1. Notations
循环序列模型的输入和输出都是时间序列。$x^{(i)<t>}$表示第$i$个输入样本的第$t$个元素,$T_x^{(i)}$表示输入的第$i$个样本的元素个数;$y^{(i)<t>}$表示第$i$个样本的输出的第$t$个元素,$T_y^{(i)}$表示第$i$个样本的输出的元素个数。
在NLP领域,为了描述一句话,会有一个词典(vocabulary),里面保存了所有的英文单词(一般包含3万到5万单词),每个单词依次有一个编号。这样每个单词都可以用一个向量表示,每个向量的长度是词典的长度,向量中只有对应单词的位置是1,其他位置都是0。这种描述方式叫“one-hot representation”,因为只有一个元素是激活为非0的。为了处理突然遇到词典中不存在的单词的情况,会创造一个新的标记(或者说伪造的单词)叫“Unknown Word”(可以写成“<UNK>”)。这样就能完整地描述序列。
2. RNN
把输入序列直接扔给一个常规的神经网络有两个缺陷:1)输入和输出会有不同的长度;2)序列不同位置的特征没有能共用,没有做到CNN那样用卷积的方式共用参数。
下图是实际构造的RNN网络(这个网络只用了之前的信息,能够同时用之前和之后信息的网络叫BRNN(Bidirectional RNN)):
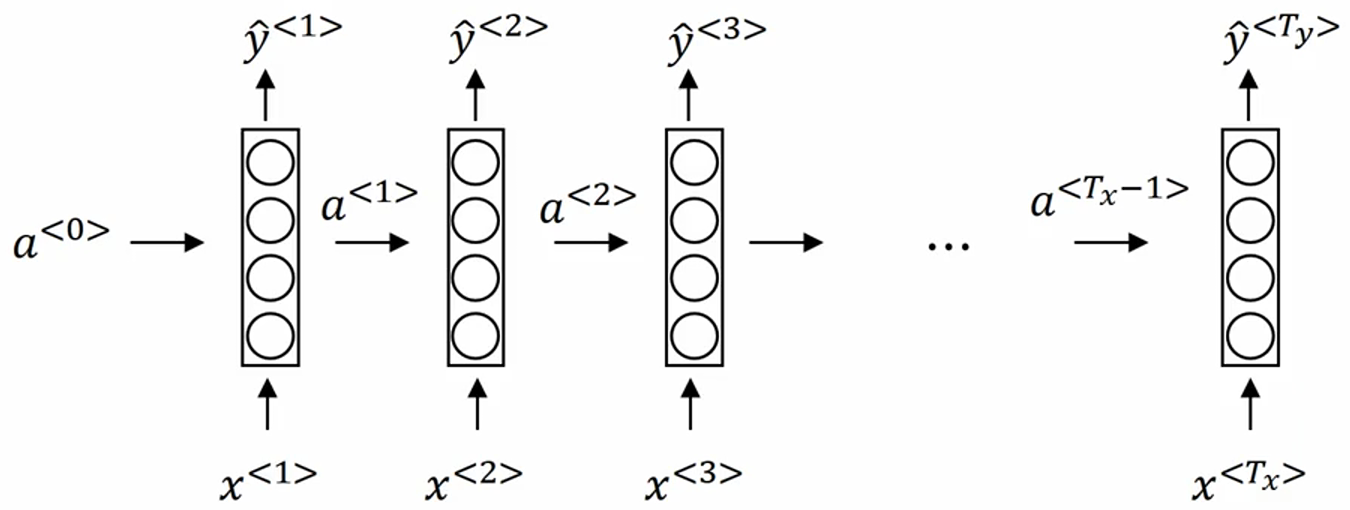
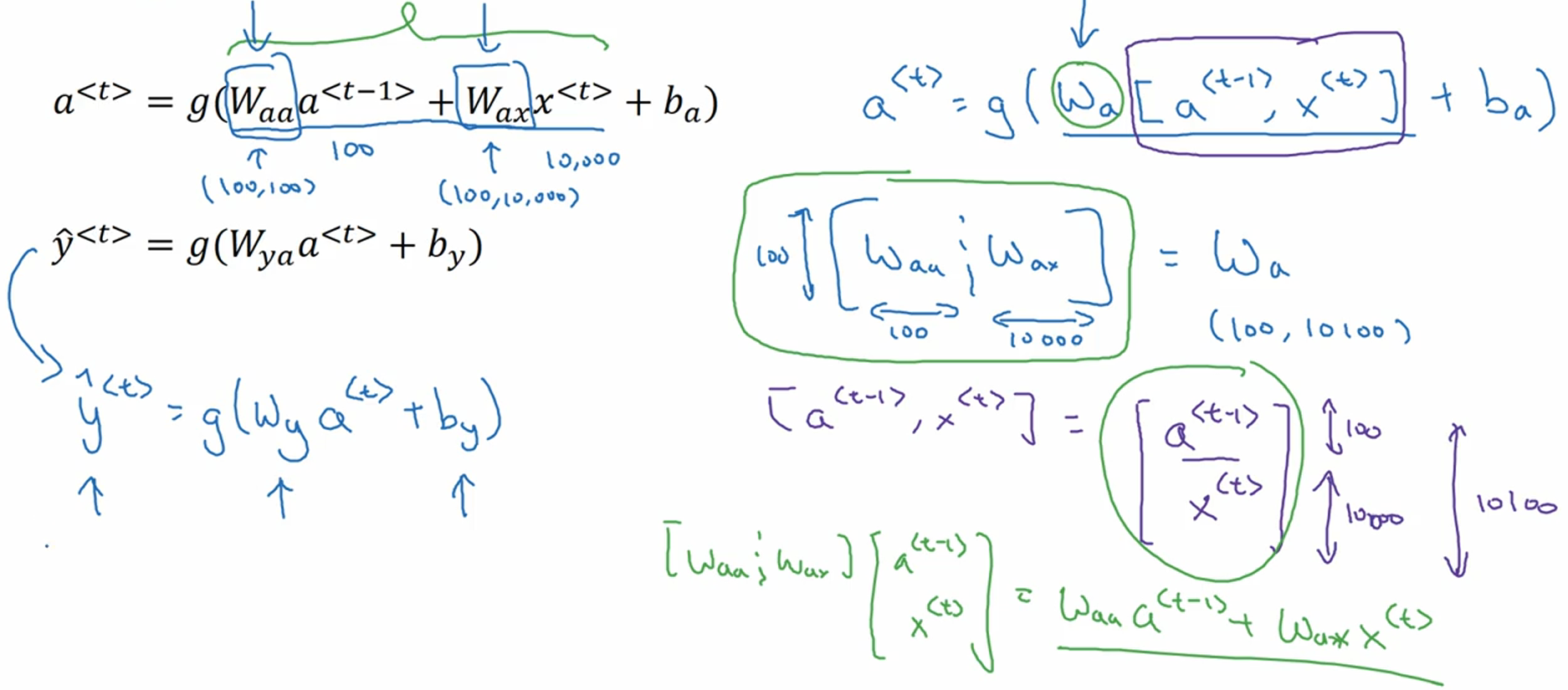
其中,$a^{<t>}=g_1(W_{aa}a^{<t-1>}+W_{ax}x^{<t>}+b_a)$,$g_1$一般是tanh/ReLU函数,tanh非常常见。$a^{<0>}$一般被初始化为全0,也有学者随机初始化,但是全0的初始化方式更常见。$hat{y}^{<t>}=g_2(W_{ya}a^{<t>}+b_y)$,如果是二分类问题,$g_2$会是sigmoid,如果是多分类,$g_1$会是softmax函数。在Andrew Ng的课程里,他把$g_1$和$g_2$都写成了$g$,但我们要知道这两个是不同的激活函数。简单地说,每一轮计算先根据输入x<t>和上一轮的激活值a<t-1>,计算本轮的激活值a<t>,然后再根据本轮的激活值a<t>计算本轮的输出$hat{y}^{<t>}$。
