爬虫原理:
什么是爬虫?
爬虫指的是爬数据
什么是互联网?
由一堆网络设备把一台一台的计算机互联到一起
互联网建立的目的:数据的传递与数据的共享
上网的全过程:
-普通用户:
打开浏览器-->往目标站点发送请求-->接受响应数据-->渲染到页面上
-爬虫程序
模拟浏览器-->往目标站点发送请求-->接受响应数据-->提取有用数据-->保存到本地数据库
浏览器发送的什么请求?
http协议请求:
-请求url:
-请求方式:
get,POST
-请求头:
cookies
user-agent
host
爬虫全过程:
1、发送请求
-request请求
-selenium模块
2、获取响应数据
3、解析并提取数据
-RE
-bs4(BeautufulSoup4)
4、保存数据
-MongoDB
1、3、4需要手动写
-爬虫框架
Scrapy(基于面向对象)
爬取梨视频:
1、分析网站的视频源地址
2、通过request网视频源地址发送请求
3、获取视频的二进制流,并保存到本地
1、爬取整个梨视频里面的视频链接
''' 访问url https://www.pearvideo.com/ 请求方式: Get 请求头: user-agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 ''' import requests import re response =requests.get(url="https://www.pearvideo.com/") print(response.status_code) #print(response.text) #re.findall('正则匹配规则','解析文本',"正则模式") #re.S:全局模式(对整个文本进行匹配) #.指的是当前位置 #*指的是查找所有 ''' <a href="video_1543373" <a href="video_(.*?)" #提取1543373 ''' #获取主页视频详情ID res=re.findall('<a href="video_(.*?)"',response.text,re.S) print(res) for m_id in res: detail_url='http://www.pearvideo.com/video_'+m_id print(detail_url)
2、爬取整个详情页视频内容:
import requests import re #正则模块 #uuid.uuid()可以时间戳生成一段世界上唯一的所及字符串 import uuid #爬虫三部曲 #1、发送请求 def get_page(url): response=requests.get(url) return response #2、解析数据 #解析主页获取视频详情页ID def parse_index(text): res=re.findall('<a href="video_(.*?)"',text,re.S) #print(res) detail_url_list=[] #存放所有视频链接 for m_id in res: #拼接详情页url detail_url = 'http://www.pearvideo.com/video_' + m_id #print(detail_url) detail_url_list.append(detail_url) #把每个视频链接添加进去 #print(detail_url_list) return detail_url_list #解析详情页获取视频url def parse_detail(text): ''' (.*?):提取括号内容 .*?:直接匹配 <video webkit-playsinline="" playsinline="" x-webkit-airplay="" autoplay="autoplay" src="https://video.pearvideo.com/mp4/adshort/20190613/cont-1565846-14013215_adpkg-ad_hd.mp4" style=" 100%; height: 100%;"></video> 正则:<video.*?src="(.*?)" 正则:srcUrl="(.*?)" ''' movie_url=re.findall('srcUrl="(.*?)"',text,re.S)[0] #print(movie_url) return movie_url #3、保存数据 def save_movie(movie_url): response=requests.get(movie_url) #把视频写到本地 with open(f'{uuid.uuid4()}.mp4','wb') as f: f.write(response.content) f.flush() if __name__ == '__main__':#输入main加回车键 #1、对主页发送请求 index_res=get_page(url='http://www.pearvideo.com/') #2、对主页进行解析,获取详情页id detail_url_list=parse_index(index_res.text) #print(detail_url_list) #3、对每个详情页发送url请求 for detail_url in detail_url_list: detail_res=get_page(url=detail_url) #print(detail_res.text) movie_url=parse_detail(detail_res.text) print(movie_url) save_movie(movie_url)
