不多说,直接上干货!
首先,
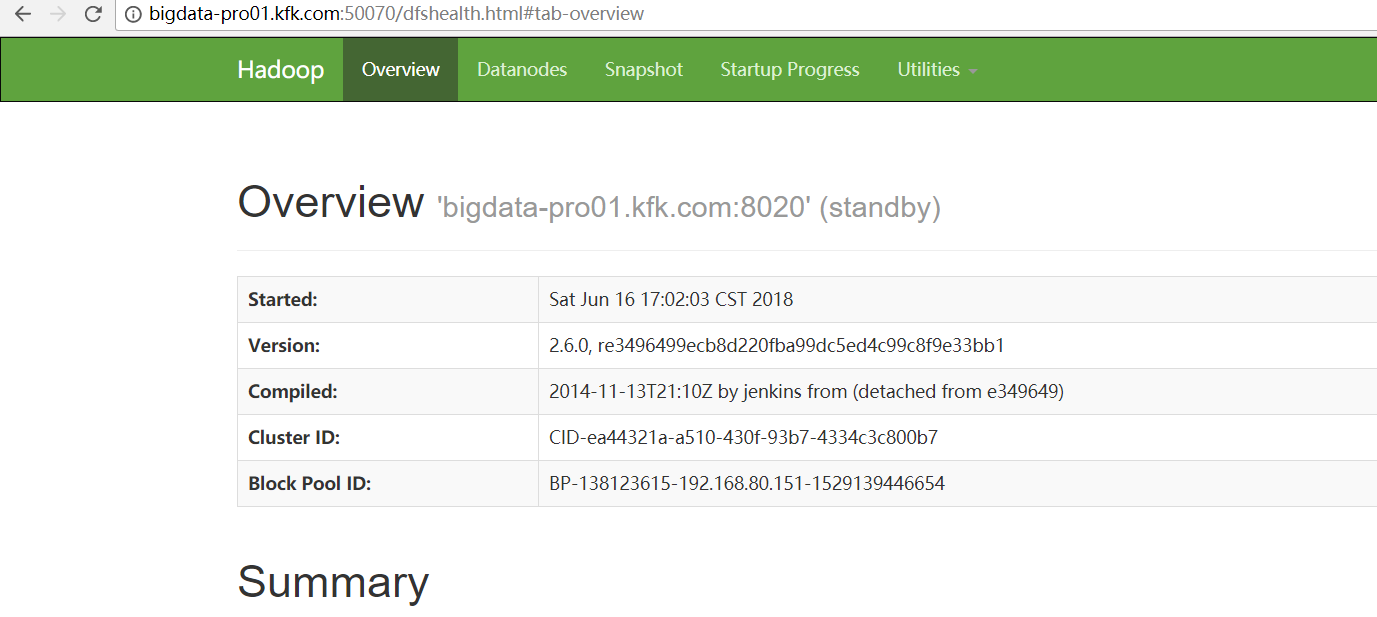
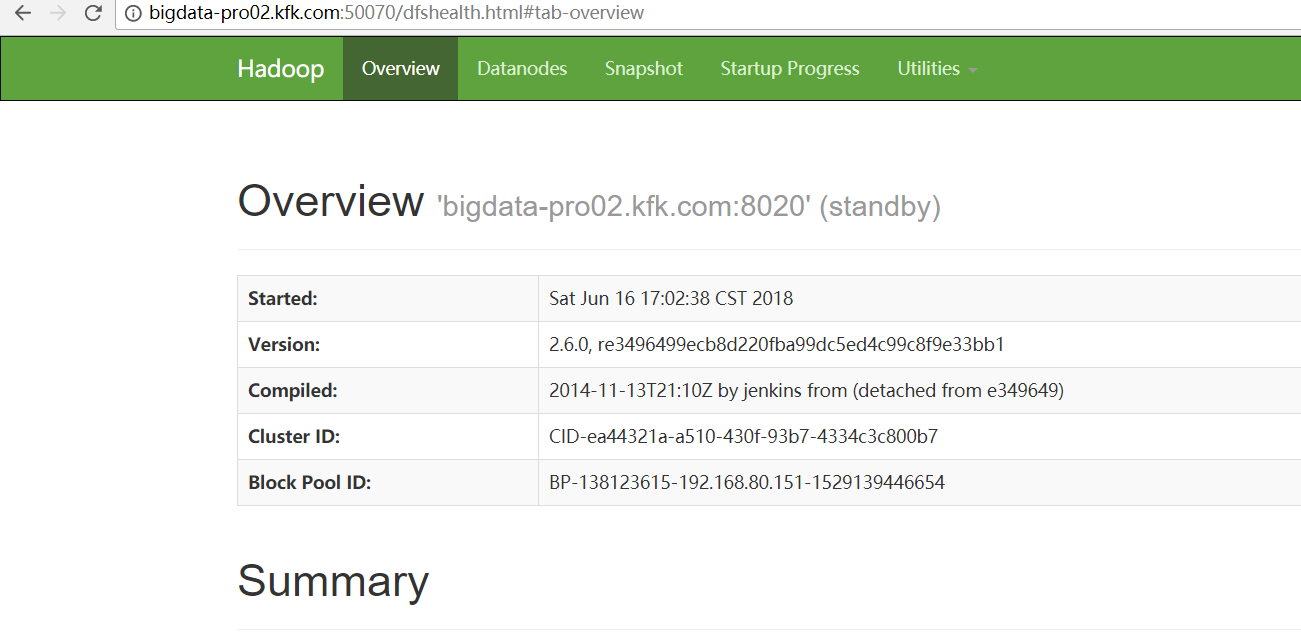
那么,你也许,第一感觉,是想到的是
全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)
这里,nn1,不多赘述了。很简单,大家自行去看。
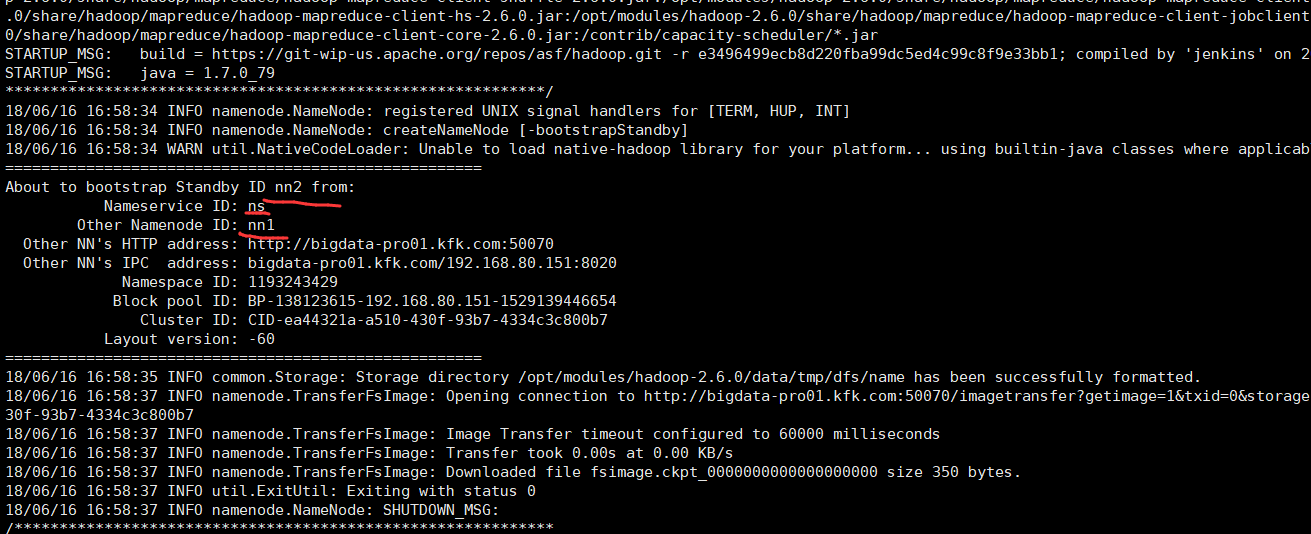
总的是nn,我的bigdata-pro01.kfk.com是nn1,我的bigdata-pro02.kfk.com是nn2。
是因为,在配置文件上,如下:

[kfk@bigdata-pro02 hadoop-2.6.0]$ bin/hdfs haadmin -transitionToActive nn1 Automatic failover is enabled for NameNode at bigdata-pro02.kfk.com/192.168.80.152:8020 Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the forcemanual flag. [kfk@bigdata-pro02 hadoop-2.6.0]$
解决办法:
是因为开启了zkfc 自动选active的namenode 不能手动切换了 zkfc会自动选择namenode节点作为active的。
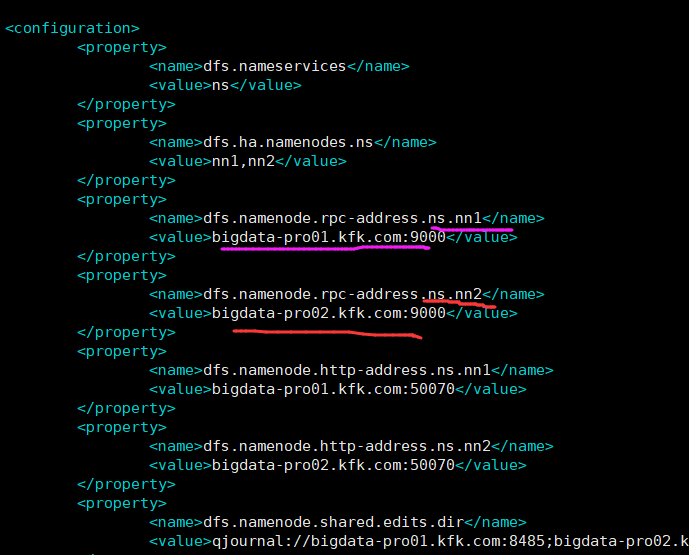
所以,
启动并测试
1、先停止掉Hadoop和zookeeper的进程。
2、启动zookeeper进程。
3、开启zkfc进程

[kfk@bigdata-pro01 hadoop-2.6.0]$ pwd /opt/modules/hadoop-2.6.0 [kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start zkfc starting