不多说,直接上干货!
1、 HA集群的主节点之间的双standby的解决办法:
全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)
2、 HA集群的主节点之间的双active的解决办法:
全网最详细的Hadoop HA集群启动后,两个namenode都是active的解决办法(图文详解)
3、 HA集群的主节点active和standby之间切换的解决办法:
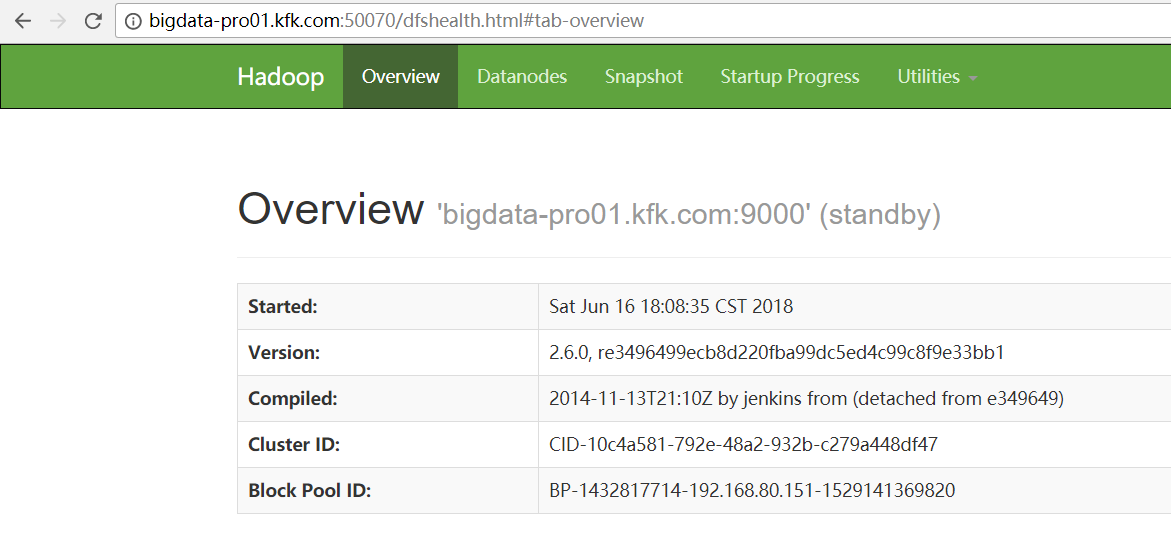
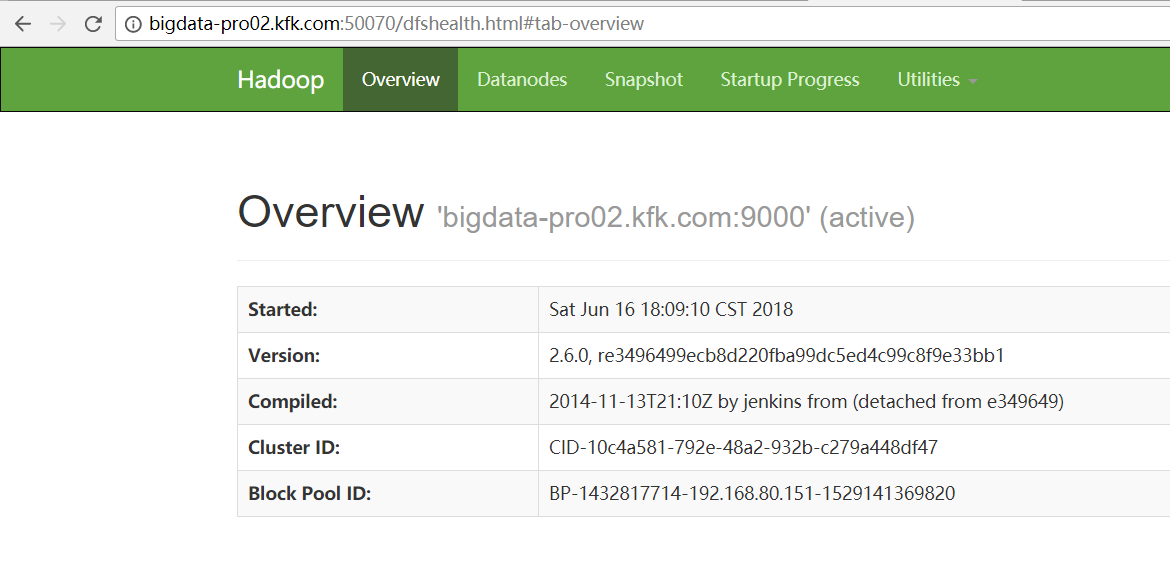
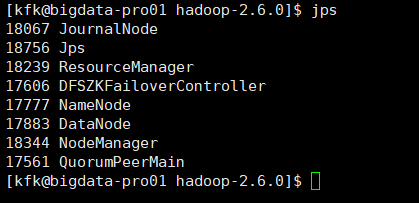

如果,你是出现
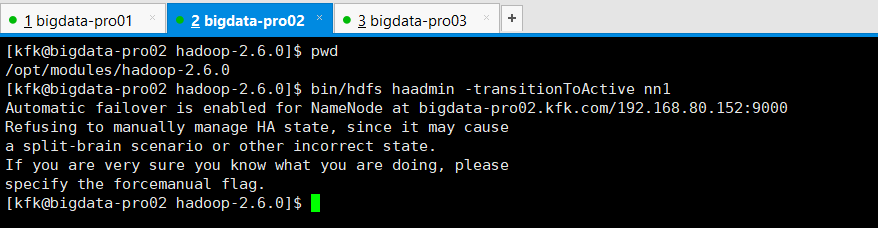
那是因为,你的是被zkfc自动选举决定了。
则,乖乖地
