一、自然语言处理与深度学习
自然语言处理应用

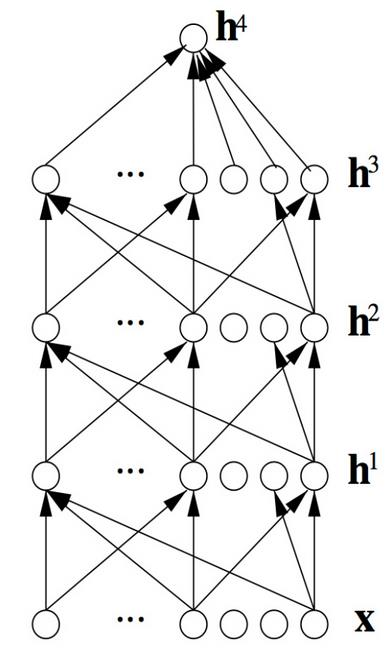
深度学习模型

为什么需要用深度学习来处理呢

二、语言模型
1、语言模型实例:
机器翻译

拼写纠错 智能问答


1)机器翻译,比如要翻译高价,可能 P(high price) > P(large price),然后得到的结果就是high price
2)拼写纠错,比如 fifteen minutes,P(about fifteen minutes from) > P(about fifteenminuets from),一般时分开写的,如果合在一起则会纠正为分开书写
3)语言模型举例
我 今天 下午 打 篮球
p(S) = p(w1,w2,w3,w4,w5,...,wn)
= p(w1)p(w2|w1)p(w3|w1,w2) ... p(wn|w1,w2,...,wn-1)
上式中wi表示每个词
p(S)被称为语言模型,即用来计算一个句子概率的模型
2、语言模型存在哪些问题呢?
p(wi|w1,w2,...,wi-1) = p(w1,w2,...,wi-1,wi) / p(w1,w2,...,wi-1)
1)数据过于稀疏
2)参数空间太大
三、N-gram模型
假设下一个词的出现依赖它前面的一个词:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
假设下一个词的出现依赖它前面的两个词:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2)
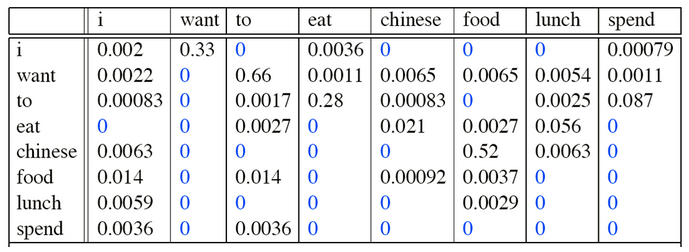
举例:
I want english food
p( I want chinese food ) = P( want|I ) × P( chinese|want ) × P( food|chinese )