3、采用多线程方法对详情页视频爬取:
import requests import re #正则模块 #uuid.uuid()可以时间戳生成一段世界上唯一的所及字符串 import uuid #爬虫三部曲 #1、发送请求 def get_page(url): response=requests.get(url) return response #2、解析数据 #解析主页获取视频详情页ID def parse_index(text): res=re.findall('<a href="video_(.*?)"',text,re.S) #print(res) detail_url_list=[] #存放所有视频链接 for m_id in res: #拼接详情页url detail_url = 'http://www.pearvideo.com/video_' + m_id #print(detail_url) detail_url_list.append(detail_url) #把每个视频链接添加进去 #print(detail_url_list) return detail_url_list #解析详情页获取视频url def parse_detail(text): ''' (.*?):提取括号内容 .*?:直接匹配 <video webkit-playsinline="" playsinline="" x-webkit-airplay="" autoplay="autoplay" src="https://video.pearvideo.com/mp4/adshort/20190613/cont-1565846-14013215_adpkg-ad_hd.mp4" style=" 100%; height: 100%;"></video> 正则:<video.*?src="(.*?)" 正则:srcUrl="(.*?)" ''' movie_url=re.findall('srcUrl="(.*?)"',text,re.S)[0] #print(movie_url) return movie_url #3、保存数据 def save_movie(movie_url): response=requests.get(movie_url) #把视频写到本地 with open(f'{uuid.uuid4()}.mp4','wb') as f: f.write(response.content) f.flush() if __name__ == '__main__':#输入main加回车键 #1、对主页发送请求 index_res=get_page(url='http://www.pearvideo.com/') #2、对主页进行解析,获取详情页id detail_url_list=parse_index(index_res.text) #print(detail_url_list) #3、对每个详情页发送url请求 for detail_url in detail_url_list: detail_res=get_page(url=detail_url) #print(detail_res.text) movie_url=parse_detail(detail_res.text) print(movie_url) save_movie(movie_url)
4、对requests命令的详细使用,其中需要注意headers的反扒操作,以及如何精准定位每页的网址
''' 访问发现知乎 请求url:https://www.zhihu.com/explore 请求方式l;GET 请求头: 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' cookie ''' #访问知乎 import requests # response=requests.get(url="https://www.zhihu.com/explore") # print(response.status_code) #400 # print(response.text)#错误页面 ''' params参数 访问百度搜查蔡徐坤url http://www.baidu.com/s?wd=安徽工程大学&pn=10 http://www.baidu.com/s?wd=安徽工程大学&pn=20 ''' from urllib.parse import urlencode #url='https://www.baidu.com/s?wd=%E8%94%A1%E5%BE%90%E5%9D%A4' #url='https://www.baidu.com/s?'+urlencode({"wd":"蔡徐坤"}) url='http://www.baidu.com/s?' headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } #在get方法中添加params参数 #response=requests.get(url,headers=headers,params={"wd":"安徽工程大学"}) response=requests.get(url,headers=headers,params={"wd":"安徽工程大学","pn":"20"}) #print(url) with open('gongcheng2.html','w',encoding='utf-8') as f: f.write(response.text)