为了更简洁的描述这两个式子,把$W_{aa}$和$W_{ax}$堆叠了起来成为$W_{a}$,$W_{ya}$也简化为$W_{y}$:
3. RNN的反向传播(Backpropagation through time)
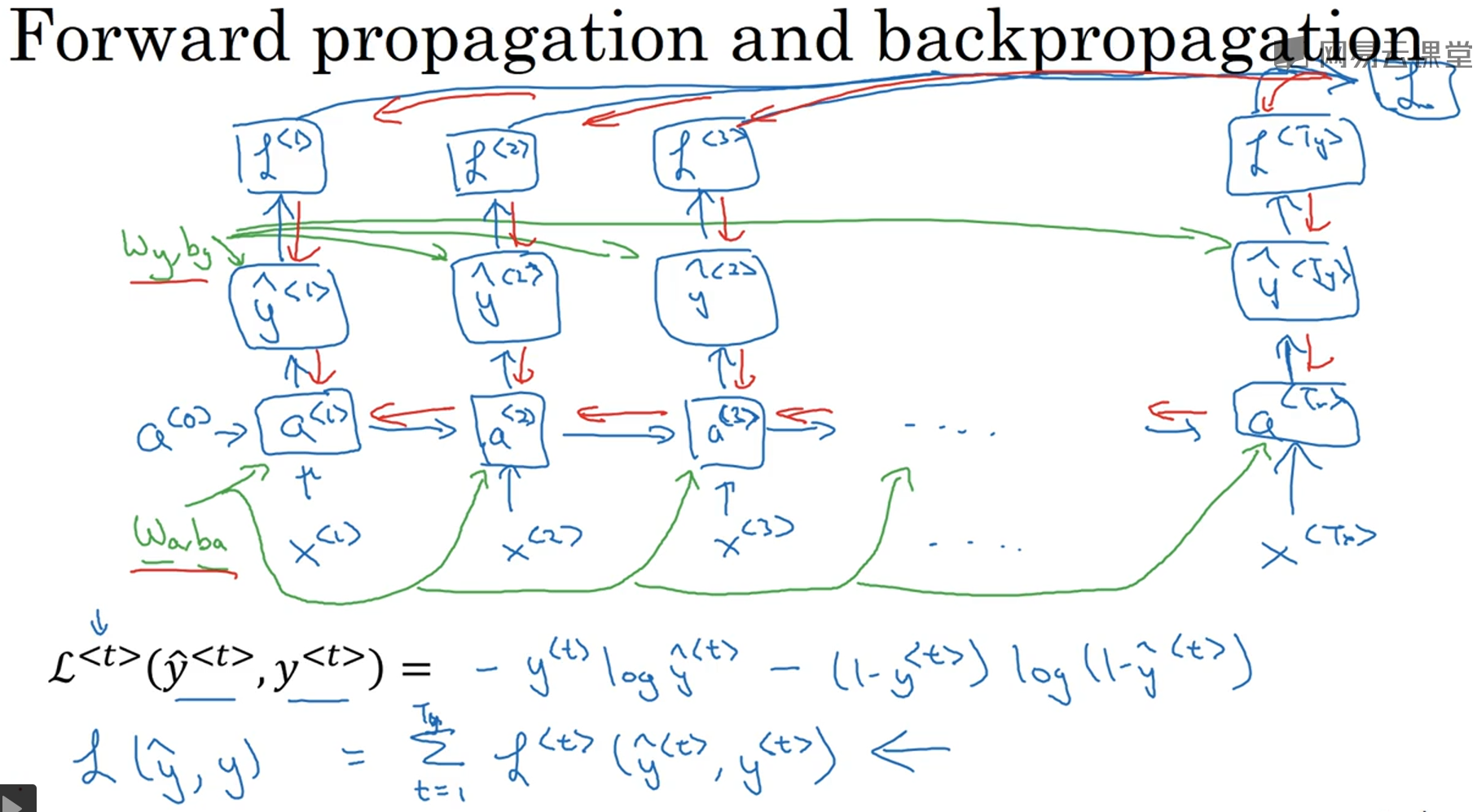
下图定义了element-wise损失函数 L<t> 以及整个序列的损失函数 L,蓝色箭头是正向传播的计算,红色箭头是反向传播的计算,绿色是权重,权重在正向计算时是已知数,而在反向传播时是被更新的数。
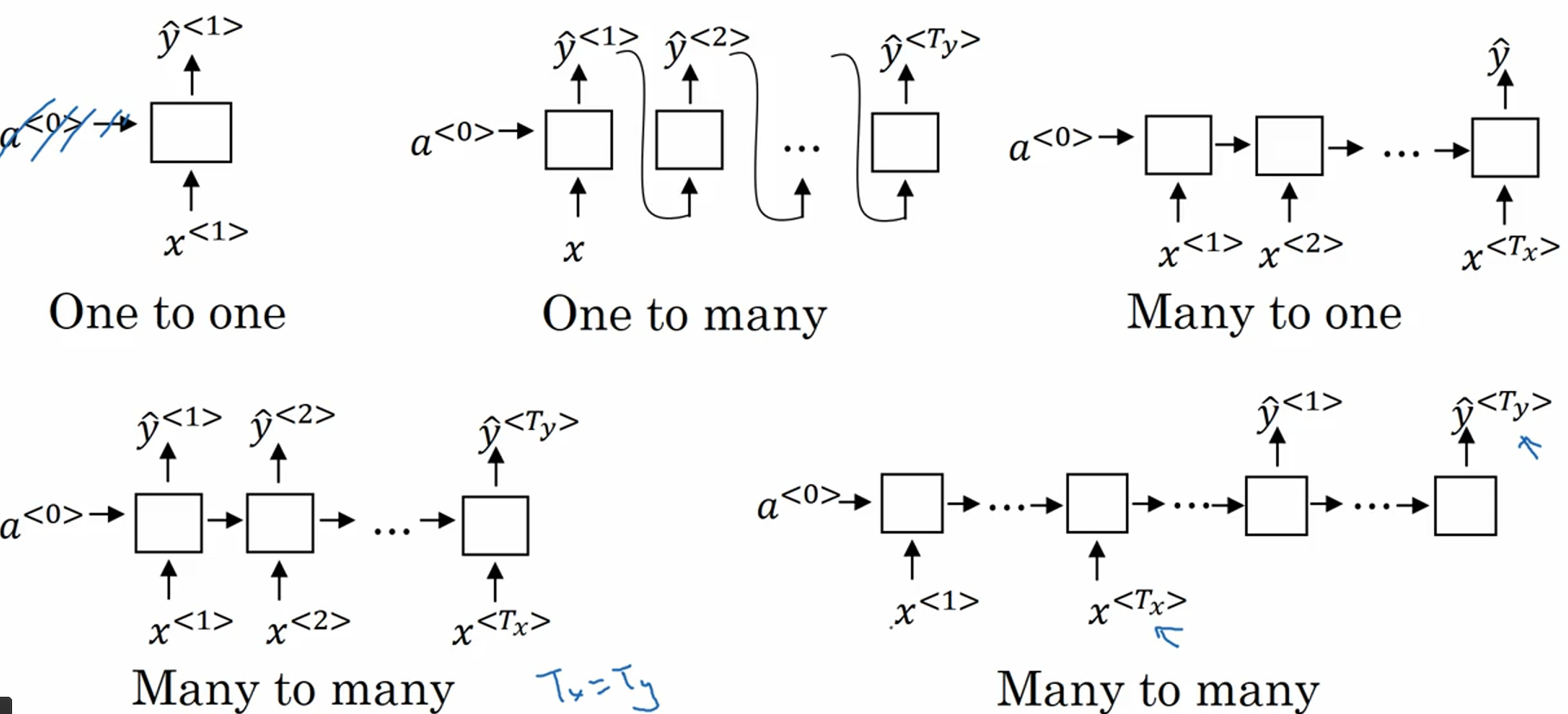
4. 不同类型的RNN
one-to-one: 就是最普通的神经网络,可以说压根不是我们讨论的RNN,这种情况可以省略$a^{<0>}$。
one-to-many: music generation、image captioning。
many-to-one: sentiment classification,根据用户的一句描述句子判定用户的打分,比如1、2、3、4、5分。
many-to-many (同样长度): video classification on frame level。
many-to-many (不同长度): machine translation,前一部分是encoder,后一部分是decoder。
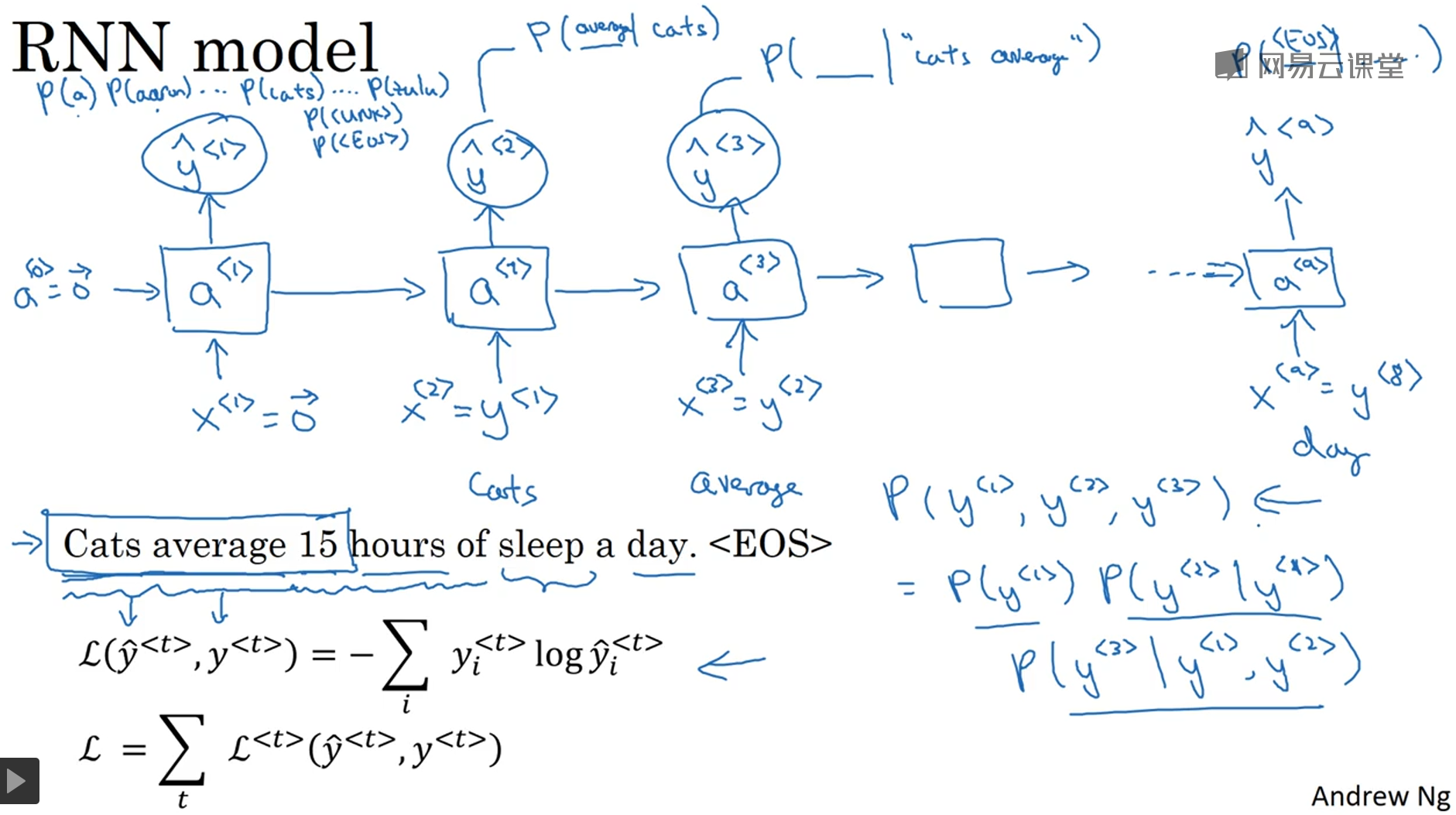
5. 用RNN构建语言模型
语言模型可以判定一个句子正确与否,主要应用于语音识别、机器翻译等领域。对于发音相同的单词,语言模型根据上下文评估它们正确的概率,从而选出最恰当的那一个。传统的语言模型是用统计学方法实现的,现在则广泛的使用RNN来实现。
