# 使用selenium+phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏览器翻页,并得到商品信息 # 第三步:爬取商品信息 # 第四步:存储到mongodb
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException from config import * import re
browser = webdriver.PhantomJS(executable_path='/usr/bin/phantomjs',service_args=SERVICE_ARGS)
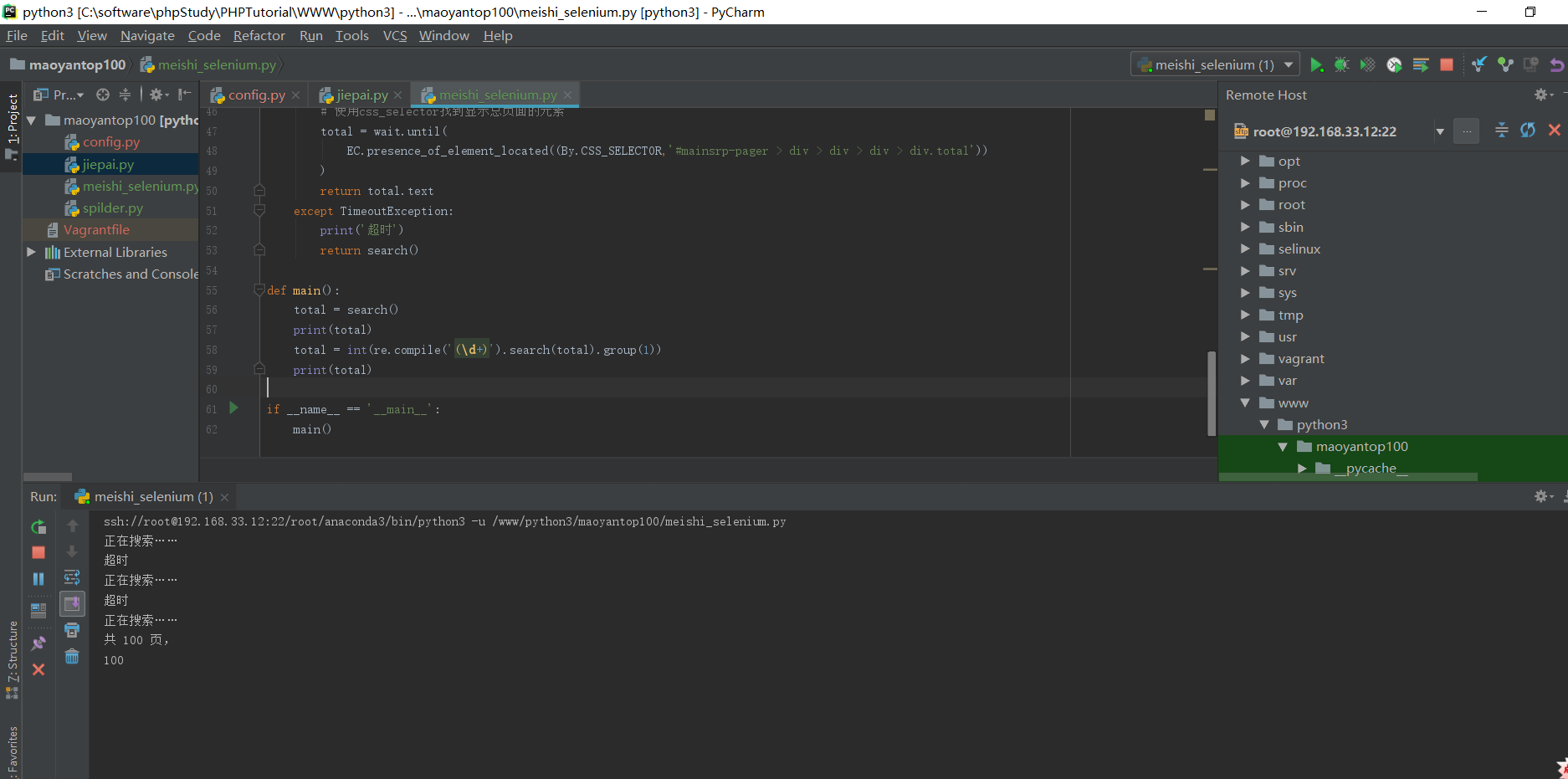
# 表示给browser浏览器一个10秒的加载时间 wait = WebDriverWait(browser,10) # 使用webdriver打开chrome,打开淘宝页面,搜索美食关键字,返回总页数 def search(): print('正在搜索……') try: # 打开淘宝首页 browser.get('http://www.taobao.com') # 判断输入框是否已经加载 input = wait.until( EC.presence_of_element_located((By.ID,'q')) ) # < selenium.webdriver.remote.webelement.WebElement(session="d575fc60-91a9-11e8-917b-3dd730d5073d",element=":wdc:1532701944023") > # 判断搜索按钮是否可以进行点击操作 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')) ) # 输入美食 input.send_keys(KEYWORD) # 点击搜索按钮 submit.click() # 使用css_selector找到显示总页面的元素 total = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')) ) return total.text except TimeoutException: print('超时') return search() def main(): total = search() print(total) total = int(re.compile('(d+)').search(total).group(1)) print(total) if __name__ == '__main__': main()
phantomJS爬数据比较慢,下面的测试结果,大概经过5分多钟才返回结果,正在搜索和超时提示返回比较慢
phantojs的其他配置方法:
# 引入配置对象DesiredCapabilities
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
dcap = dict(DesiredCapabilities.PHANTOMJS)
# 从USER_AGENTS列表中随机选一个浏览器头,伪装浏览器
dcap["phantomjs.page.settings.userAgent"] = USER_AGENTS
# 不载入图片,爬页面速度会快很多
dcap["phantomjs.page.settings.loadImages"] = False
# 设置代理
service_args = ['--disk-cache=true','--load-images=false']
# 打开带配置信息的phantomJS浏览器
browser = webdriver.PhantomJS(executable_path='/usr/bin/phantomjs', desired_capabilities=dcap, service_args=service_args)
# 隐式等待5秒,可以自己调节
browser.implicitly_wait(5)
# 设置10秒页面超时返回,类似于requests.get()的timeout选项,driver.get()没有timeout选项
# 以前遇到过driver.get(url)一直不返回,但也不报错的问题,这时程序会卡住,设置超时选项能解决这个问题。
browser.set_page_load_timeout(10)
