Path模块
该模块提供了对文件或目录路径处理的方法,使用require('path')引用。
1、获取文件路径最后部分basename
使用basename(path[,ext])方法来获取路径的最后一部分,参数ext是后缀名,如下所示:
var bname = path.basename('../test.txt');
console.log(bname);//test.txt
var bname = path.basename('../test.txt','.txt');
console.log(bname);//test
2、获取文件路径目录部分dirname
使用dirname(path)方法来获取路径目录部分,如下所示:
console.log(path.dirname('../canvasDemo/axis/axis.css'));//../canvasDemo/axis
3、获取后缀名
使用extname(path)方法来后缀名,该方法是截取最后的'.'点到结束的字符串,如果点不存在,则返回空字符串,如果点在最后则直接返回点,如下所示:
console.log(path.extname('../test.txt'),path.extname('../test.'),path.extname('../test'));//.txt . 空
4、获取当前平台的文件分隔符和路径分隔符
path.sep返回文件分隔符,path.delimiter获取路径分隔符,它们都是操作系统决定的,如下所示:
console.log(path.sep);//
console.log(path.delimiter);// ;
5文件路径分析
使用path.parse(path)方法对一个路径进行分析,然后返回一个对象,该对象拥有5个属性,分别是:root,dir,base,ext,name。使用如下所示:
var obj = path.parse('../canvasDemo/axis/axis.css');
console.log(obj);
/*{ root: '',
dir: '../canvasDemo/axis',
base: 'axis.css',
ext: '.css',
name: 'axis' }*/
URL模块
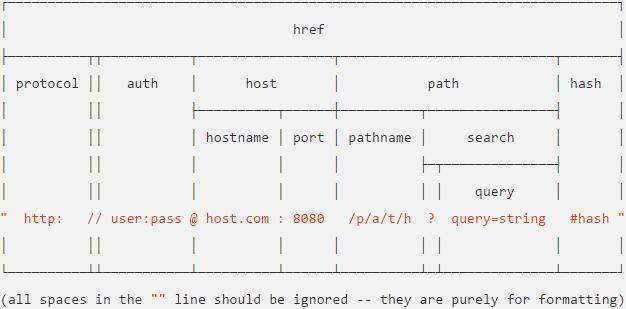
url模块提供对url解析的方法,使用require('url')引用。Url统一资源定位器,主要包涵以下部分,如下所示:
![URL组成] (http://images.cnblogs.com/cnblogs_com/zmxmumu/679290/o_QQ截图20161128110540.jpg)
{kind=link}
1、url解析
使用url.parse(urlString[, parseQueryString[, slashesDenoteHost]])方法对一个url字符串进行解析,解析成功后返回一个包含上图所示字段的对象,参数parseQueryString是一个布尔值,如果设置为true,则自动使用querystring模块的parse方法对查询字符串进行解析,否则返回原始字符串,默认为false。使用如下所示:
var url = require('url');
var urlObj = url.parse('https://nodejs.org:443/dist/latest-v6.x/docs/api/url.html?ver=011#url_urlobject_auth');
for(var i in urlObj){
if(urlObj.hasOwnProperty(i)){
console.log(i+':'+urlObj[i]);
}
}
执行即如果如下所示:
E:developmentdocument odejsdemo>node url-example.js
protocol:https:
slashes:true
auth:null
host:nodejs.org:80
port:80
hostname:nodejs.org
hash:#url_urlobject_auth
search:?ver=011
query:ver=011
pathname:/dist/latest-v6.x/docs/api/url.html
path:/dist/latest-v6.x/docs/api/url.html?ver=011
href:https://nodejs.org:80/dist/latest-v6.x/docs/api/url.html?ver=011#url_urlob
ject_auth
2、将urlObject转换成url字符串
使用url.format(urlObject)方法可以将一个urlObject对象转换成格式化的url字符串,使用如下所示:
console.log(url.format(urlObj));//https://nodejs.org:80/dist/latest-v6.x/docs/api/url.html?ver=011#url_urlob
querystring模块
该模块可以用来解析和格式化URL查询字符串,使用require('querystring')进行引用。
1、解析查询字符串
方法querystring.parse(str[, sep[, eq[, options]]])可以解析一个查询字符串,转换成key-value键值对,参数含义如下:
- sep:指定每个键值对的分隔符,默认为"&"
- eq:指定key-value的分隔符,默认为"="
使用如下所示:
const qs = require('querystring');
const searchStr = 'name=zhangsan&age=20';
const str = 'name*lisi^age*20';
console.log(qs.parse(searchStr));//{ name: 'zhangsan', age: '20' }
console.log(qs.parse(str,'^','*'));//{ name: 'lisi', age: '20' }
2、将对象转换成查询字符串
方法querystring.stringify(obj[, sep[, eq[, options]]])可以将一个对象格式化成一个url查询字符串,参数含义跟parse一样,使用如下所示:
const obj = { kw:'你好',num:1 };
const o2 = { name:['zhangsan','lisi'],age:20 };
console.log(qs.stringify(obj));//kw=%E4%BD%A0%E5%A5%BD&num=1
console.log(qs.stringify(o2));//name=zhangsan&name=lisi&age=20