的值增加。如果所有 reducer 已经处理完所有输入, 则该计数器的值与计数器 “map 输出的记录” 的值相同。 |
| reduce 输出的记录数(REDUCE_OUTPUT_RECORDS) | 作业中所有 map 已经产生的 reduce 输出记录数。每当某一个 reducer 的 Context 调用 write() 方法时,该计数器的值增加。 |
| reduce 跳过的组数(REDUCE_SKIPPED_GROUPS) | 作业中所有 reducer 已经跳过的不同的码分组的个数。 |
| reduce 跳过的记录数(REDUCE_SKIPPED_RECORDS) | 作业中所有 reducer 已经跳过输入记录数。 |
| reduce 经过 shuffle 的字节数(REDUCE_SHUFFLE_BYTES) | shuffle 将 map 的输出数据复制到 reducer 中的字节数。 |
| 溢出的记录数(SPILLED_RECORDS) | 作业中所有 map和reduce 任务溢出到磁盘的记录数。 |
| CPU 毫秒(CPU_MILLISECONDS) | 总计的 CPU 时间,以毫秒为单位,由/proc/cpuinfo获取 |
| 物理内存字节数(PHYSICAL_MEMORY_BYTES) | 一个任务所用物理内存的字节数,由/proc/cpuinfo获取 |
| 虚拟内存字节数(VIRTUAL_MEMORY_BYTES) | 一个任务所用虚拟内存的字节数,由/proc/cpuinfo获取 |
| 有效的堆字节数(COMMITTED_HEAP_BYTES) | 在 JVM 中的总有效内存量(以字节为单位),可由 Runtime().getRuntime().totaoMemory()获取。 |
| GC 运行时间毫秒数(GC_TIME_MILLIS) | 在任务执行过程中,垃圾收集器(garbage collection)花费的时间(以毫秒为单位), 可由 GarbageCollector MXBean.getCollectionTime()获取;该计数器并未出现在1.x版本中。 |
| 由 shuffle 传输的 map 输出数(SHUFFLED_MAPS) | 有 shuffle 传输到 reducer 的 map 输出文件数。 |
| 失败的 shuffle 数(SHUFFLE_MAPS) | 在 shuffle 过程中,发生拷贝错误的 map 输出文件数,该计数器并没有包含在 1.x 版本中。 |
| 被合并的 map 输出数 | 在 shuffle 过程中,在 reduce 端被合并的 map 输出文件数,该计数器没有包含在 1.x 版本中。 |
2、文件系统计数器
文件系统计数器的 groupName为org.apache.hadoop.mapreduce.FileSystemCounter,它包含的计数器如下表所示,计数器名称列的括号()内容即为counterName。
| 计数器名称 | 说明 |
|---|
| 文件系统的读字节数(BYTES_READ) | 由 map 和 reduce 等任务在各个文件系统中读取的字节数,各个文件系统分别对应一个计数器,可以是 Local、HDFS、S3和KFS等。 |
| 文件系统的写字节数(BYTES_WRITTEN) | 由 map 和 reduce 等任务在各个文件系统中写的字节数。 |
3、FileInputFormat 计数器
FileInputFormat 计数器的 groupName为org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter,它包含的计数器如下表所示,计数器名称列的括号()内容即为counterName。
| 计数器名称 | 说明 |
|---|
| 读取的字节数(BYTES_READ) | 由 map 任务通过 FileInputFormat 读取的字节数。 |
4、FileOutputFormat 计数器
FileOutputFormat 计数器的 groupName为org.apache.hadoop.mapreduce.lib.input.FileOutputFormatCounter,它包含的计数器如下表所示,计数器名称列的括号()内容即为counterName。
| 计数器名称 | 说明 |
|---|
| 写的字节数(BYTES_WRITTEN) | 由 map 任务(针对仅含 map 的作业)或者 reduce 任务通过 FileOutputFormat 写的字节数。 |
作业计数器
作业计数器由 JobTracker(或者 YARN 中的应用宿主)维护,因此无需在网络间传输数据,这一点与包括 “用户定义的计数器” 在内的其它计数器不同。这些计数器都是作业级别的统计量,其值不会随着任务运行而改变。 作业计数器计数器的 groupName为org.apache.hadoop.mapreduce.JobCounter,它包含的计数器如下表所示,计数器名称列的括号()内容即为counterName。
| 计数器名称 | 说明 |
|---|
| 启用的 map 任务数(TOTAL_LAUNCHED_MAPS) | 启动的 map 任务数,包括以 “推测执行” 方式启动的任务。 |
| 启用的 reduce 任务数(TOTAL_LAUNCHED_REDUCES) | 启动的 reduce 任务数,包括以 “推测执行” 方式启动的任务。 |
| 失败的 map 任务数(NUM_FAILED_MAPS) | 失败的 map 任务数。 |
| 失败的 reduce 任务数(NUM_FAILED_REDUCES) | 失败的 reduce 任务数。 |
| 数据本地化的 map 任务数(DATA_LOCAL_MAPS) | 与输入数据在同一节点的 map 任务数。 |
| 机架本地化的 map 任务数(RACK_LOCAL_MAPS) | 与输入数据在同一机架范围内、但不在同一节点上的 map 任务数。 |
| 其它本地化的 map 任务数(OTHER_LOCAL_MAPS) | 与输入数据不在同一机架范围内的 map 任务数。由于机架之间的宽带资源相对较少,Hadoop 会尽量让 map 任务靠近输入数据执行,因此该计数器值一般比较小。 |
| map 任务的总运行时间(SLOTS_MILLIS_MAPS) | map 任务的总运行时间,单位毫秒。该计数器包括以推测执行方式启动的任务。 |
| reduce 任务的总运行时间(SLOTS_MILLIS_REDUCES) | reduce任务的总运行时间,单位毫秒。该值包括以推测执行方式启动的任务。 |
| 在保留槽之后,map 任务等待的总时间(FALLOW_SLOTS_MILLIS_MAPS) | 在为 map 任务保留槽之后所花费的总等待时间,单位是毫秒。 |
| 在保留槽之后,reduce 任务等待的总时间(FALLOW_SLOTS_MILLIS_REDUCES) | 在为 reduce 任务保留槽之后,花在等待上的总时间,单位为毫秒 |
计数器的该如何使用?