用RNN实现语言模型,首先要找一个语料库;然后对每个句子标记化(tokenize),意思是把每个单词转换成one-hot vector(也就是词典中的索引),除了上文提到的增加一个<UNK>描述词典中没有的单词,也会增加一个<EOS>(end of sentence)描述一句话的结束,如果需要的话也可以把标点符号加入到词典中。RNN的第一个时间步(time step),把初始输入x<1>和a<0>都设为0向量,输出$hat{y}^{<1>}$描述的是词典中所有单词出现在第一个单词的概率。第二个时间步,输入x<2>是正确的第一个单词y<1>,输出$hat{y}^{<2>}$描述的是在已知第一个单词的情况下第二个单词的概率。以此类推,完成所有时间步。然后根据每一步的预测$hat{y}^{<t>}$和真实的y<t>定义cost function,并得到整体的cost function。
6. Sampling novel sequences
训练好一个RNN网络后,我们可以让它生成新的序列,来了解这个模型学到了什么。具体做法是:1)和训练阶段一样,把a<0>、x<1>设置为0向量,得到输出$hat{y}^{<1>}$描述的是词典中所有单词出现在第一个单词的概率,然后我们根据这个概率分布随机选取出第一个单词,可以利用 np.random.choice。2)把第一步的输出(或者说根据概率分布随机选取的第一个单词)当成第二时间步的输入,即x<2>=$hat{y}^{<1>}$,从而得到输出$hat{y}^{<2>}$。3)依次类推下去。什么时候终止这种采样呢?可以规定当生成了<UNK>就结束,或者自己规定生成单词的数量。
之前说的语言模型都是基于单词(也就是说,词典里都是单词),另一种考虑方式是Character-level language model,此时词典里都是字符,包括大小写字母、标点符号、数字等,比如 Vocabulary = [a, b, ..., z, 空格, 。, ;, ... , 0, 1, ..., 9, A, B, ... Z ]。这种做法的好处是不会遇到词典中没有的单词,各种单词都能处理。