不多说,直接上干货!
前言
其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来。
本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程。
好一段时间之前,写过这篇博客
使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
最近开始进行更新,希望能帮助到开发的你。
下载源码
去github官网 下载
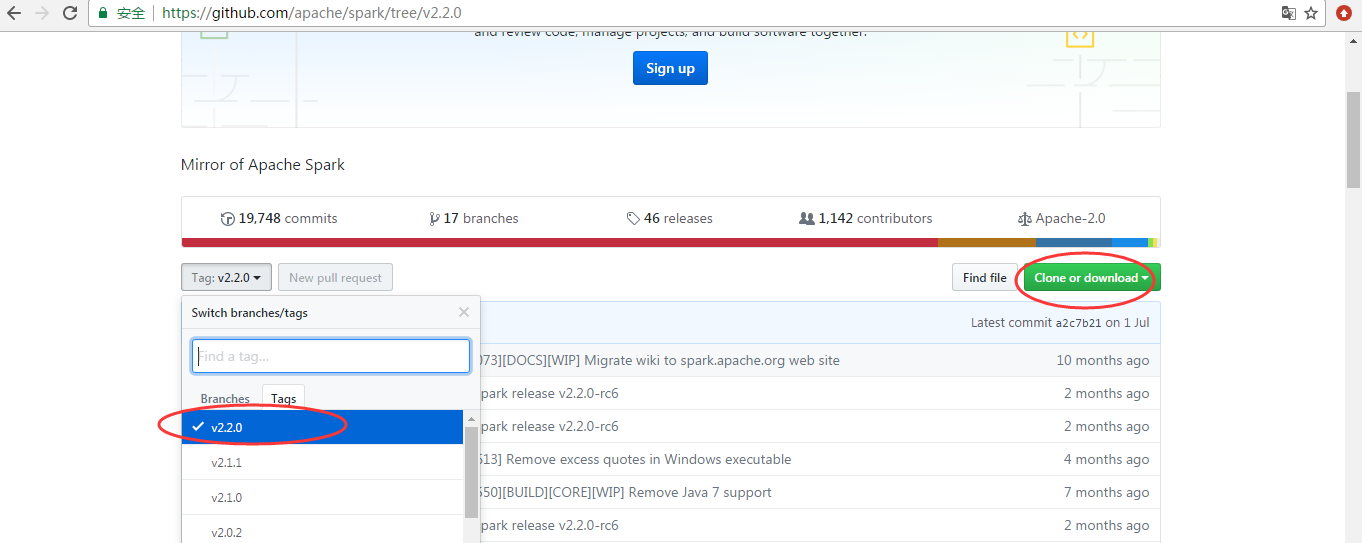

spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse适用)(以spark2.2.0源码包为例)
然后解压缩为目录,scalaIDE不支持tgz的文件关联,只支持jar,zip。
