目标检测模型中性能评估的几个重要参数有精确度,精确度和召回率。本文中我们将讨论一个常用的度量指标:均值平均精度,即MAP。
在二元分类中,精确度和召回率是一个简单直观的统计量,但是在目标检测中有所不同的是及时我们的物体检测器在图像中检测到物体,如果我们仍无法找到它所在的图像中的哪个位置也是无用的。由于我们需要预测图像中的目标的发生和位置,所以在计算精确度和召回率与普通的二分类有所不同。
一、目标检测问题
目标检测问题是指:
给定一个图像,找到其中的目标,找到它们的位置,并且对目标进行分类。目标检测模型通常是在一组固定的类上进行训练的,所以模型只能定位和分类图像中的那些类。此外,目标的位置通常是边界矩阵的形式。所以,目标检测需要涉及图像中目标的位置信息和对目标进行分类。所以本文将要描述的均值平均精度(Mean Average Precision)特别适用于我们预测目标与类的位置的算法。同时均值平均值对于评估模型定位性能、目标监测模型性能和分割模型性能都是有用的。
二、评估目标检测模型
1、选择MAP的原因
目标检测问题中的模型的分类和定位都需要进行评估,每个图像都可能具有不同类别的不同目标,因此,在图像分类问题中所使用的标准度量不能直接应用于目标检测问题。
2、Ground Truth 的定义
对于任何算法,度量总是与数据的真实值(Ground Truth)进行比较。我们只知道训练、验证和测试数据集的Ground Truth信息。对于物体检测问题,Ground Truth包括图像,图像中的目标的类别以及图像中每个目标的边界框。
下图给出了一个真实的图像(JPG/PNG)和其他标注信息作为文本(边界框坐标(X, Y, 宽度和高度)和类),其中上图的红色框和文本标签仅仅是为了更好的理解,手工标注可视化显示。 
对于上面的例子,我们在模型在训练中得到了下图所示的目标边界框和3组数字定义的ground truth(假设这个图像是1000*800px,所有这些坐标都是构建在像素层面上的)
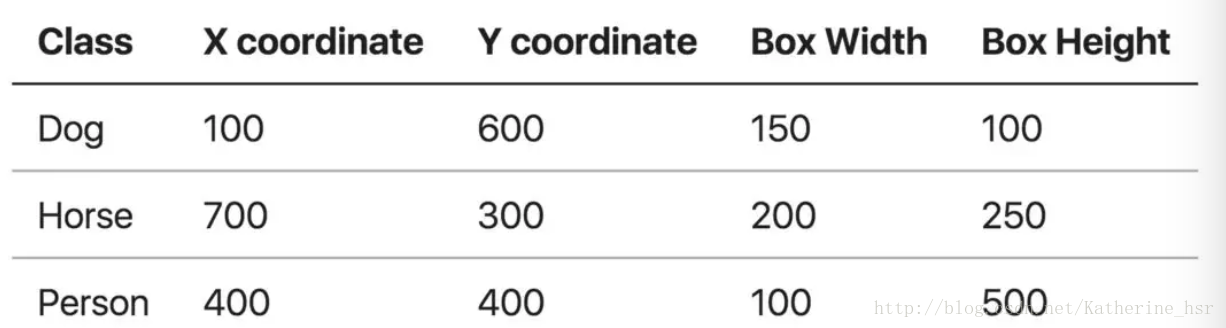
接下来,让我们看看如何计算MAP
3、计算MAP
假设原始图像和真实的标注信息(ground truth)如上所示,训练和验证数据以相同的方式都进行了标注。该模型将返回大量的预测,但是在这些模型中,大多数都具有非常低的置信度分数,因此我们只考虑高于某个置信度分数的预测信息。我们通过我们的模型运行原始图像,在置信阈值确定之后,下面是目标检测算法返回的带有边框的图像区域(bounding boxes)。 
但是怎样在实际中量化这些检测区域的正确性呢?