缺点是:1)序列会比基于单词的模型长得多,因为一句话可能十几个单词,但是有好多好多字符,所以基于字符的语言模型不太擅长捕捉句子中的依赖关系(比如句子前面的单词如何影响后面的单词);2)训练的计算成本非常高。所以在NLP领域,绝大多数情况都是用基于单词的语言模型,但随着计算机性能越来越好,会有更多的应用开始使用基于字符的模型。有一些特定的应用场景,比如有非常多的词典中不存在的单词(比如专有名词),会很乐于用基于字符的模型。
7. RNN中梯度消失的问题
对于这样的两句话:1) The cat, which already ... , was full. 2) The cats, which already ..., were full. 这种情况表明一句话中的单词会依赖离得很远的单词,cat对应was,cats对应were,中间插入了很长的从句。这种情况普通的RNN很难处理,因为普通的RNN的输出只依赖附近的输入,很难记住很久之前的输入。梯度在一个时间步一个时间步的传播过程中,会遇到vanishing和exploding的问题,这和很多层的深度神经网络一样。相对来说,exploding还好处理一点,因为数据会变得很大以至于出现NaN,我们可以很容易发现,然后可以用梯度修剪(gradient clipping)解决。而vanishing的问题就不是很好发现,就比较难处理。
8. GRU (Gated Recurrent Unit) 门控制循环单元
GRU可以很好地处理上节提到的RNN中梯度消失的问题,从而使得RNN可以捕获距离更远的单词之间的依赖关系。两篇论文:1)Cho et al., 2014. On the properties of neural machine translation: Encoder-decoder approaches. 2) Chung et al., 2014. Empirical Evalution of Gated Recurrent Neural Networks on Sequence Modeling.