那么就 使用文件目录关联就可以了,关联spark2.0的目录就可以了,很简单。
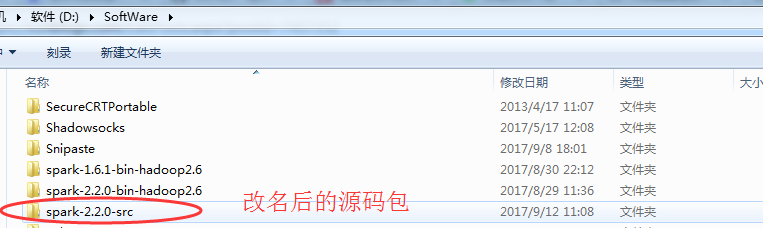
比如,我这里放在D:SoftWare
我这里为了区分,自己改名为spark-2.2.0-src
spark最新源码下载并导入到开发环境下助推高质量代码(IntelliJ IDEA适用)(以spark2.2.0源码包为例)
前期博客,见
如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(图文详解)

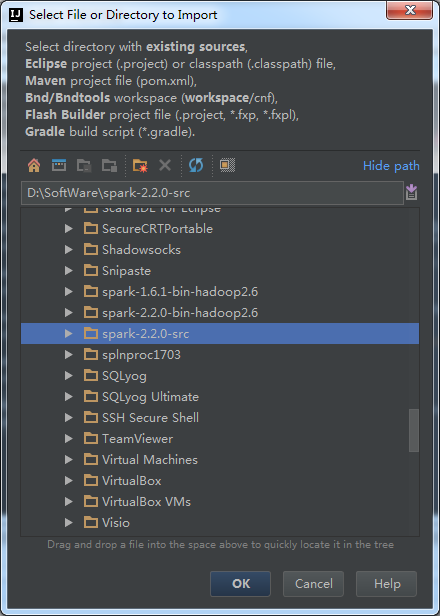
方式1
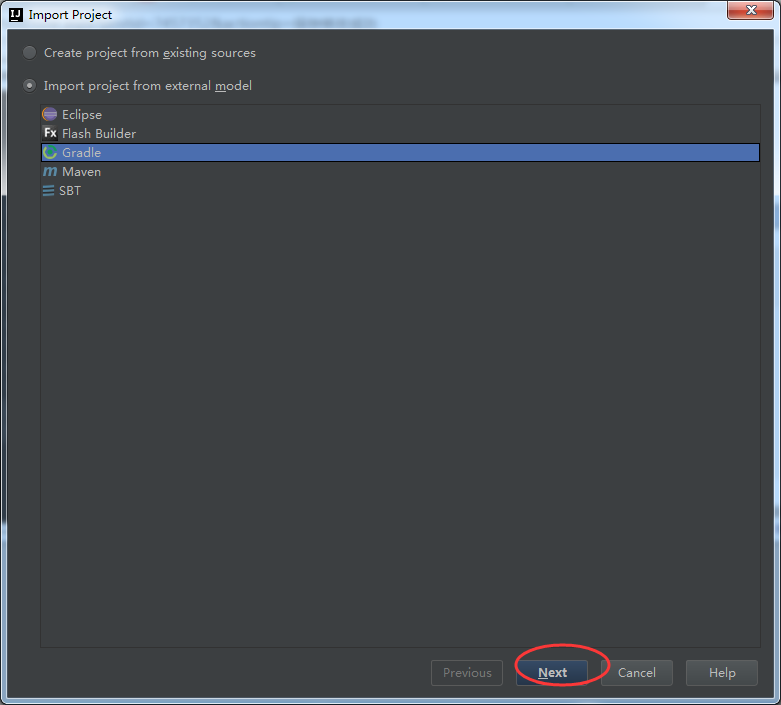
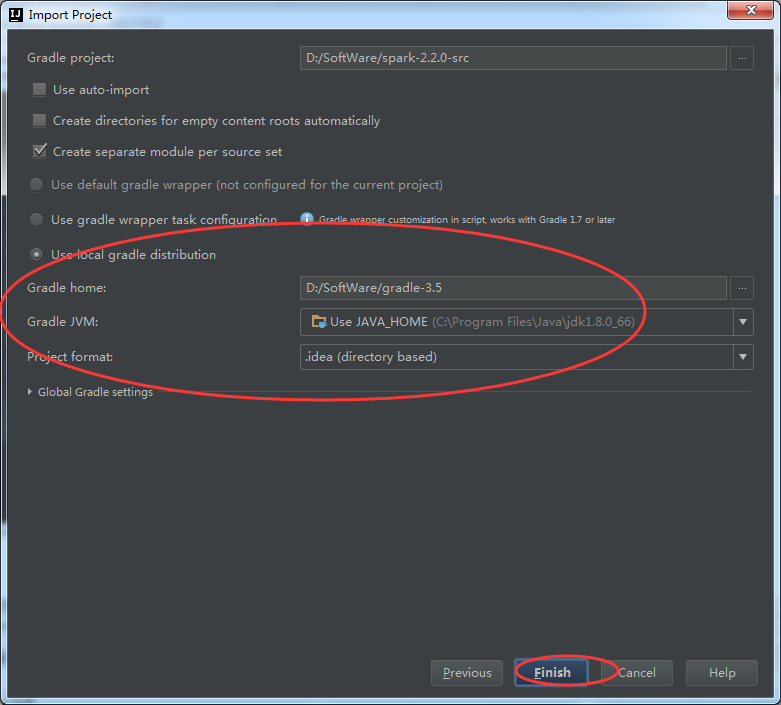
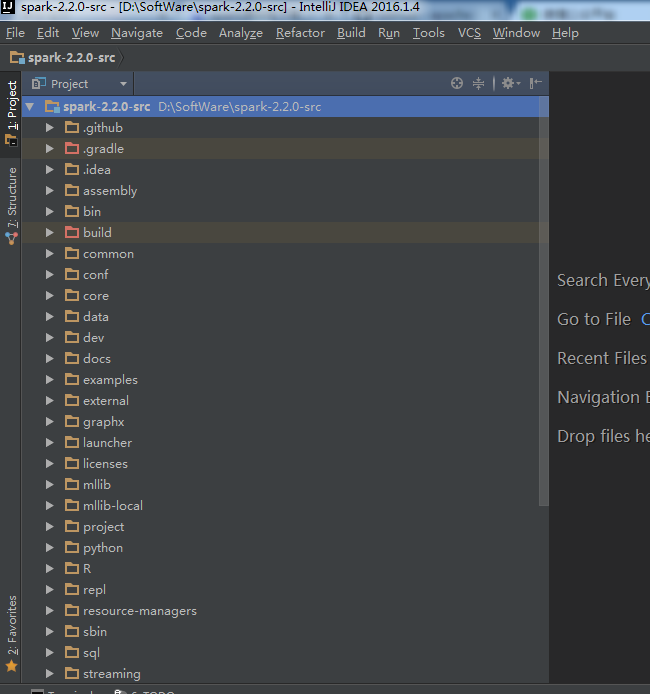