假设词典的大小是N,则模型参数的量级是 ![]()
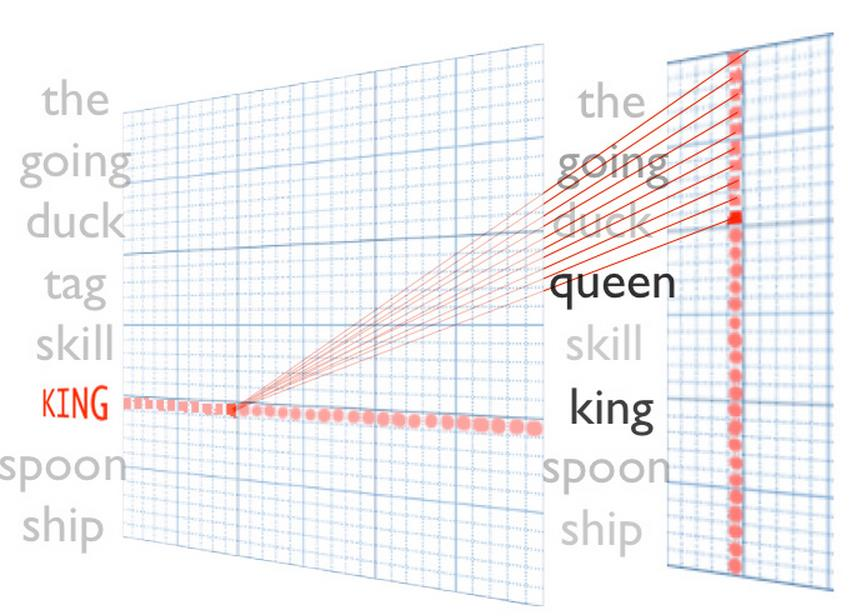
四、词向量



五、神经网络模型
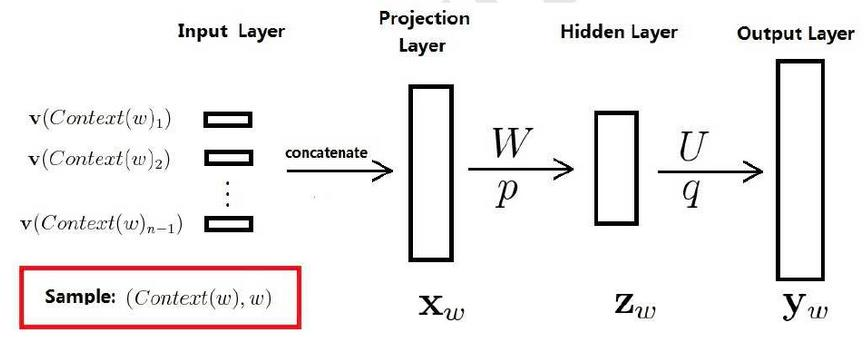
训练样本: ![]() ,包括前n-1个词分别的向量,假定每个词向量大小m
,包括前n-1个词分别的向量,假定每个词向量大小m
投影层:(n-1)*m 首尾拼接起来的大向量
输出: ![]()
表示上下文为 ![]() 时,下一个词恰好为词典中第i个词的概率
时,下一个词恰好为词典中第i个词的概率
归一化: 
神经网络模型的优势
S1 = ‘’我 今天 去 网咖’’ 出现了1000次
S2 = ‘’我 今天 去 网吧’’ 出现了10次
对于S1和S2两句话其实表达的意思差不多的,但
对于N-gram模型: P(S1) >> P(S2),一般会表述为S1
而神经网络模型计算的 P(S1) ≈ P(S2)
对于如下:

在神经网络中,只要语料库中出现其中一个,其他句子的概率也会相应的增大
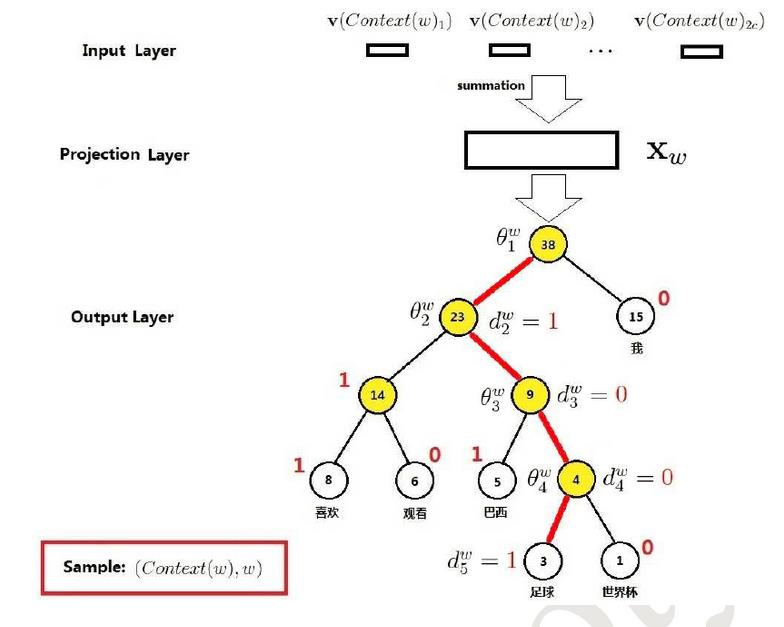
六、Hierarchical Softmax
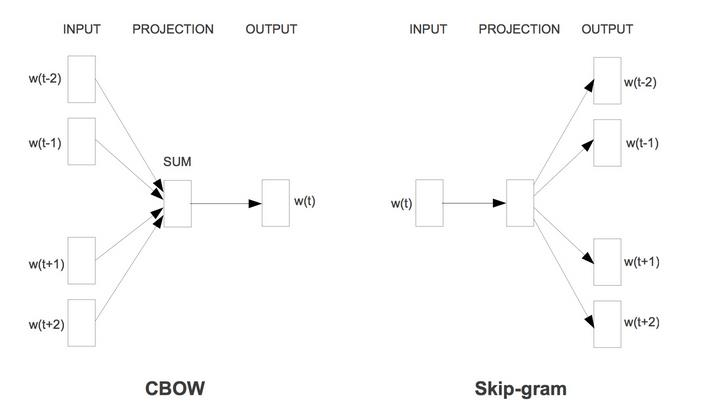
Hierarchical Softmax有两种模型,CBOW,Skip-gram
1、CBOW
CBOW 是 Continuous Bag-of-Words Model 的缩写,是一种根据上下文的词语预测当前词语的出现概率的模型