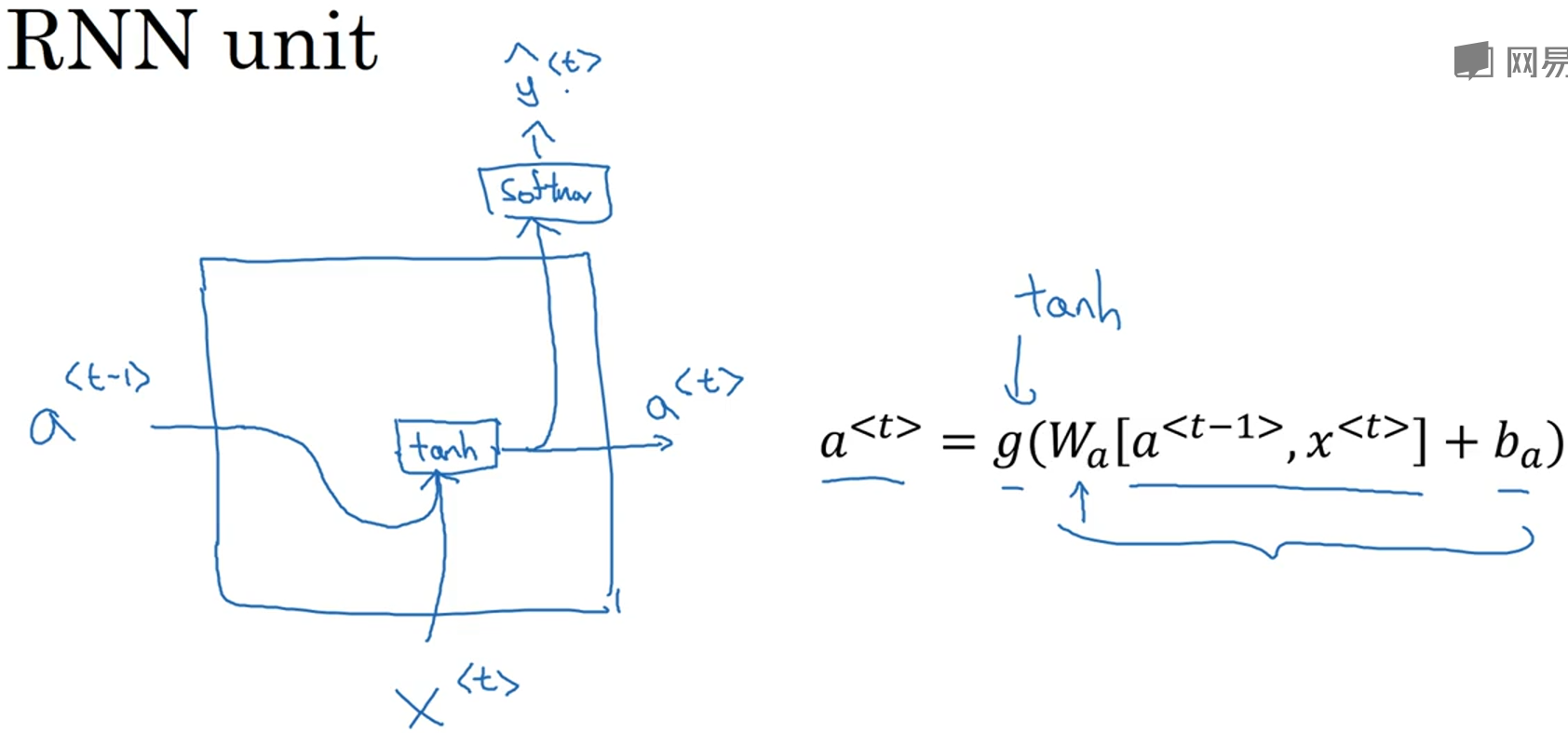
为了更好地描述GRU,先来看RNN单元的一种可视化描述:a<t-1>和x<t>作为输入加权求和后经过一个非线性激活函数(这里假设是tanh)得到输出a<t>,并且可以通过另一个非线性激活函数(这里假设是softmax)得到输出$hat{y}^{<t>}$。
下图是简化版的GRU,定义了一个新的变量 c,用来记忆单词的特性(比如cat是单数还是复数)。在GRU中,c<t> = a<t>,在LSTM中,两者是不等价的。每一个时间步,先计算出$ ilde{c}^{<t>}$,这是c<t>的后选值。c<t>是否真的等于$ ilde{c}^{<t>}$则取决于另一个变量$Gamma_u$(符号的意思是更新门,update gate)。$Gamma_u$取值在0、1之间,由sigmoid函数得到,目的是控制何时更新c<t>。比如,在看到cat时,$Gamma_u$为1,更新c<t>为1表示是单数,之后$Gamma_u$一直为0,c<t>一直不更新,所以看到was时仍然记得cat是单数。另外,由于要记忆好多不同的量,所以c<t>是一个n维的向量,于是$Gamma_u$也是同样维度的向量,$Gamma_u* ilde{c}^{<t>}$的*是对应元素的乘积。