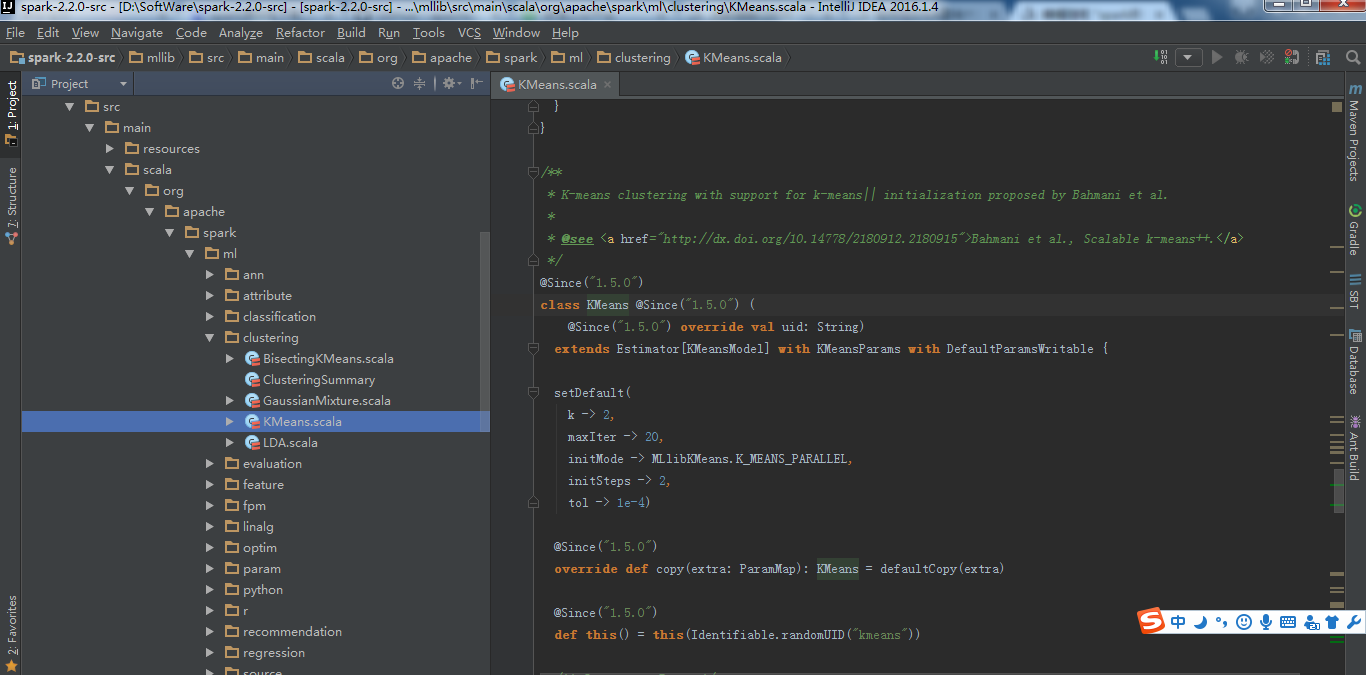
方式2
如果是maven方式来导入源码的话
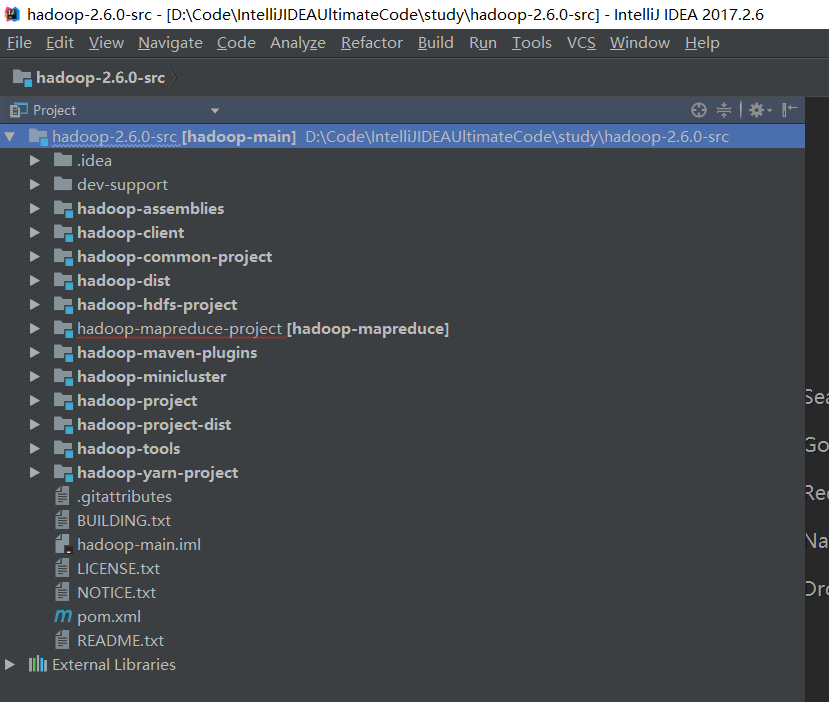
点击进去,为什么会报红错误,maven没改

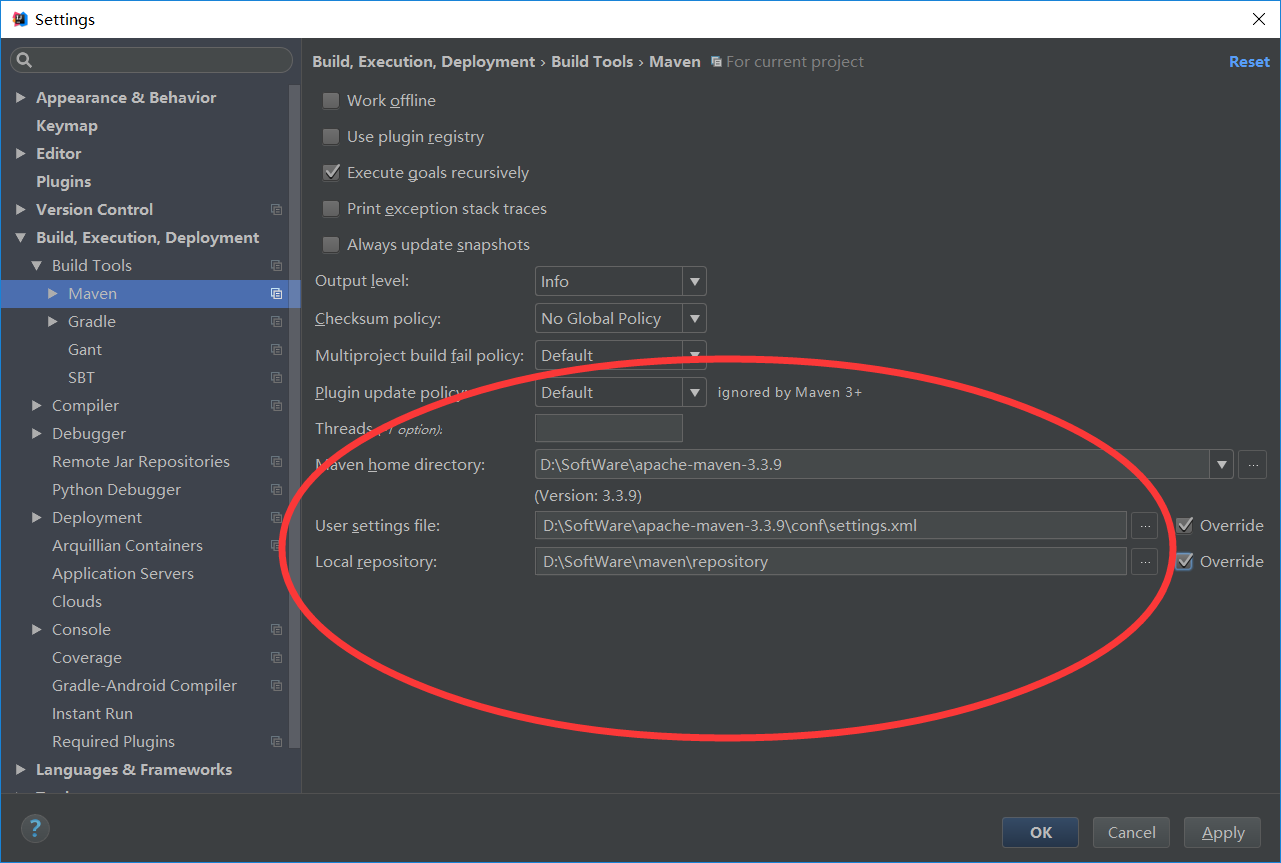
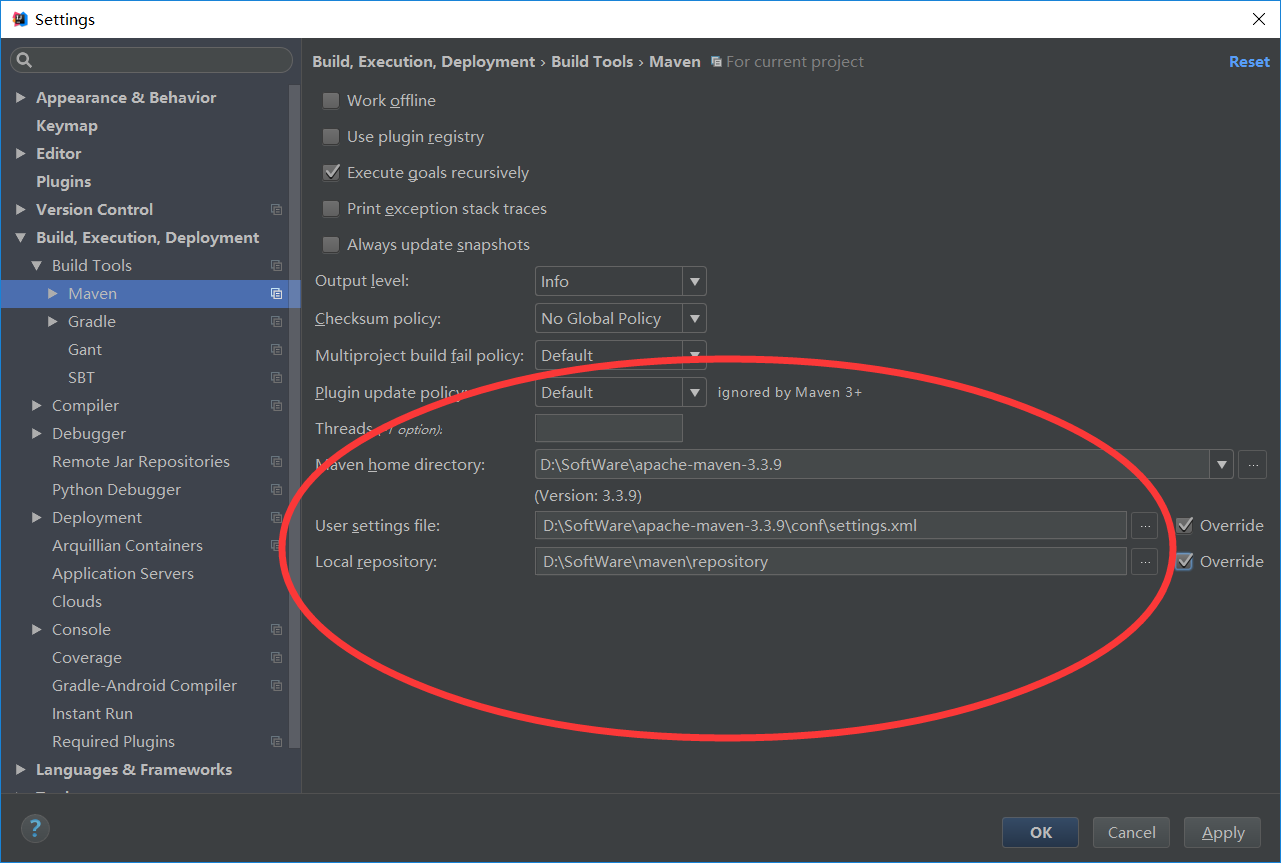