执行bin/hdfs haadmin -transitionToActive nn1时出现,Automatic failover is enabled for NameNode at bigdata-pro02.kfk.com/192.168.80.152:8020 Refusing to manually manage HA state的解决办法(图文详解)
当然,你可以强制使用Kill命令。
比如,之前是,
bigdata-pro02.kfk.com是active, bigdata-pro01.kfk.com是standby。
则:
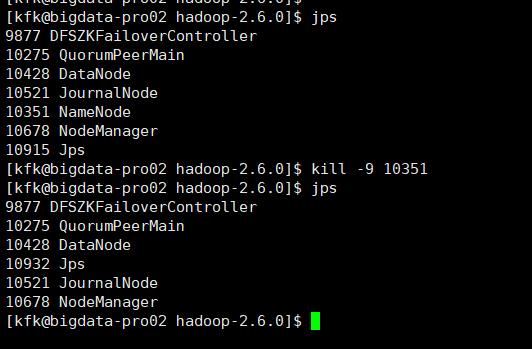
[kfk@bigdata-pro02 hadoop-2.6.0]$ jps 9877 DFSZKFailoverController 10275 QuorumPeerMain 10428 DataNode 10521 JournalNode 10351 NameNode 10678 NodeManager 10915 Jps [kfk@bigdata-pro02 hadoop-2.6.0]$ kill -9 10351 [kfk@bigdata-pro02 hadoop-2.6.0]$ jps 9877 DFSZKFailoverController 10275 QuorumPeerMain 10428 DataNode 10932 Jps 10521 JournalNode 10678 NodeManager [kfk@bigdata-pro02 hadoop-2.6.0]$
变为:
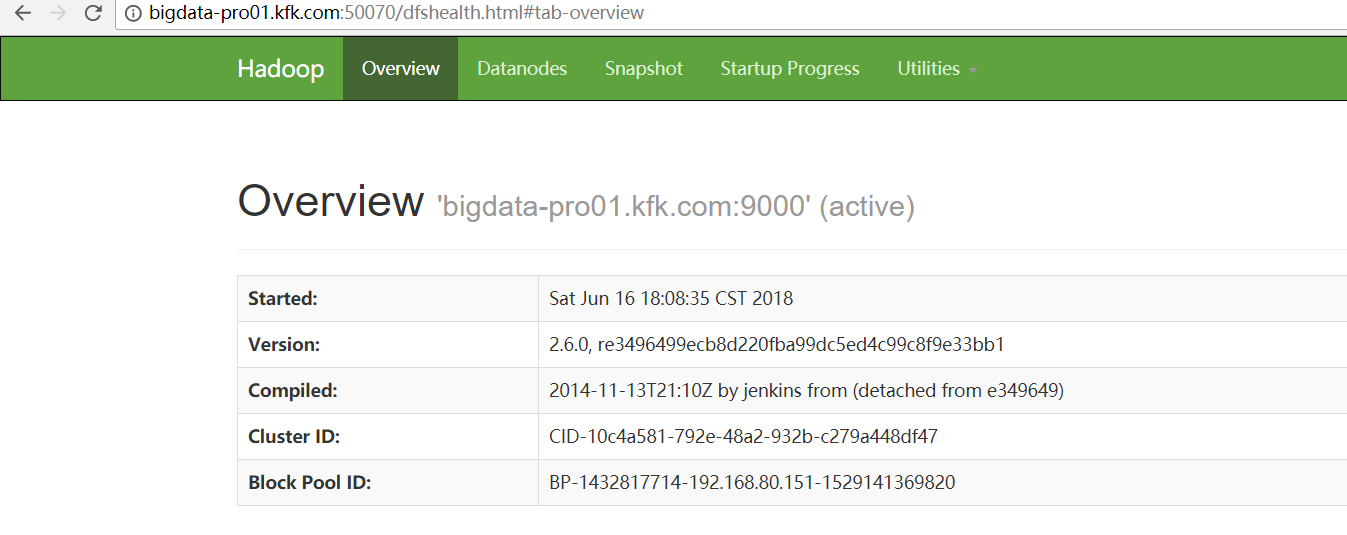
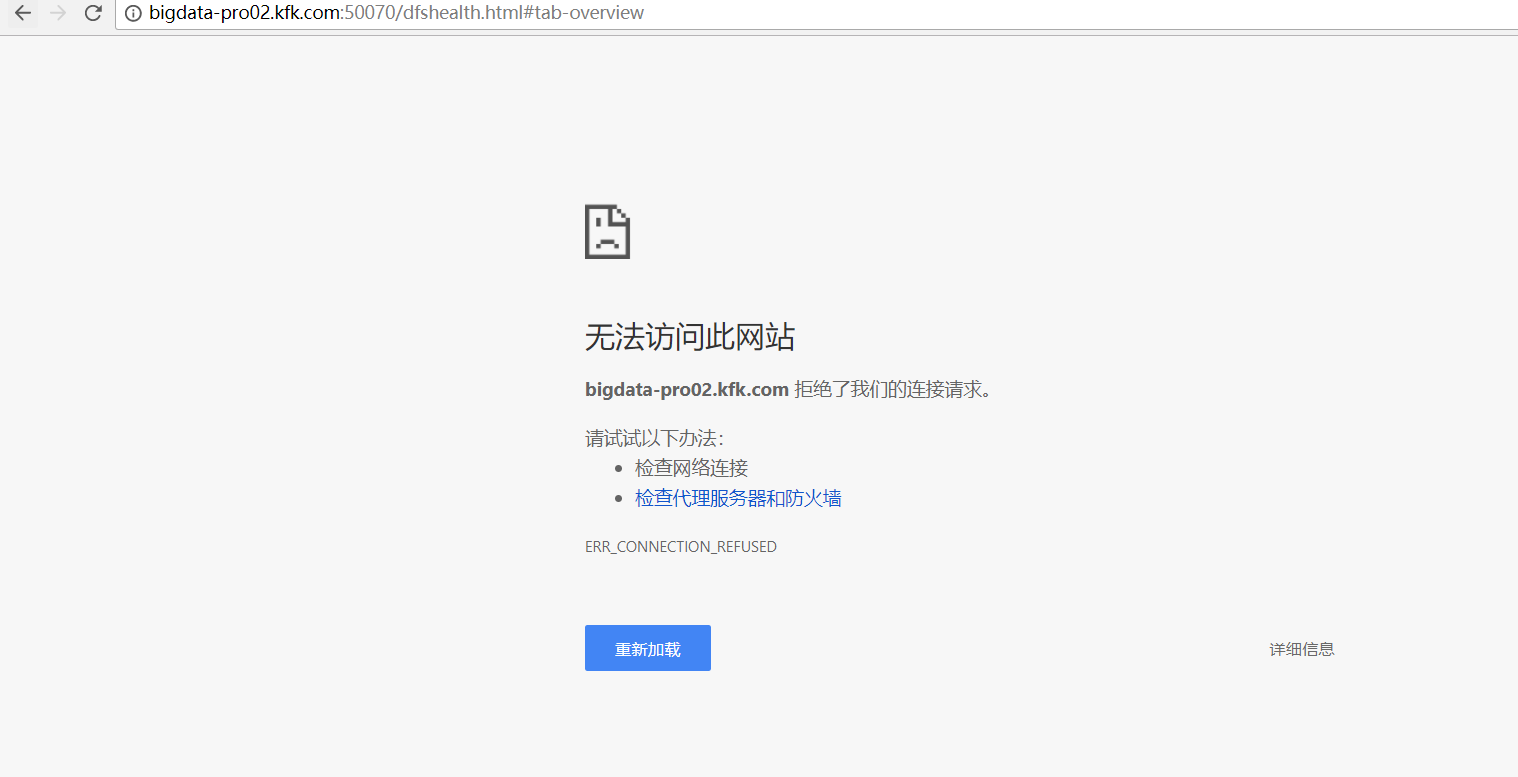
接着,执行以下命令,单独启动bigdata-pro02.kfk.com的namenode。
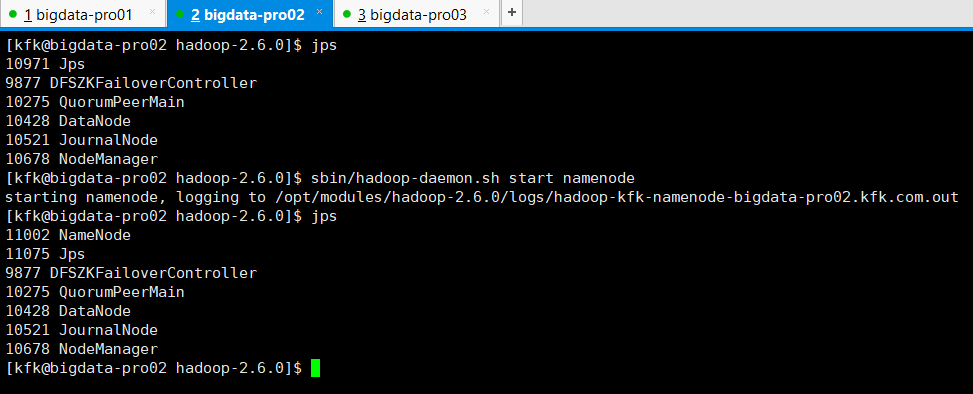
[kfk@bigdata-pro02 hadoop-2.6.0]$ jps 10971 Jps 9877 DFSZKFailoverController 10275 QuorumPeerMain 10428 DataNode 10521 JournalNode 10678 NodeManager [kfk@bigdata-pro02 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-namenode-bigdata-pro02.kfk.com.out [kfk@bigdata-pro02 hadoop-2.6.0]$ jps 11002 NameNode 11075 Jps 9877 DFSZKFailoverController 10275 QuorumPeerMain 10428 DataNode 10521 JournalNode 10678 NodeManager [kfk@bigdata-pro02 hadoop-2.6.0]$

成功! 变为 bigdata-pro01.kfk.com是active, bigdata-pro02.kfk.com是standby。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()


