一、数据库管理软件的由来
基于我们之前所学,数据要想永久保存,都是保存于文件中,毫无疑问,一个文件仅仅只能存在于某一台机器上。
如果我们暂且忽略直接基于文件来存取数据的效率问题,并且假设程序所有的组件都运行在一台机器上,那么用文件存取数据,并没有问题。
很不幸,这些假设都是你自己意淫出来的,上述假设存在以下几个问题。。。。。。
1,程序所有的组件就不可能运行在一台机器上
# 因为这台机器一旦挂掉则意味着整个软件的崩溃,并且程序的执行效率依赖于承载它的硬件,而一台机器机器的性能 # 总归是有限的,受限于目前的硬件水平,就一台机器的性能垂直进行扩展是有极限的。 # 于是我们只能通过水平扩展来增强我们系统的整体性能,这就需要我们将程序的各个组件分布于多台机器去执行。
2,数据安全问题
# 根据1的描述,我们将程序的各个组件分布到各台机器,但需知各组件仍然是一个整体,言外之意,所有组件的数据还是要共享的。 # 但每台机器上的组件都只能操作本机的文件,这就导致了数据必然不一致。 # 于是我们想到了将数据与应用程序分离:把文件存放于一台机器,然后将多台机器通过网络去访问这台机器上的文件(用socket实现), # 即共享这台机器上的文件,共享则意味着竞争,会发生数据不安全,需要加锁处理。。。
3,并发
根据 2的描述,我们必须写一个 socket服务端来管理这台机器(数据库服务器)上的文件,然后写一个 socket客户端,完成如下功能:
# 1,远程连接(支持并发) # 2,打开文件 # 3,读写(加锁) # 4,关闭文件
4,总结
# 我们在编写任何程序之前,都需要事先写好基于网络操作一台主机上文件的程序(socket服务端与客户端程序), # 于是有人将此类程序写成一个专门的处理软件,这就是mysql等数据库管理软件的由来,但mysql解决的不仅仅是数据共享的问题, # 还有查询效率,安全性等一系列问题,总之,把程序员从数据管理中解脱出来,专注于自己的程序逻辑的编写。
二、数据库概述
1,什么是数据(Data)
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字、图片、图像、声音、语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机。
在计算机中描述一个事物,就需要抽取这一事物的典型特征,组成一条记录,就相当于文件里的一行内容,如:
# zixi,male,18,2000,东北,计算机
单纯的一条记录并没有任何意义,如果我们按逗号作为分隔,依次定义各个字段的意思,相当于定义表的标题。
# name,sex,age,birth,born_addr,major # 字段 # zixi,male,18,2000,东北,计算机 # 记录
这样我们就可以了解 zixi,性别为男,年龄18岁,出生于2000年,出生地为东北,计算机专业。
2,什么是数据库(DataBase,简称DB)
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的。
过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用。
数据库是长期存放在计算机内、有组织、可共享的数据即可。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
3,什么是数据库管理系统(DataBase Management System 简称DBMS)
在了解了Data与DB的概念后,如何科学地组织和存储数据,如何高效获取和维护数据成了关键。
这就用到了一个系统软件 ----> 数据库管理系统。
如:MySQL、Oracle、SQLite、Access、MS SQL Server。
mysql主要用于大型门户,例如搜狗、新浪等,它主要的优势就是开放源代码,因为开放源代码这个数据库是免费的,他现在是甲骨文公司的产品。
oracle主要用于银行、铁路、飞机场等。该数据库功能强大,软件费用高。也是甲骨文公司的产品。
sql server是微软公司的产品,主要应用于大中型企业,如联想、方正等。
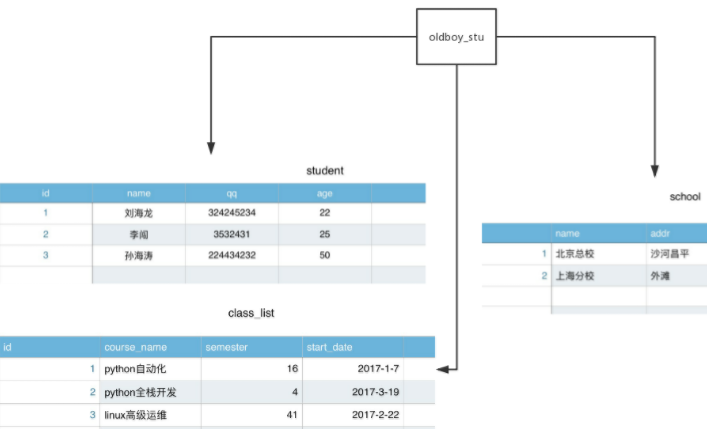
4,数据库服务器、数据管理系统、数据库、表与记录的关系(重点!!!)
