参数化的意义不再赘述,参数化有两种情况:
1.后台(应用程序和数据库)对请求里的参数值限制了唯一性,说白了就是功能里要求的不能重复的参数,如果有这类唯一性校验的参数就需要参数化;
2.避免因数据库查询缓存而导致性能测试结果的失真;
这里的数据库查询缓存是指在该条请求之前,数据库已经有该条请求结果数据存在缓存里,当在此请求时,数据库首先会去缓存里找要执行的查询sql,找到了直接就返回了数据,不必要后面很多方所得操作;
显然这种情况下的性能执行结果要比没有缓存的结果快的多,所以存在性能结果失真的问题。,孤儿我们要参数化,请求不同的数据。
关于数据库的sql执行原理,这里不再赘述,以后在性能调优的时候再研究,暂时参考:http://blog.csdn.net/wanghjbuf/article/details/50792970
3.当参数不是一个常量,不同情况下值有变化,比如IP地址,就可以参数化,当IP变了后我改下参数就可以,没必要每次去修改脚本里的地址,便于维护代码。
参数化又有不同的方法,基本都大同小异,在参数化之前可以思考下,怎样降低参数化操作的可能性,可以围绕上述说的几点:1.测试的时候取消数据库和应用程序的唯一性校验;2.测试的时候关闭数据库的缓存功能。
这里介绍两种,一种是直接边界参数,还有一种是操作数据库,从数据库里导入数据。
下面主要介绍多列参数一一对应时的参数化,比如这里需要参数化四个参数,这四个参数是一一对应的:用户名、密码、确认密码、邮箱,参数化步骤如下:
1.选中需要参数化的对象,右键,点击【Replace with a new parameter】

2.点击【browser】,在脚本目录下新建params目录,用来存放这个脚本的所有参数化数据,选中目录后,点击【create table】
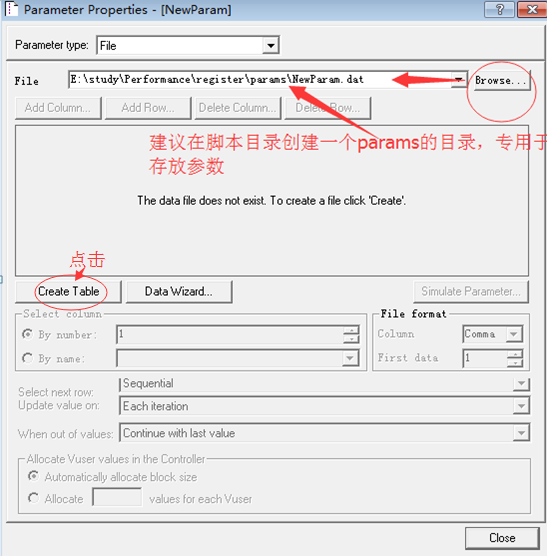
3.点击【edit with notpad】打开记事本,在记事本里输入参数(换行分割),关闭记事本,关闭参数化属性,点击【OK】,这样username就参数化好了

4.选中密码,重复上述步骤1,进入参数属性页面,选中刚才创建好的Newparam文件,点击【add colum】,点击【OK】
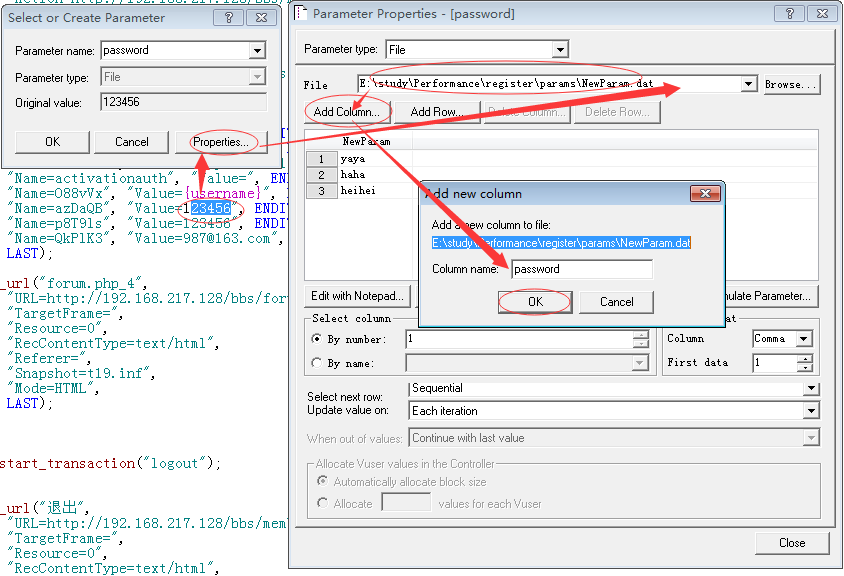
5.点击【edit with notpad】打开记事本,逗号后面输入密码参数,保存关闭记事本,关闭参数属性,点击【OK】
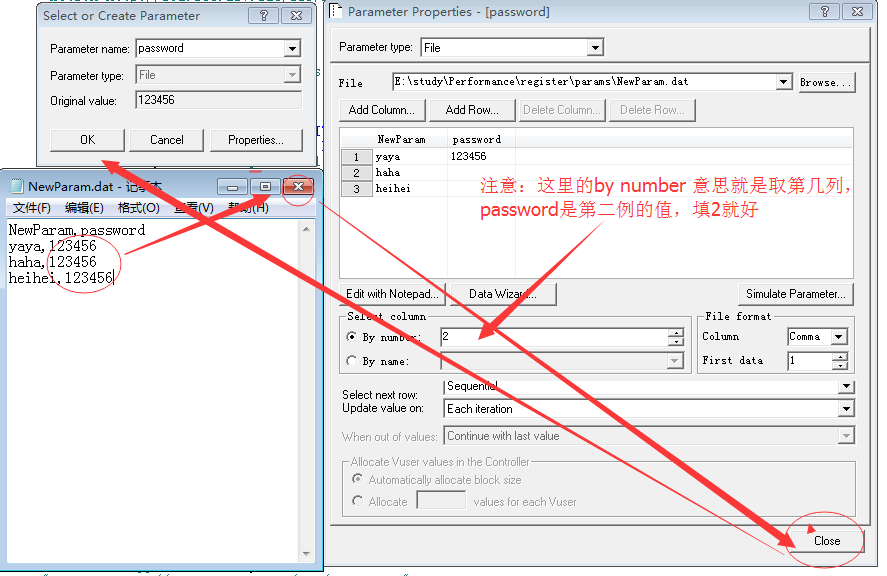
确认密码、邮箱同步骤五,都创建好后我们来看下参数化策略;
Select next row【选择下一行】
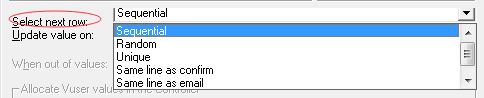
1.顺序(Sequential):按照参数化的数据顺序,一个一个的来取。
2.随机(Random):参数化中的数据,每次随机的从中抽取数据。
3.唯一(Unique):为每个虚拟用户分配一条唯一的数据
Update value on【更新时的值】