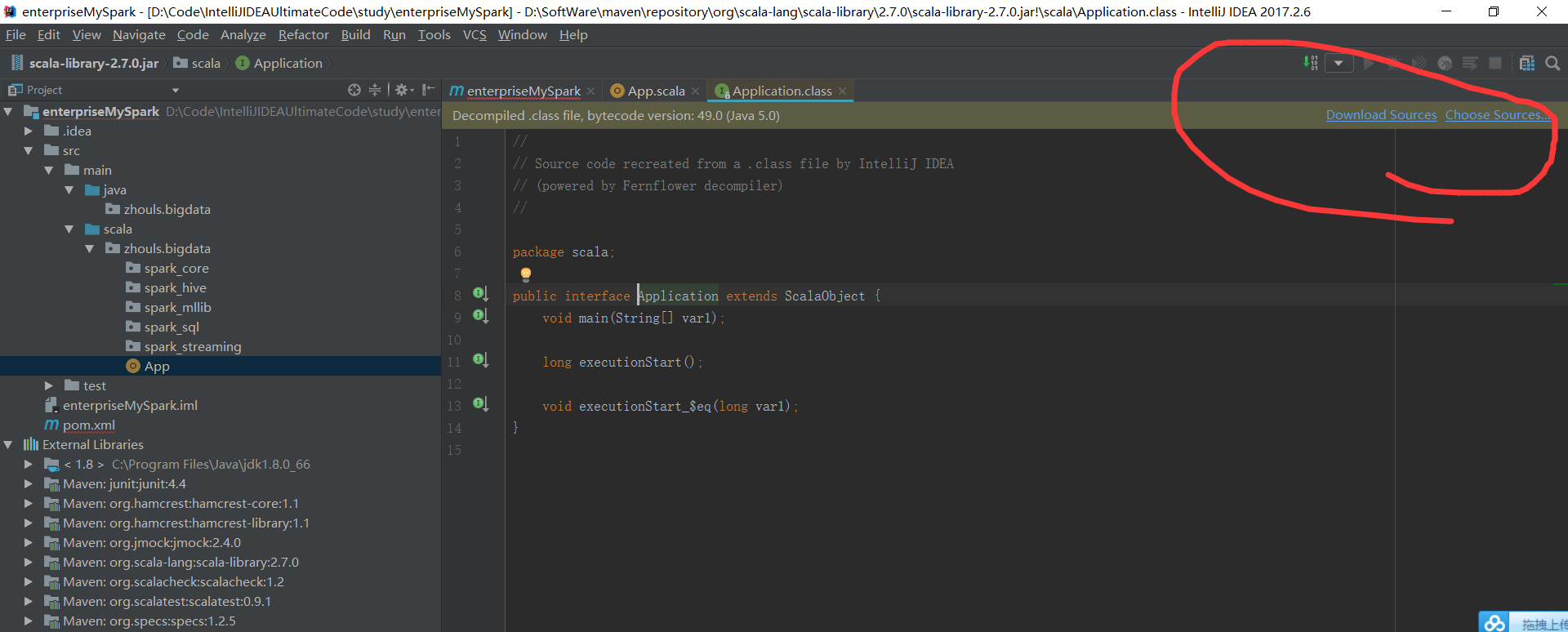
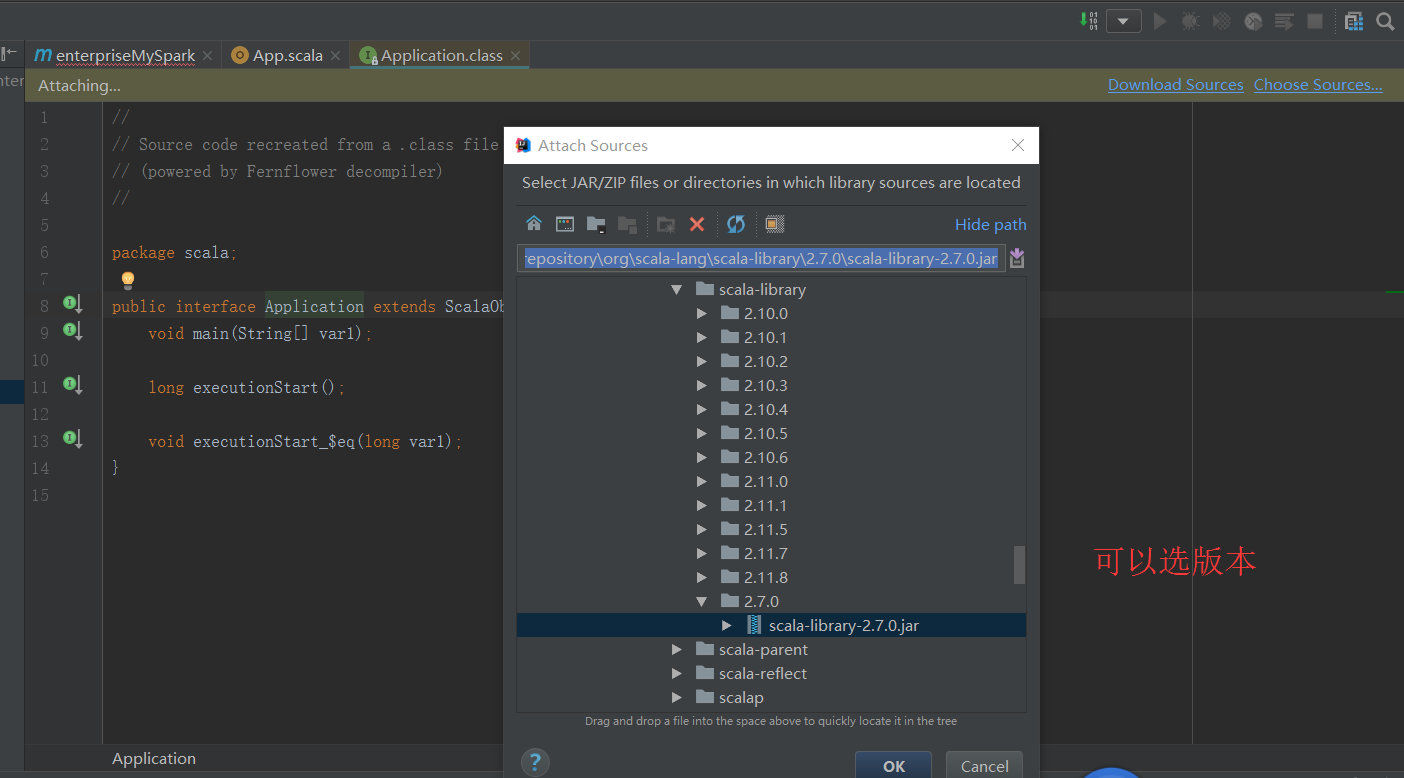
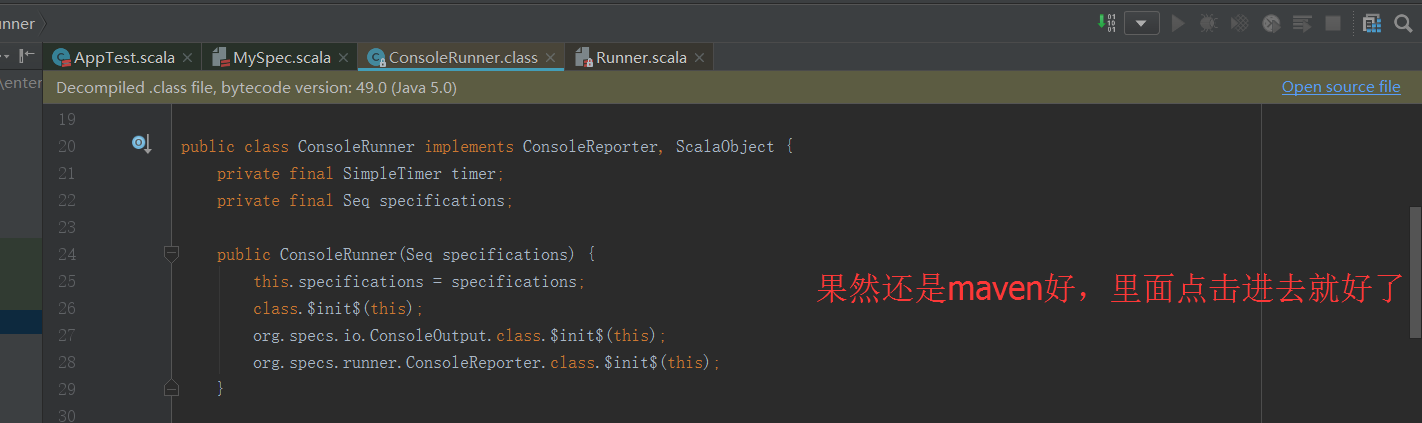
所以,个人建议,还是maven方式好啊
方式3
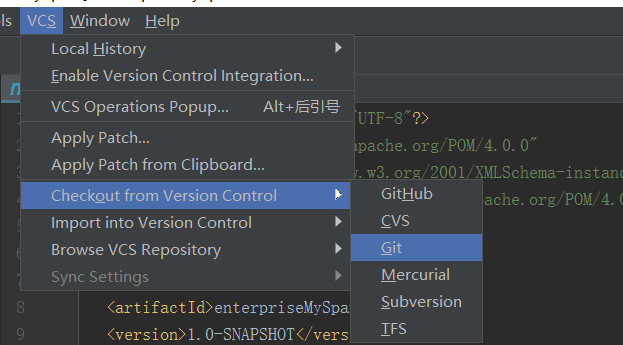
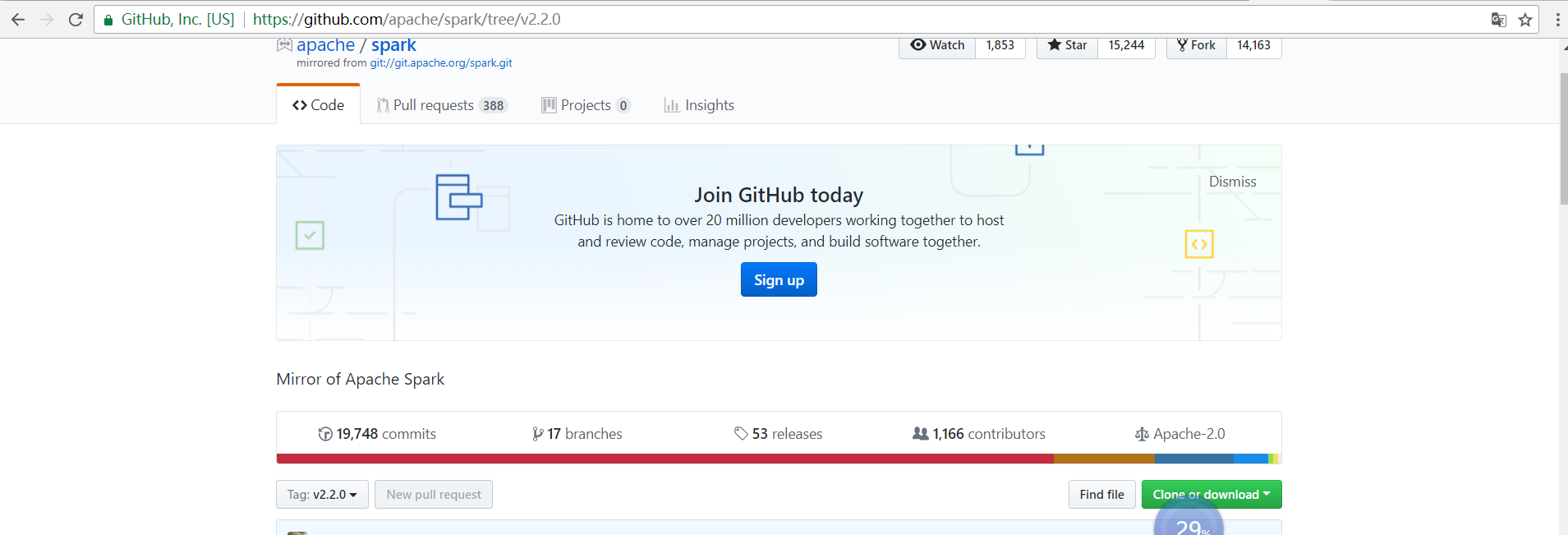