记录:1 刘海龙 324245234 22(多个字段的信息组成一条记录,即文件中的一行内容)
表:student,scholl,class_list(即文件)
数据库:oldboy_stu(即文件夹)
数据库管理系统:如mysql(是一个软件)
数据库服务器:一台计算机(对内存要求比较高)
总结:
数据库服务器:运行数据库管理软件
数据库管理软件:管理-数据库
数据库:即文件夹,用来组织文件/表
表:即文件,用来存放多行内容/多条记录
5,数据库管理技术的发展历程(了解)
1)人工管理阶段
20世纪50年代中期以前,计算机主要用于科学计算。
当时的硬件水平:外存只有纸带、卡片、磁带,没有磁盘等直接存取的存储设备。
当时的软件状况:没有操作系统,没有管理数据的软件,数据的处理方式是批处理。
人工管理数据具有以下特点:
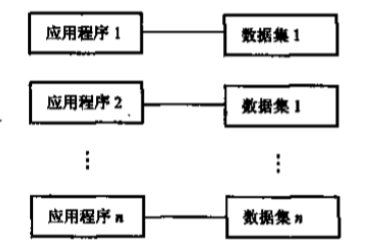
1,数据不保存:计算机主要用于科学计算,数据临时用,临时输入,不保存。
2,应用程序管理数据:数据要有应用程序自己管理,应用程序需要处理数据的逻辑+物理结构,开发负担很重。
3,数据不共享:一组数据只对应一个程序,多个程序之间涉及相同数据时,必须各自定义,造成数据大量冗余。
4,数据不具有独立性:数据的逻辑结构或物理结构发生变化后,必须对应用程序做出相应的修改,开发负担进一步加大。
2)文件系统阶段:
20世纪50年代后期到60年代中期
硬件水平:有了磁盘、磁鼓等可直接存取的存储设备。
软件水平:有了操作系统,并且操作系统中已经有了专门的数据管理软件,即文件系统;处理方式上不仅有了批处理,而且能够联机实时处理。
文件系统管理数据具有以下优点:
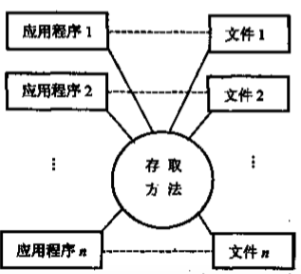
1,数据可以长期保存:计算机大量用于数据处理,因而数据需要长期保存,进行增删改查操作。
2,由文件系统管理数据:文件系统这个软件,把数据组织成相对独立的数据文件,利用按文件名,按记录进行存取。实现了记录内的结构性,但整体无结构。并且程序与数据之间由文件系统提供存取方法进行转换,是应用程序与数据之间有了一定的独立性,程序员可以不必过多考虑物理细节。
文件系统管理数据具有以下缺点:
1,数据共享性差,冗余度大:一个文件对应一个应用程序,不同应用有相同数据时,也必须建立各自的文件,不能共享相同的数据,造成数据冗余,浪费空间,且相同的数据重复存储,各自管理,容易造成数据不一致性。
2,数据独立性差:一旦数据的逻辑结构改变,必须修改应用程序,修改文件结构的定义。应用程序的改变,也将引起文件的数据结构的改变。因此数据与程序之间缺乏独立性。可见,文件系统仍然是一个不具有弹性的无结构的数据集合,即文件之间是孤立的,不能反映现实世界事物之间的内存联系。
3)数据系统阶段:
20世纪60年代后期以来,计算机用于管理的规模越来越大,应用越来越广泛,数据量急剧增长,同时多种应用,多种语言互相覆盖地共享数据结合要求越来越强烈。
硬件水平:有了大容量磁盘,硬件架构下降。
软件水平:软件价格上升(开发效率必须提升,必须将程序员从数据管理中解放出来),分布式的概念盛行。
数据库系统的特点:
1,数据结构化(如上图odboy_stu)
2,数据共享,冗余度低,易扩充
3,数据独立性高
4,数据由DBMS统一管理和控制
a:数据的安全性保护
b:数据的完整性检查
c:并发控制
d:数据库恢复
三、mysql介绍
MySQL是一个关系型数据库管理系统,由瑞典 MySQL AB公司开发,目前属于 Oracle旗下公司。MySQL是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL是最好的RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
1,mysql 是什么?
# mysql就是一个基于 socket编写的C/S架构的软件 # 客户端软件 mysql自带:如 mysql命令,mysqldump命令等 python模块:如 pymysql
2,数据库管理软件分类;
# 分两大类: 关系型:如 sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用 非关系型:mongodb,redis,memcache # 可以简单的理解为: 关系型数据库需要有表结构 非关系型数据库是key-value存储的,没有表结构
四、初识 sql 语句
有了 mysql这个数据库软件,就可以将程序员从对数据的管理中解脱出来,专注于对程序逻辑的编写。
mysql服务端软件即 mysqld帮我们管理好文件夹以及文件,前提是作为使用者的我们,需要下载mysql的客户端,或者其他模块来连接到mysqld,然后使用 mysql软件规定的语法格式去提交自己命令,实现对文件夹或文件的管理。该语法即sql(Structured Query Language 即结构化查询语言)
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由 IBM开发。SQL语言分为 3种类型:
# 1、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER # 2、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT # 3、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
# SQL语句: # 1. 操作文件夹(库) 增: create database db1 charset utf8; 查: show create database db1; show databases; 改: alter database db1 charset gbk; (没有改名一说,只能改字符编码) 删: drop database db1; # 2. 操作文件(表) 先切换到文件夹下:use db1; 查看当前所在的库:select database(); 增: create table t1(id int,name char); 查: show create table t1; show tables; desc t1; (比较友好,更清晰) 改: alter table t1 modify name char(6); alter table t1 change name NAME char(2); 删: drop table t1; # 3. 操作文件中的内容(记录) 增: 1)insert t1(id,name)values(1,"zixi1"),(2,"zixi2"),(3,"zixi3"); 2)insert t1 values(1,"zixi1"),(2,"zixi2"),(3,"zixi3"); (不写id,name,默认就是按字段插入) 查: 1)在db1库中:select id,name from ti; 2)不在db1库中:select id,name from db1.t1; 3)字段太多就用:select * from t1; (虽然方便,但不推荐用) 改: update t1 set name='datou' where id=2; (where指定位置,不加就全改) 删: delete from t1 where id=1; (where指定位置,不加就删除所有记录) 清空表: delete from t1; # 如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。 truncate table t1; # 数据量大,删除速度比上一条快,且直接从零开始, auto_increment # 表示:自增 primary key # 表示:约束(不能重复且不能为空);加速查找