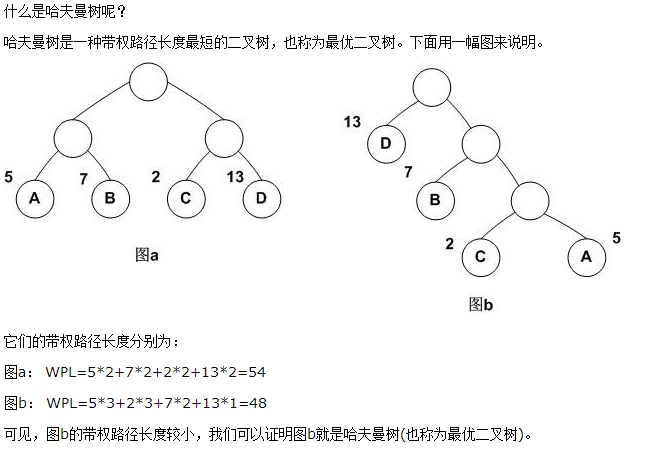
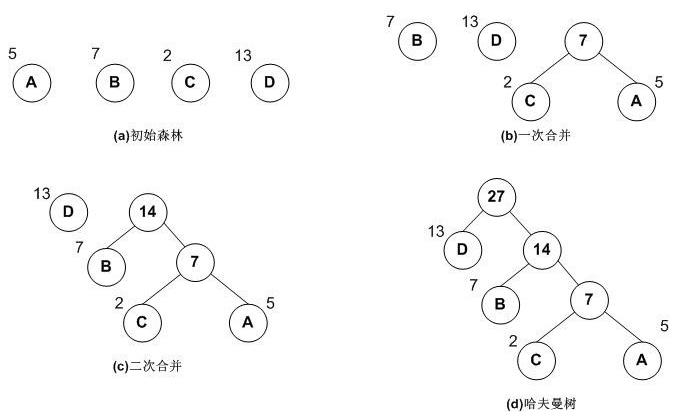
2、哈夫曼树
3、Logistic回归
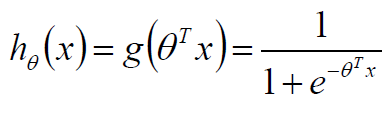
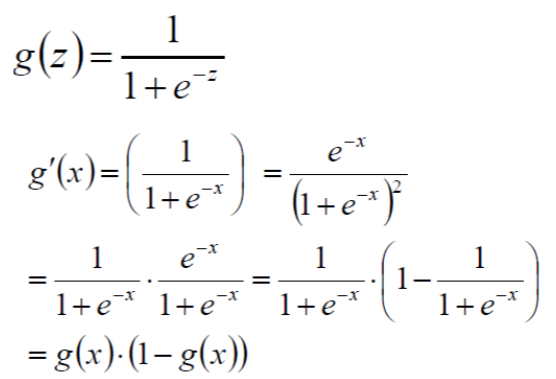
4、CBOW模型推导
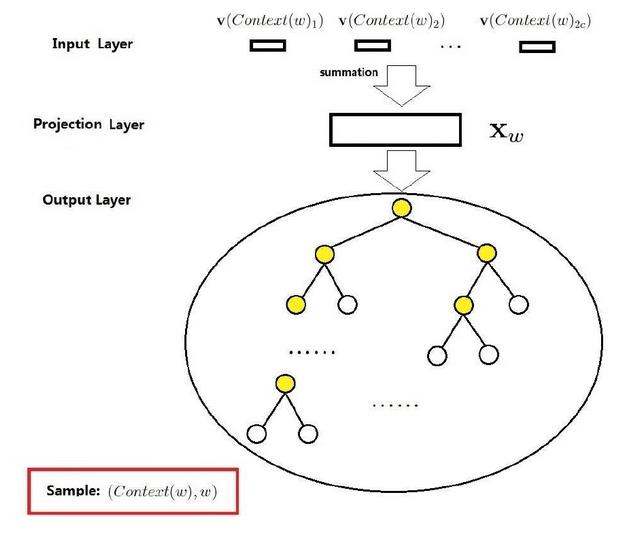
输入层是上下文的词语的词向量,在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新)。
投影层对其求和,所谓求和,就是简单的向量加法。
输出层输出最可能的w。由于语料库中词汇量是固定的|C|个,所以上述过程其实可以看做一个多分类问题。给定特征,从|C|个分类中挑一个。