完整版的GRU如下图所示,增加了一个新的变量$Gamma_r$(r是relevance的缩写),描述了计算$ ilde{c}^{<t>}$时,跟c<t-1>有多大的相关性。
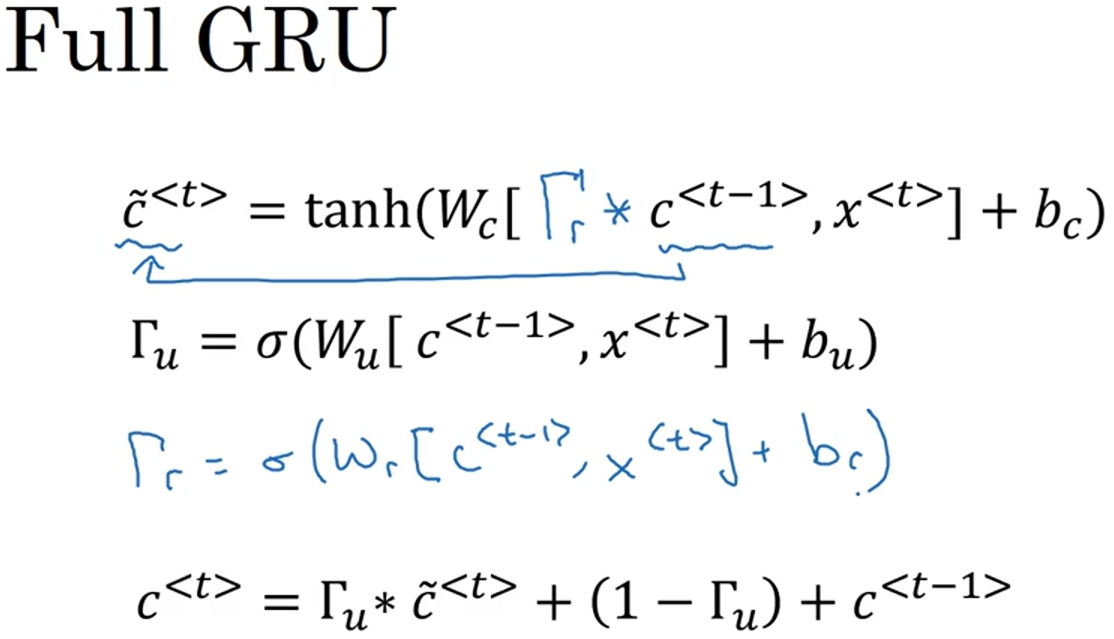
9. LSTM (Long Short Term Memory) unit
LSTM和GRU一样,都是为了捕获词语之间更长时间的依赖关系,而且LSTM比GRU更强大更通用。论文:Hochreiter & Schmidhuber 1997, Long short-term memory。相比于GRU的两个门(update gate、relavance gate),LSTM有三个门(update gate、forget gate、output gate),在计算c<t>时,GRU是在$ ilde{c}^{<t>}$和c<t-1>之间二选一,而LSTM则可以二者叠加。另外,LSTM中,a<t>不再等于c<t>,而是由$Gamma_o$控制。
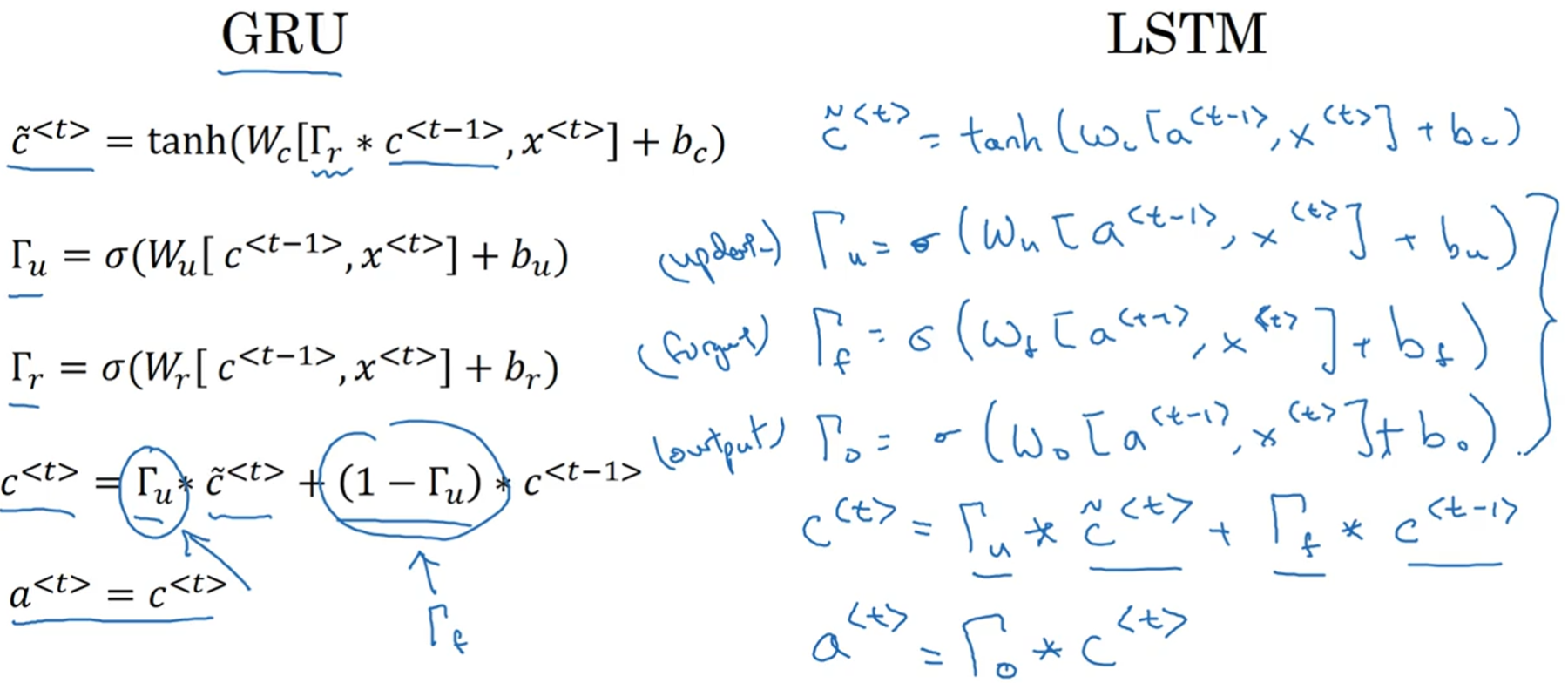
下图是LSTM的可视化描述。另外可以注意到多个LSTM单元可以串联起来,只要设置好门的参数,c<0>可以很方便地直接传递给c<3>,或者说网络保持了对c<0>的记忆。