# 设置10秒脚本超时时间
browser.set_script_timeout(10)
完整代码
# 使用selenium+phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏览器翻页,并得到商品信息 # 第三步:爬取商品信息 # 第四步:存储到mongodb from selenium import webdriver from config import * from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException import re from pyquery import PyQuery as pq import pymongo # client = pymongo.MongoClient(MONGO_URL) client = pymongo.MongoClient(host='192.168.33.12', port=27017) db = client[MONGO_DB_SELENIUM] browser = webdriver.PhantomJS(executable_path=EXECUTABLE_PATH,service_args=SERVICE_ARGS) browser.set_window_size(1400, 1000) # 表示给browser浏览器一个10秒的加载时间 wait = WebDriverWait(browser,10) # 使用webdriver打开chrome,打开淘宝页面,搜索美食关键字,返回总页数 def search(): print('正在搜索……') try: # 打开淘宝首页 browser.get('http://www.taobao.com') # 判断输入框是否已经加载 input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'#q')) ) # 判断搜索按钮是否可以进行点击操作 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')) ) # 输入美食 input.send_keys(KEYWORD_SELENIUM) # 点击搜索按钮 submit.click() # 使用css_selector找到显示总页面的元素 total = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')) ) # 获取商品信息 get_products() return total.text except TimeoutException: print('超时') return search() # 跳转到下一页 def next_page(page_number): try: # 输入要跳转的页数 input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")) ) # 确认进行跳转 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")) ) input.clear() input.send_keys(page_number) submit.click() # 判断当前的页数与网页的高亮显示是否对应得上 wait.until( EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"), str(page_number)) ) # 获取商品信息 get_products() except TimeoutException: next_page(page_number) # 获取商品信息 def get_products(): # 判断商品是否加载成功 wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item")) ) # 获取页面信息 html = browser.page_source
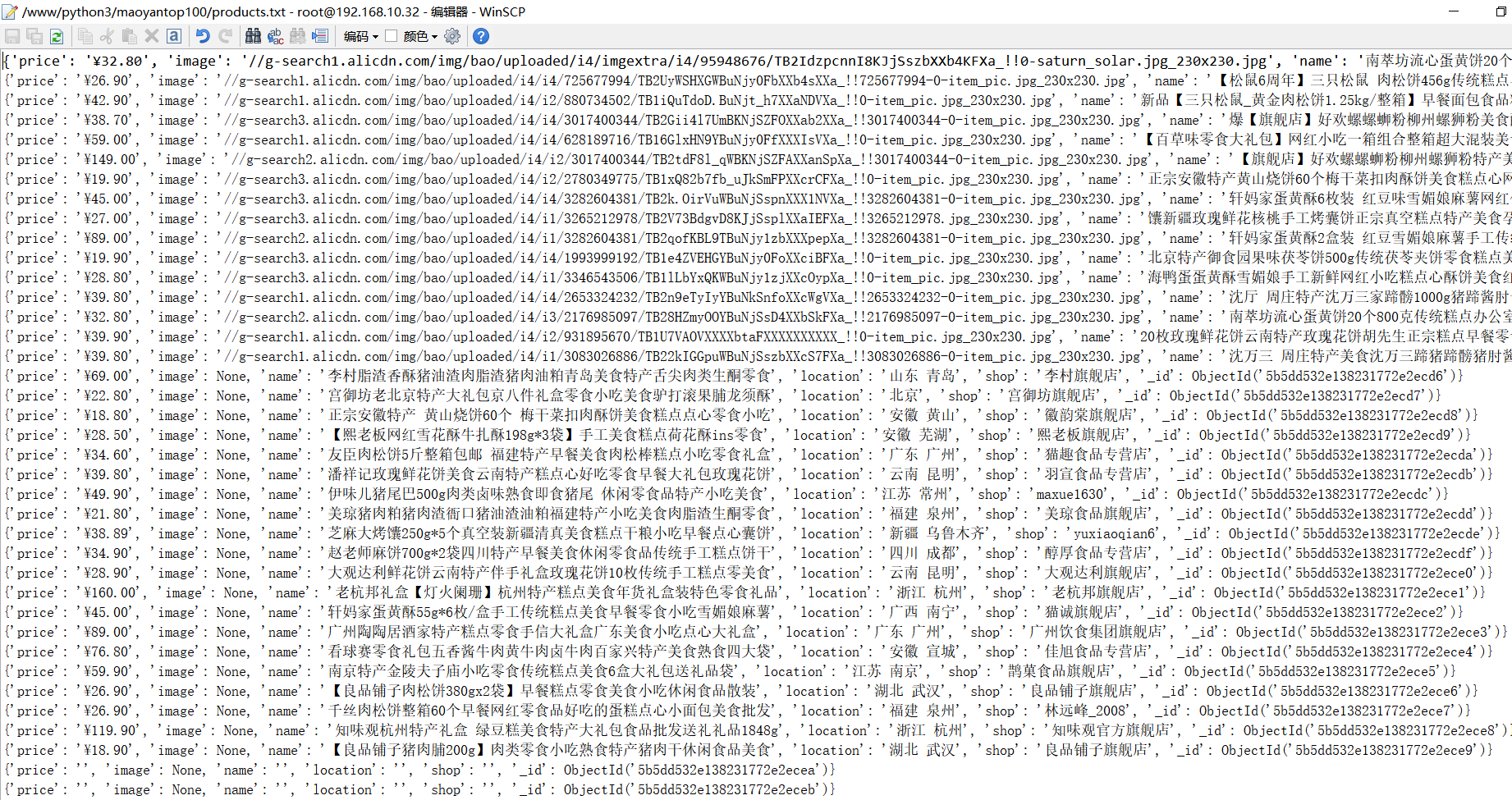