zkfc, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-zkfc-bigdata-pro01.kfk.com.out
4、进入Hadoop的安装目录下面的sbin目录中,找到start-dfs.sh命令可以启动NameNode,当然这里需要你在配置了NameNode主节点的Hadoop节点上面来执行他。
或者,直接sbin/start-all.sh
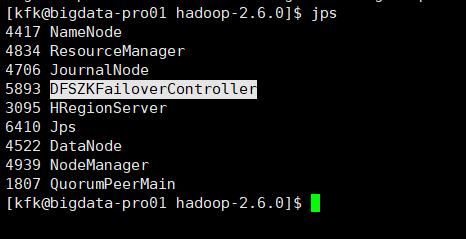
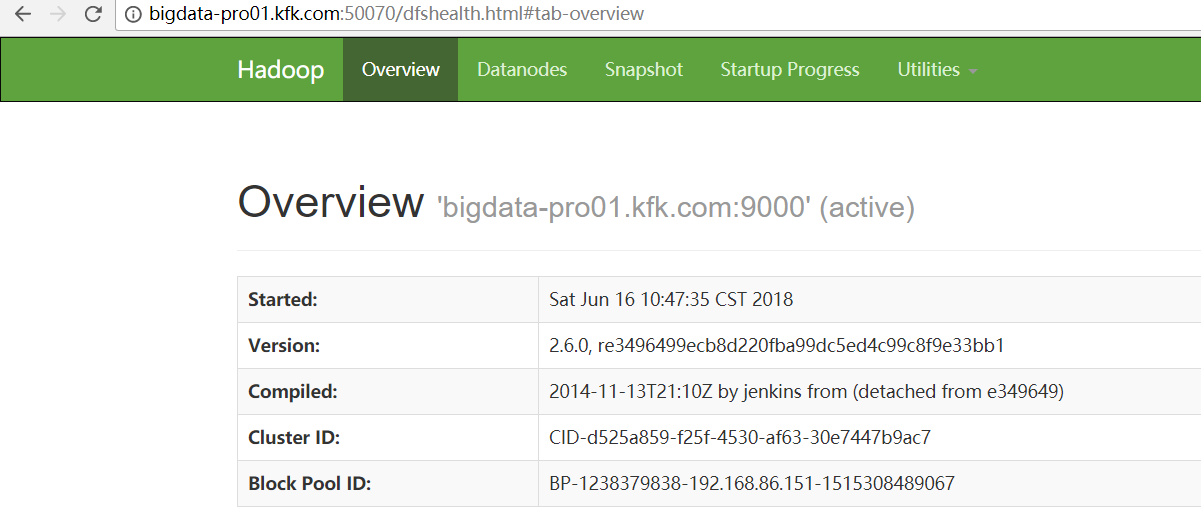
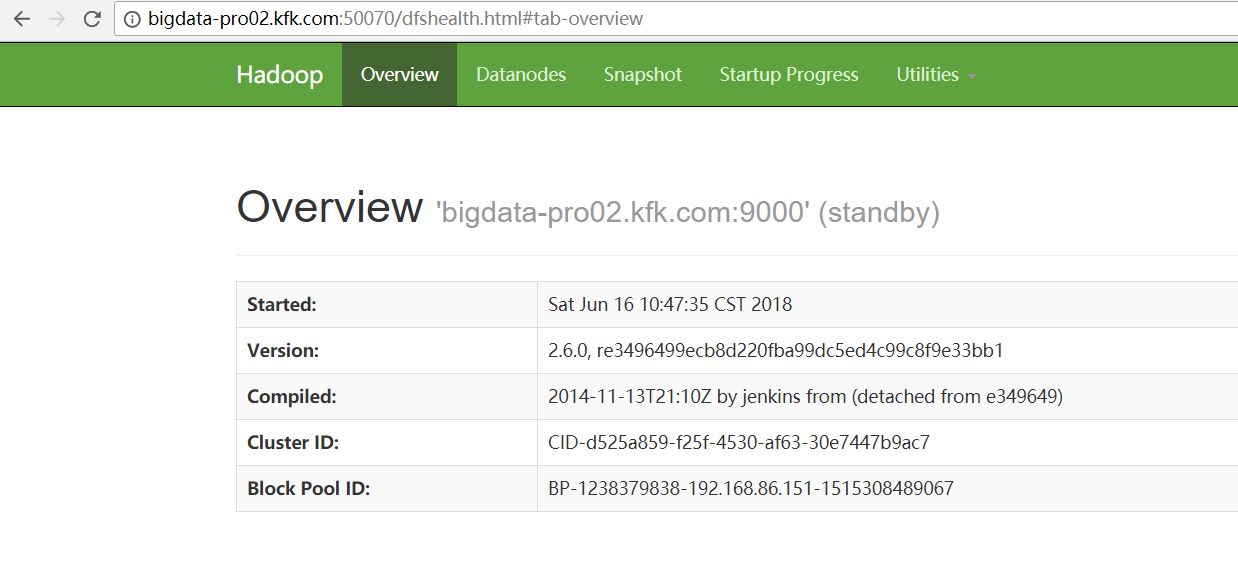
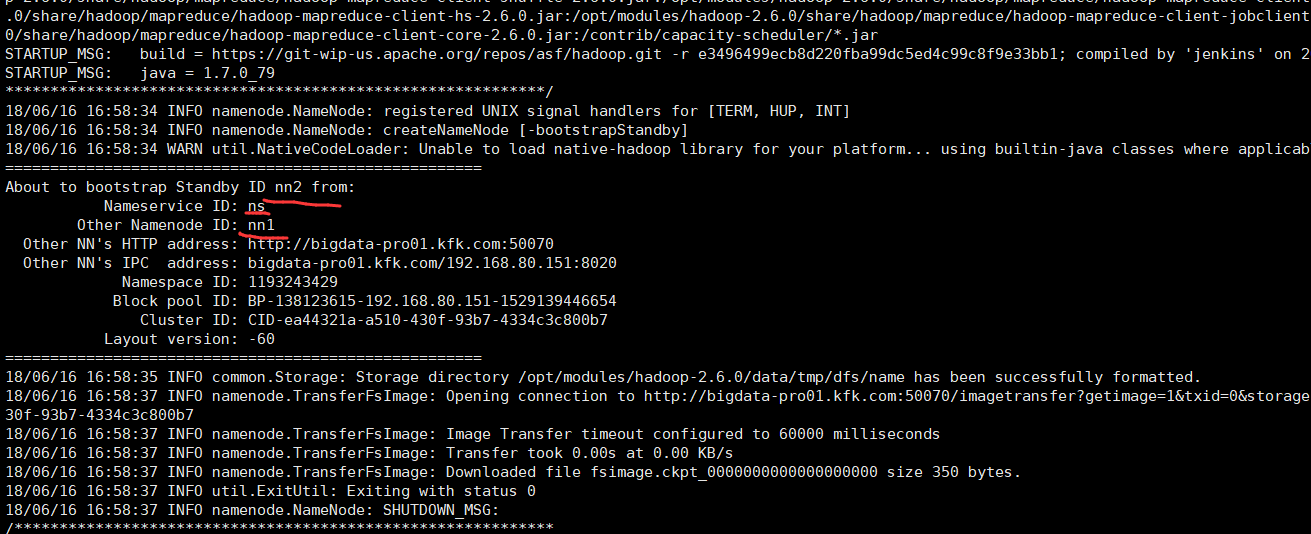
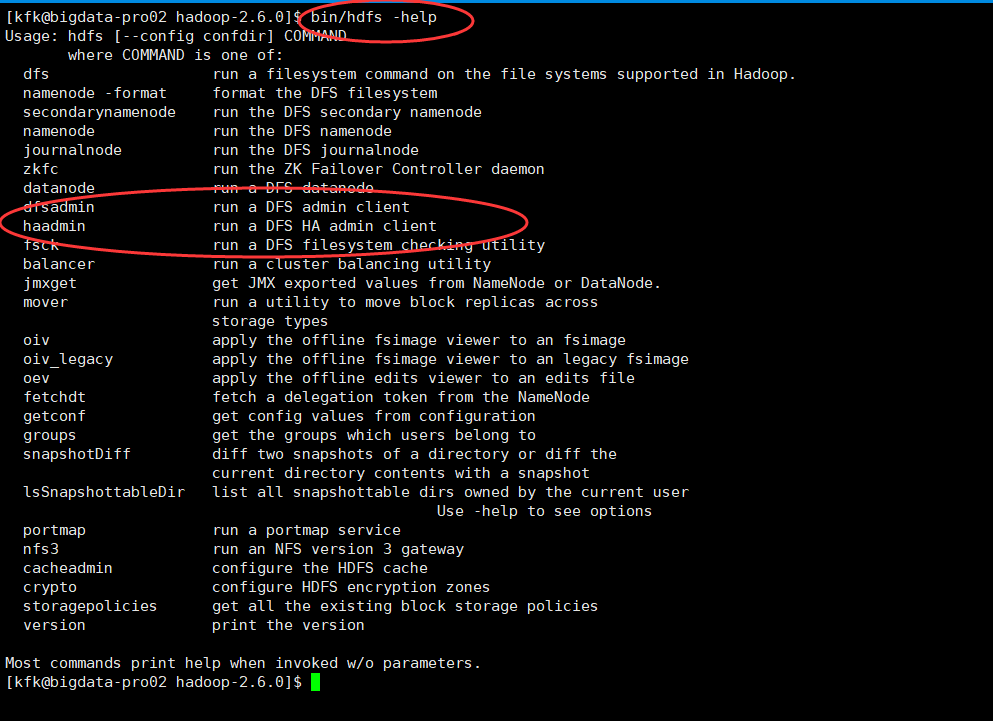

[kfk@bigdata-pro02 hadoop-2.6.0]$ bin/hdfs -help
Usage: hdfs [--config confdir] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
dfsadmin run a DFS admin client
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
mover run a utility to move block replicas across
storage types
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to an legacy fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
storagepolicies get all the existing block storage policies
version print the version
Most commands print help when invoked w/o parameters.

[kfk@bigdata-pro02 hadoop-2.6.0]$
[kfk@bigdata-pro02 hadoop-2.6.0]$ bin/hdfs haadmin -help
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive <serviceId> [--forceactive]]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
[kfk@bigdata-pro02 hadoop-2.6.0]$
注意,其实自带的命令里,都提供了,若两者都是standby状态怎么执行。若两者都是active状态怎么执行。这里,不多赘述。
如果,还是没解决的话,则

bin/hdfs haadmin -transitionToActive nn1
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()


