一、前言
本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态。
协程指的就是单线程下实现并发
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长或有一个优先级更高的程序替代了它。
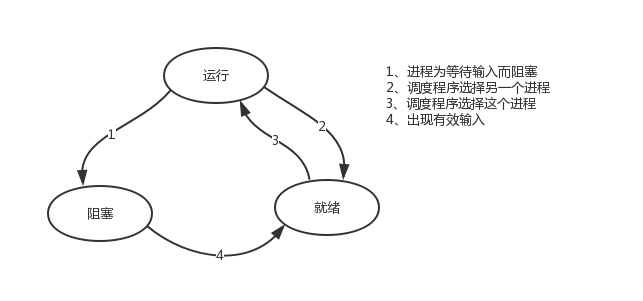
tip:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态。
1,其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
# 1,yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级。 # 2,send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换。
''' 1、协程: 单线程实现并发 在应用程序里控制多个任务的切换+保存状态 优点: 应用程序级别速度要远远高于操作系统的切换 缺点: 多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地 该线程内的其他的任务都不能执行了 一旦引入协程,就需要检测单线程下所有的IO行为, 实现遇到IO就切换,少一个都不行,以为一旦一个任务阻塞了,整个线程就阻塞了, 其他的任务即便是可以计算,但是也无法运行了 2、协程序的目的: 想要在单线程下实现并发 并发指的是多个任务看起来是同时运行的 并发=切换+保存状态 '''


# 串行执行 import time def consumer(res): '''任务1:接收数据,处理数据''' pass def producer(): '''任务2:生产数据''' res = [] for i in range(10000000): res.append(i) return res start = time.time() # 串行执行 res = producer() consumer(res) # 写成consumer(producer())会降低执行效率 stop = time.time() print(stop-start) # 1.5536692142486572 # 基于yield并发执行 import time def consumer(): '''任务1:接收数据,处理数据''' while True: x = yield def producer(): '''任务2:生产数据''' g = consumer() next(g) for i in range(10000000): g.send(i) start=time.time() # 基于yield保存状态,实现两个任务直接来回切换,即并发的效果 # Tip:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的. producer() stop = time.time() print(stop-start) # 2.0272178649902344
2,第一种情况的切换。在任务一遇到 I/O情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
import time def consumer(): '''任务1:接收数据,处理数据''' while True: x = yield def producer(): '''任务2:生产数据''' g = consumer() next(g) for i in range(10000000): g.send(i) time.sleep(2) start = time.time() producer() # 并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行 stop = time.time() print(stop-start)
对于单线程下,我们不可避免程序中出现 I/O操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到 I/O阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的 I/O操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,I/O比较少,从而更多的将cpu的执行权限分配给我们的线程。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
# 1,可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。 # 2,作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
二、协程介绍
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是协程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
需要强调的是:
# 1,python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) # 2,单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换。
优点如下:
# 1,协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级。 # 2,单线程内就可以实现并发的效果,最大限度地利用cpu。
缺点如下:
# 1,协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程。 # 2,协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程。
总结协程特点:
1)必须在只有一个单线程里实现并发。
2)修改共享数据不需要加锁。
3)用户程序里自己保存多个控制流的上下文栈。
4)附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测,IO,yield,greenlet都无法实现,就用到了gevent模块(select机制))