5、对豆瓣前25的电影信息进行爬取,其中包括电影详情页url、图片链接、电影名称、电影评分、评价人数
''' 主页:https://movie.douban.com/top250 GET user-agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 re正则: # 电影详情页url、图片链接、电影名称、电影评分、评价人数 <div class="item">.*?href="(.*?)">.*?src="(.*?)".*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价 ''' import requests import re url="https://movie.douban.com/top250" headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } #1、往豆瓣top250发送请求获取响应数据 response=requests.get(url,headers=headers) #print(response.text) #2、通过正则解析提取数据 # 电影详情页url、图片链接、电影名称、电影评分、评价人数 movie_content_list=re.findall( #正则规则 '<div class="item">.*?href="(.*?)">.*?src="(.*?)".*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价', #解析分析 response.text, #匹配模式 re.S ) for movie_content in movie_content_list: #解压赋值 detail_url,movie_jpg,name,point,num=movie_content data=f'电影名字:{name},详情页url:{detail_url},图片url:{movie_jpg},评分:{point},评价人数:{num} ' print(data) #保存数据,把电影信息写入文件中 with open('douban.txt','a',encoding='utf-8') as f: f.write(data)
6、作业:
对豆瓣前250的电影进行爬取,其中又增加两条信息为:演出人员信息、电影简介
代码如下:
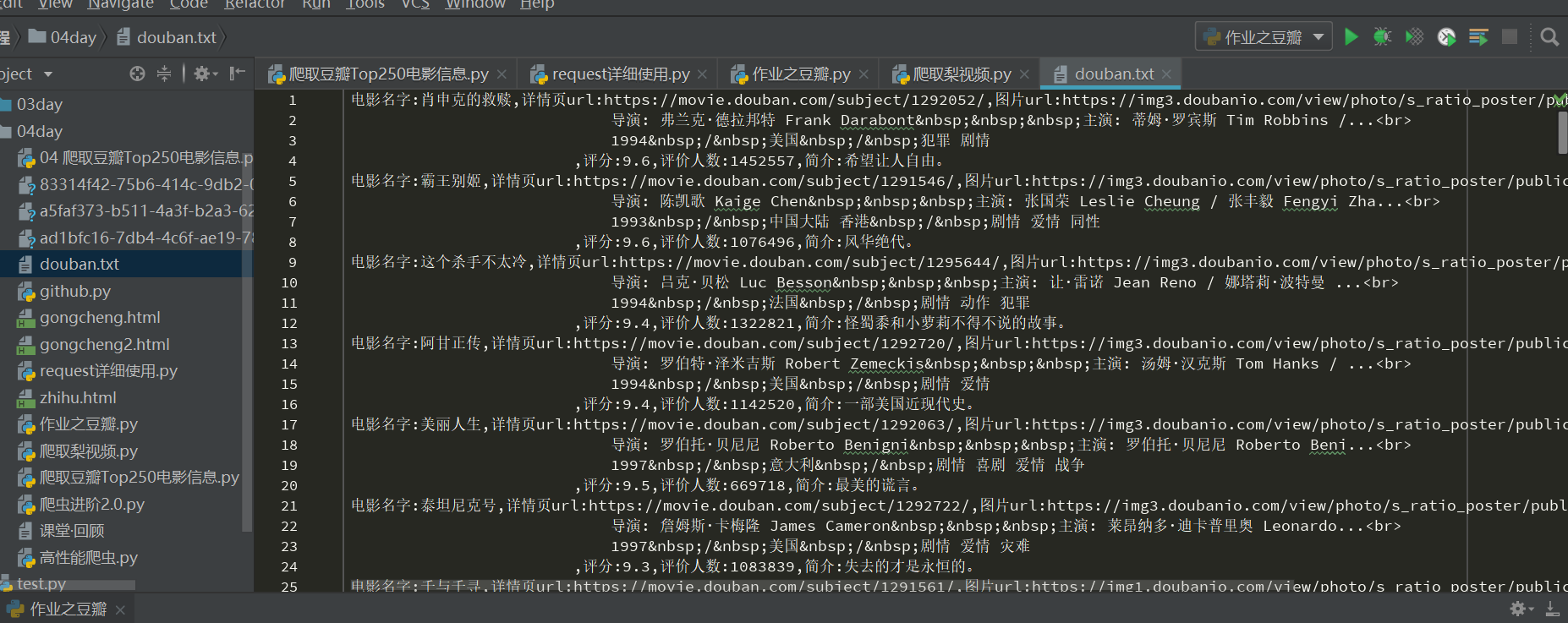
import requests import re def crow(i): url = 'https://movie.douban.com/top250?start=' + str(25 * i) headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } # 1、往豆瓣top250发送请求获取响应数据 response = requests.get(url, headers=headers) # print(response.text) # 2、通过正则解析提取数据 # 电影详情页url、图片链接、电影名称、导演信息、电影评分、评价人数、电影简介 movie_content_list = re.findall( # 正则规则 '<div class="item">.*?href="(.*?)">.*?src="(.*?)" .*?<span class="title">(.*?)</span>.*?<p class="">(.*?)</p>.*?<span class="rating_num" property="v:average">(.*?)</span>.*?<span>(.*?)人评价.*?<span class="inq">(.*?)</span>', # 解析分析 response.text, # 匹配模式 re.S ) for movie_content in movie_content_list: # 解压赋值 detail_url, movie_jpg, name,actor, point, num ,brief= movie_content data = f'电影名字:{name},详情页url:{detail_url},图片url:{movie_jpg},演员信息:{actor},评分:{point},评价人数:{num},简介:{brief} ' print(data) # 保存数据,把电影信息写入文件中 with open('douban.txt', 'a', encoding='utf-8') as f: f.write(data) for i in range(10): crow(i)
得到的爬取信息
小结:通过对python的学习,了解到了更多有关Python的知识,整个过程是新奇刺激的,也大大提高对python的兴趣,同时在后面的学习中也会更加认真,争取学习到更多的知识。