何时使用GRU,何时使用LSTM?没有统一的标准。在深度学习的发展史上,LSTM是比GRU更早出现的,GRU可以看成是对LSTM的简化。GRU的优点是:1)模型简单,更容易创建更大的网络;2)只有两个门,所以运行更快。LSTM的优点:因为有三个门,所以更强大、更灵活。所以如果必须二选一,可以把LSTM作为默认的选择来尝试,但Andrew NG认为近些年GRU获得了很多支持。
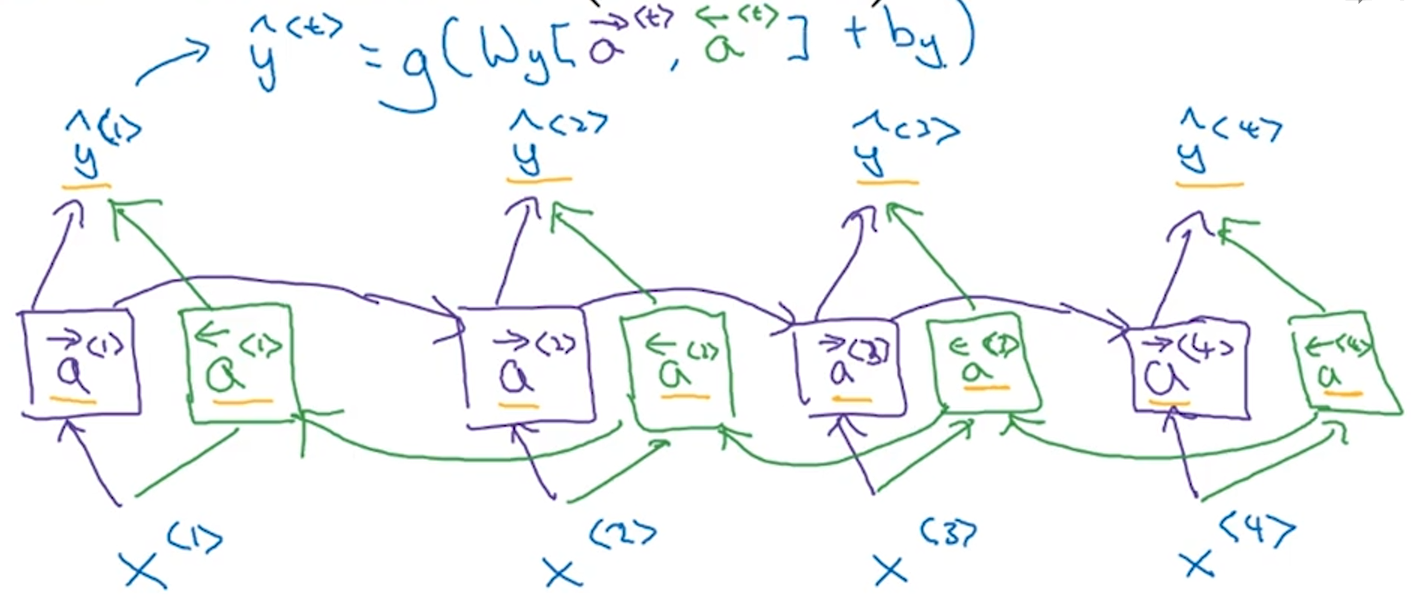
10. 双向RNN(Bidirectional RNN)模型
这种模型可以在计算时获取之前和之后的信息。和之前的单向RNN相比,双向RNN从前到后计算了一遍$overrightarrow{a}^{<t>}$之后,还从后到前又计算了一遍$overleftarrow{a}^{<t>}$,这里用左箭头和右箭头区分a<t>。如下图所示,具体计算流程是,先计算$overrightarrow{a}^{<1>}$到$overrightarrow{a}^{<4>}$,再计算$overleftarrow{a}^{<4>}$到$overleftarrow{a}^{<1>}$。值得注意的是,这里的反向计算依旧是前向传播,而不是求导调整权重的那个反向传播。