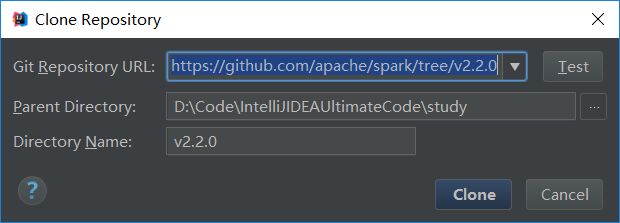
如果是Scala IDEA for Eclipse,则比如把spark-1.6.1
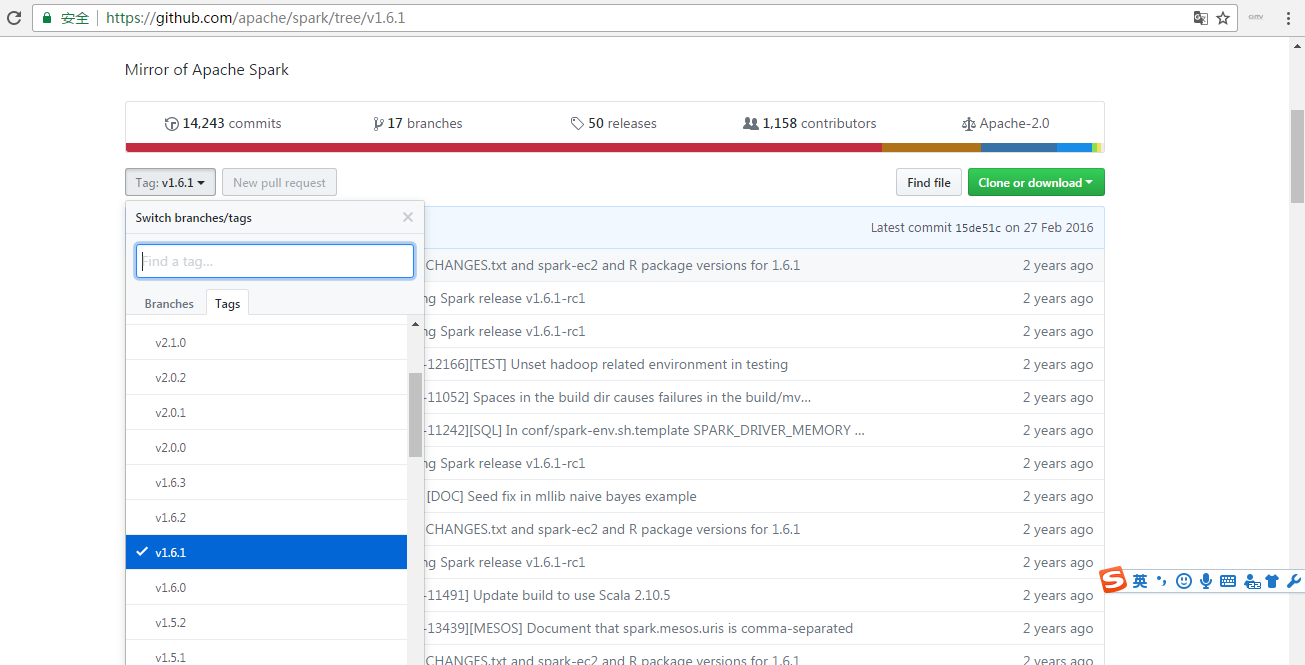
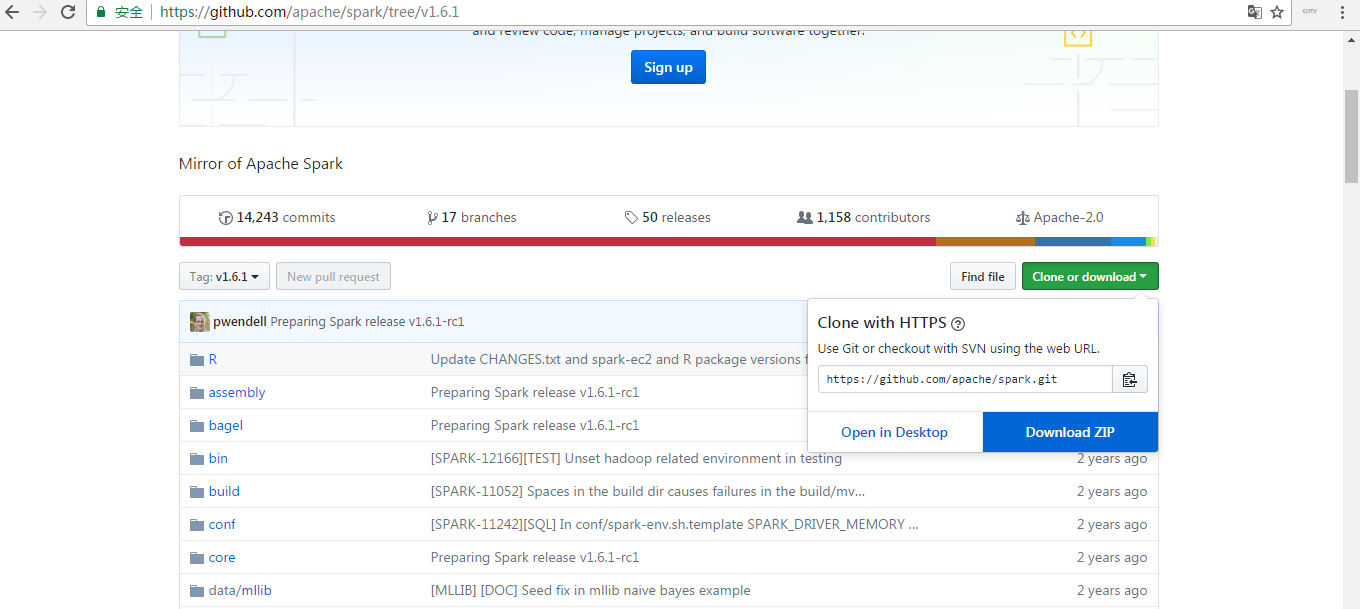
经过解压,我这里特意改下名字,为spark-1.6.1-src