每次迭代(Each iteration) :每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
只取一次(once) :参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)
组合起来就有9种策略,如下:
|
Select Next Row 【选择下一行】 |
Update Value On 【更新时的值】 |
Replay Result 【结果】 |
|
顺序(Sequential) |
每次迭代(Each iteration) |
结果:分别将15条数据写入数据表中 功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取 如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条 |
|
顺序(Sequential) |
每次出现(Each occurrence) |
结果:分别将15条数据写入数据表中 功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取 如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条 |
|
顺序(Sequential) |
只取一次(once) |
结果:表中写入15条一模一样的数据。 功能说明:每次迭代都取参数化文件中第一行的数据。 |
|
随机(Random) |
每次迭代(Each iteration) |
结果:表中写入15条数据,但可能有重复数据出现 功能说明:每次从参数化文件中随机选择一行数据进行赋值 |
|
随机(Random) |
每次出现(Each occurrence) |
结果:表中写入15条数据,但可能有重复数据出现 功能说明:每次从参数化文件中随机选择一行数据进行赋值 |
|
随机(Random) |
只取一次(once) |
结果:表中写入15条相同数据 功能说明:第一次迭代时随机从参数化文件中取一行数据,后面每次迭代都用第一次迭代的数据。 |
|
唯一(Unique) |
每次迭代(Each iteration) 自动分配块大小 |
结果:分别将15条数据写入数据表中 功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。 注:如果设置迭代次数为16次。结果:在执行第16次迭代时会抛异常,异常日志可在LoadRunner的回放日志(replayLog)中看到。 |
|
唯一(Unique) |
每次出现(Each occurrence) 步长为1 |
结果:分别将15条数据写入数据表中 功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。 注:如果设置迭代次数为16次,而参数化文件中只有15条数据,明显数据不够。此时可以设置“when out of values”属性来判断当数据不够时的处理方式 Abort Vuser:中断虚拟用户 Countinue in a cylic manage:循环取参数化文件中的值,即:当参数化文件中的值取完后又从参数化文件的第一行开始取值。 Countinue with last value:继续用最后一条数据 |
|
唯一(Unique) |
只取一次(once) |
结果:表中写入15条相同数据 功能说明:每次都取参数文件中的第一条数据进行赋值 |
综上所述,我们这里的注册需要每次的数据都不一样,那么我们就选第7中策略,Unique+Each iteration,用户一第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据;用户二第一次迭代取参数化文件中的第三条数据,第二次迭代取第四条数据,以此类推。当迭代次数大于参数化数据时会报错,设置如下:
Tips:因为这里,每个迭代内值调用了一次参数,所以选Each iteration(每个迭代),如果这个迭代里调用两次参数,那么需要选(Each occurrence),意思是每次迭代里的每次参数都需要不一样。

接下来介绍下从数据库里导入参数,因为sql server百度里已经有很多介绍,这里不再赘述,主要讲下mysql,mysql的数据库驱动需要自己安装,这里给个路径,大家上官网上下就行:
https://dev.mysql.com/downloads/connector/odbc/

下载好后按默认的设置安装完成即可,这里我们拿登录举例,我们直接从数据库里查询到用户名作为参数。
1.参照上面的第一步,进入参数属性页面,依次按下图所示点击

2.继续依次按下图所示点击

3.选中刚才安装的mysql驱动,点击下一步,点击完成

4.数据库信息如下填写,测试成功后,点击【OK】,【确定】,知道回到步骤五的界面
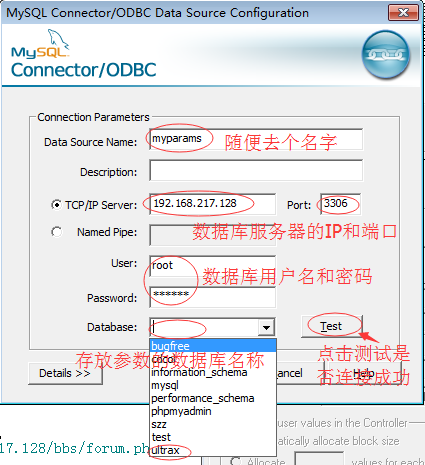
5.sql中输入查询语句,点击【finish】后,参数化就成功了


以上就是鄙人对参数化的粗浅认识,如若有不妥之处还望指正,感谢!