下面我们来介绍如何使用计数器。
1、定义计数器
1)枚举声明计数器
Context context... //自定义枚举变量Enum Counter counter = context.getCounter(Enum enum)
2)自定义计数器
Context context... //自己命名groupName和counterName Counter counter = context.getCounter(String groupName,String counterName)
2、为计数器赋值
1)初始化计数器
counter.setValue(long value);//设置初始值
2)计数器自增
counter.increment(long incr);//增加计数
3、获取计数器的值
1) 获取枚举计数器的值
Job job...
job.waitForCompletion(true);
Counters counters=job.getCounters();
Counter counter=counters.findCounter("BAD_RECORDS");//查找枚举计数器,假如Enum的变量为BAD_RECORDS
long value=counter.getValue();//获取计数值
2) 获取自定义计数器的值
Job job...
job.waitForCompletion(true);
Counters counters=job.getCounters();
Counter counter=counters.findCounter("ErrorCounter","toolong");//假如groupName为ErrorCounter,counterName为toolong
long value=counter.getValue();//获取计数值
3) 获取内置计数器的值



代码
package zhouls.bigdata.myMapReduce.MyCounter;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MyCounter extends Configured implements Tool
{
public static class MyCounterMap extends Mapper <LongWritable, Text, Text, Text>
{
// 定义枚举对象
public static enum LOG_PROCESSOR_COUNTER
{//枚举对象BAD_RECORDS_LONG来统计长数据,枚举对象BAD_RECORDS_SHORT来统计短数据
BAD_RECORDS_LONG,BAD_RECORDS_SHORT
};
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException
{
String arr_value[] = value.toString().split("/t");
if (arr_value.length > 3)
{
/*动态自定义计数器*/
context.getCounter("ErrorCounter", "toolong").increment(1);
/*枚举声明计数器*/
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_LONG).increment(1);
} else if (arr_value.length < 3)
{
// 动态自定义计数器
context.getCounter("ErrorCounter", "tooshort").increment(1);
// 枚举声明计数器
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_SHORT).increment(1);
} else
{
context.write(value, new Text(""));
}
}
}
public int run(String[] args) throws Exception
{
//TODO Auto-generated method stub
Configuration conf=new Configuration();
Path mypath=new Path(args[1]);
FileSystem hdfs =mypath.getFileSystem(conf);
if(hdfs.isDirectory(mypath))
{
hdfs.delete(mypath,true);
}
Job job = new Job(conf, "MyCounter");
job.setJarByClass(MyCounter.class);
job.setMapperClass(MyCounterMap.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception
{
// String[] args0 ={"hdfs://HadoopMaster:9000/counter/counter.txt",
// "hdfs://HadoopMaster:9000/out/counter"};
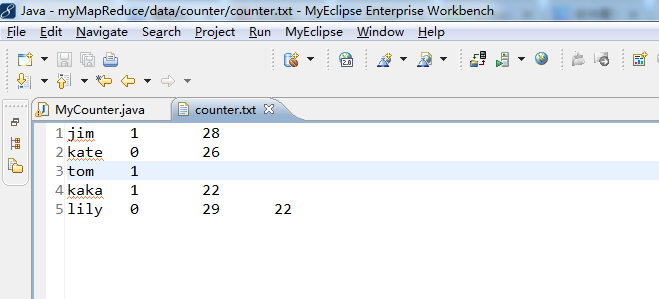
String[] args0 ={"./data/counter/counter.txt",
"./out/counter"};
int ec = ToolRunner.run(new Configuration(),new MyCounter(),args0);
System.exit(ec);
}
}