把所有的$overrightarrow{a}^{<t>}$和$overleftarrow{a}^{<t>}$都计算完了,然后可以预测$hat{y}^{<t>}$。这里计算a<t>的单元可以不仅仅是标准的RNN,也可以是GRU或者LSTM。对于很多NLP问题,基于LSTM单元的双向RNN是最常见的模型。双向RNN的缺点是:必须计算完整的序列,才能预测任意时间步的输出。比如语音输入的场景,双向RNN需要等用户说完才能获取结果。
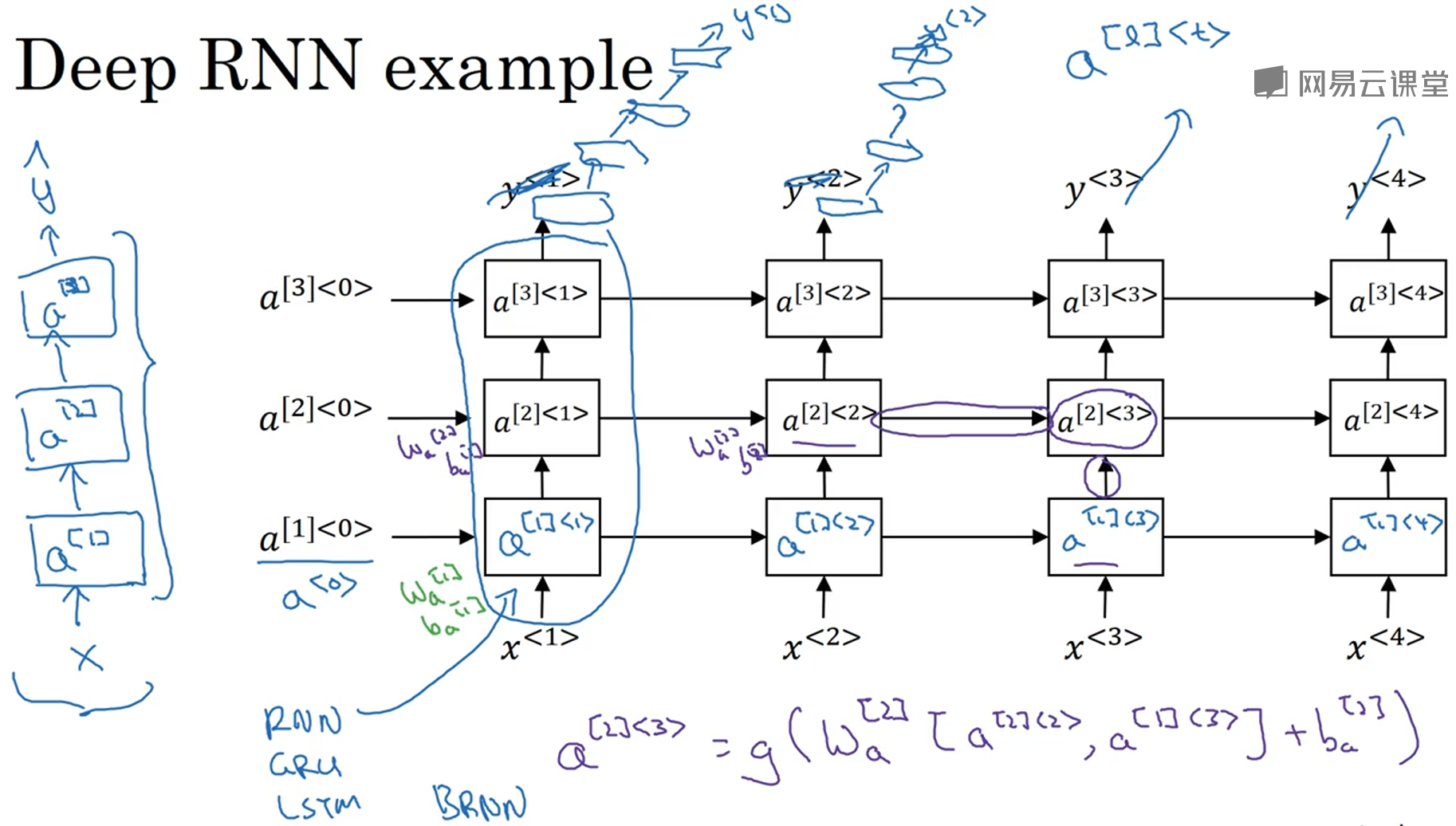
11. 深层循环神经网络(Deep RNNs)
为了学习更复杂的函数,像标准的神经网络一样,通常我们会把多个RNN网络堆叠起来,构建更深、更复杂的模型。用a[l]<t>表示第l层网络的第t个时间步的激活值,为了计算a[l]<t>每一层有自己的权重Wa[l]和ba[l]。对于一般的神经网络,可能有100多层的深度,而对于RNN来说,三层已经很多了,因为有水平方向时间步的连接,网络已经非常大。但是在计算y<t>时,可能会串联一个很深的常规神经网络,这个很深的网络只是纵向连接,并不水平方向连接。而计算a[l]<t>的单元可以不是标准的RNN,而是GRU或者LSTM。另外,也可以拓展到深层的双向RNN网络。