首先我们需要知道每个检测的正确性。测量一个给定的边框的正确性的度量标准是loU-交幷比(检测评价函数),这是一个非常简单的视觉量。
下面给出loU的简单的解释。
4、loU
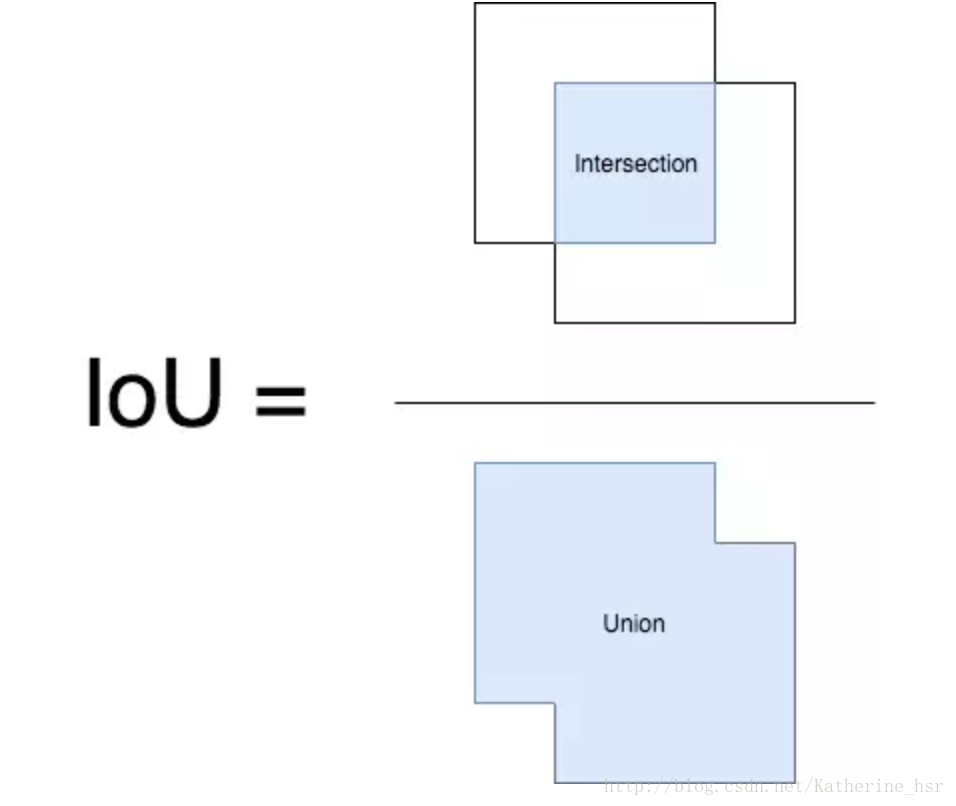
loU(交并比)是模型所预测的检测框和真实(ground truth)的检测框的交集和并集之间的比例。这个数据也被称为Jaccard指数。为了得到交集和并集值,我们首先将预测框叠加在ground truth实际框上面,如下图所示:
现在对于每个类,预测框和真实框重叠的区域就是交集区域,预测框和真实框的总面积区域就是并集框。
在上面的目标马的交集和联合看起来是这样的:

交集包括重叠区域(青色区域), 并集包括橙色和青色区域。
loU(交并比将会这样计算):
识别正确的检测和计算精度
我们使用loU看检测是否正确需要设定一个阈值,最常用的阈值是0.5,即如果loU>0.5,则认为是真实的检测(true detection),否则认为是错误的检测(false detection)。我们现在计算模型得到的每个检测框(置信度阈值后)的loU值。用计算出的loU值与设定的loU阈值(例如0.5)比较,就可以计算出每个图像中每个类的正确检测次数(A)。对于每个图像,我们都有ground truth的数据(即知道每个图像的真实目标信息),因此也知道了该图像中给定类别的实际目标(B)的数量。我们也计算了正确预测的数量(A)(True possitive)。因此我们可以使用这个公式来计算该类模型的精度(A/B)

即给定一张图像的类别C的Precision=图像正确预测(True Positives)的数量除以在图像张这一类的总的目标数量。
假如现在有一个给定的类,验证集中有100个图像,并且我们知道每个图像都有其中的所有类(基于ground truth)。所以我们可以得到100个精度值,计算这100个精度值的平均值,得到的就是该类的平均精度。
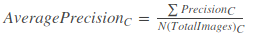
即一个C类的平均精度=在验证集上所有的图像对于类C的精度值的和/有类C这个目标的所有图像的数量。
现在加入我们整个集合中有20个类,对于每个类别,我们都先计算loU,接下来计算精度,然后计算平均精度。所有我们现在有20个不同的平均精度值。使用这些平均精度值,我们可以轻松的判断任何给定类别的模型的性能。
但是问题是使用20个不同的平均精度使我们难以度量整个模型,所以我们可以选用一个单一的数字来表示一个模型的表现(一个度量来统一它们),我们可以取所有类的平均精度值的平均值,即MAP(均值平均精度)。
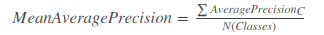
MAP=所有类别的平均精度求和除以所有类别
即数据集中所有类的平均精度的平均值。
使用MAP值时我们需要满足一下条件:
(1) MAP总是在固定的数据集上计算
(2)它不是量化模型输出的绝对度量,但是是一个比较好的相对度量。当我们在流行的公共数据集上计算这个度量时,这个度量可以很容易的用来比较不同目标检测方法
(3)根据训练中类的分布情况,平均精度值可能会因为某些类别(具有良好的训练数据)非常高(对于具有较少或较差数据的类别)而言非常低。所以我们需要MAP可能是适中的,但是模型可能对于某些类非常好,对于某些类非常不好。因此建议在分析模型结果的同时查看个各类的平均精度,这些值也可以作为我们是不是需要添加更多训练样本的一个依据。