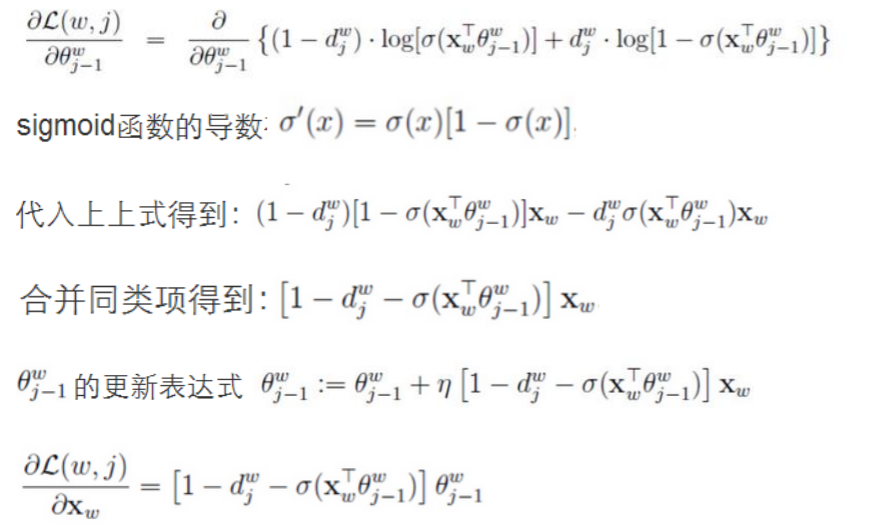

5、Skip-gram模型
1)输入层不再是多个词向量,而是一个词向量
2)投影层其实什么事都没干,直接将输入层的词向量传递给输出层
七、负采样模型(Negative Sampling)
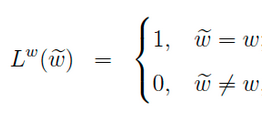
负样本那么多该如何选择呢?
对于一个给定的正样本(Context(w), w),我们希望最大化
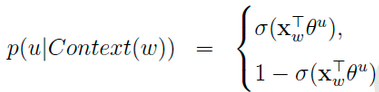
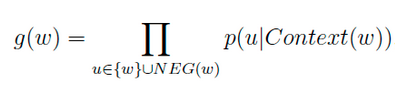


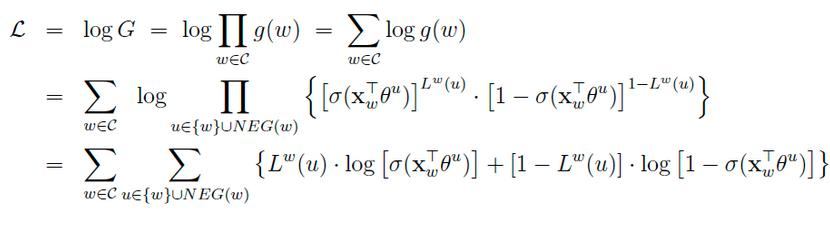
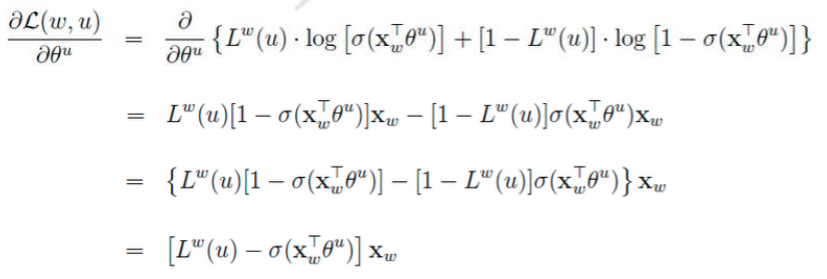

一般大多采用负采样模型来求解,因为Hierarchical softmax模型太过于复杂。