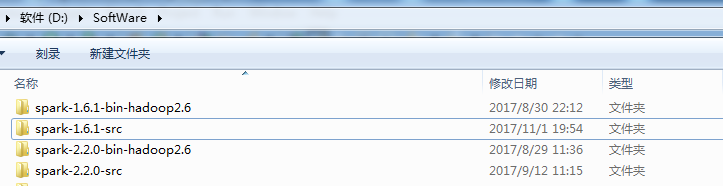
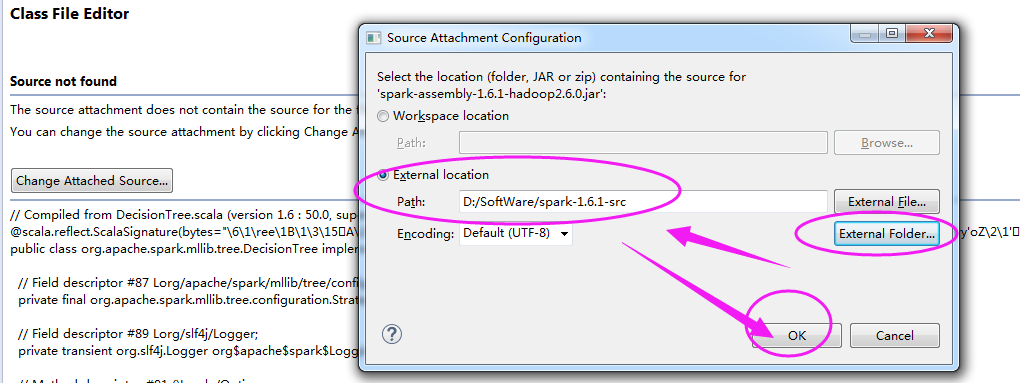
注意:这不局限于spark,比如Hadoop、Hive、HBase....等其他大数据组件的源码一样的步骤,这里不多赘述。当然其他人肯定也有其他的步骤来阅读。
比如,说在IDEA里可以直接点击进去,maven会自动下载等,这个我不多评论。