# 使用PyQuery来解析html doc = pq(html) items = doc("#mainsrp-itemlist .items .item").items() for item in items: product = { # 去掉价格中的换行符 "price": item.find(".price").text().replace(" ", ""), "image": item.find(".pic .img").attr("src"), "name": item.find(".title").text(), "location": item.find(".location").text(), "shop": item.find(".shop").text(), } """ 需要保存的商品信息: (1)商品的图片 (2)商品的价格 (3)商品的名字 (4)商品来源 (5)商品店铺 """ # print(product) # {'price': '¥32.80', # 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i4/95948676/TB2IdzpcnnI8KJjSszbXXb4KFXa_!!0-saturn_solar.jpg_230x230.jpg', # 'name': '南萃坊流心蛋黄饼20个800克传统糕点办公室网红零食小吃美食整箱', 'location': '浙江 杭州', 'shop': '南萃坊旗舰店'} save_products(product) # print("=" * 30) # == == == == == == == == == == == == == == == # 将商品的信息存储到MongoDB数据库、txt文件中 def save_products(result): try: # 尝试将结果集插入到数据库中 if db[MONGO_TABLE_SELENIUM].insert(result): print("存储到MongoDB数据库成功!", result) # 存储到MongoDB数据库成功! {'price': '¥33.00', # 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/i2/110202222/TB2k.9bhcj_B1NjSZFHXXaDWpXa_!!110202222.jpg_230x230.jpg', # 'name': '陕西特产红星软香酥小吃美食零食礼包早餐糕点豆沙西安网红千层饼', 'location': '陕西 咸阳', 'shop': '红星软香酥专卖', # '_id': ObjectId('5b5dd570e138231772e2ef5d')} # == == == == == == == == == == == == == == == # {'price': '¥24.90', # 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i1/13621870/TB2V3LhX56guuRjy1XdXXaAwpXa_!!0-saturn_solar.jpg_230x230.jpg', # 'name': '卜珂椰丝球椰蓉球美食早餐糕点心好吃的点心休闲零食品批发店小吃', 'location': '江苏 苏州', 'shop': '卜珂巧克力旗舰店'} # 存储到MongoDB数据库成功! {'price': '¥24.90', # 'image': '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i1/13621870/TB2V3LhX56guuRjy1XdXXaAwpXa_!!0-saturn_solar.jpg_230x230.jpg', # 'name': '卜珂椰丝球椰蓉球美食早餐糕点心好吃的点心休闲零食品批发店小吃', 'location': '江苏 苏州', 'shop': '卜珂巧克力旗舰店', # '_id': ObjectId('5b5dd575e138231772e2ef5e')} # == == == == == == == == == == == == == == == # 将结果集存储到txt文件中 if result: with open("products.txt", "a", encoding="utf-8") as f: f.write(str(result) + " ") f.close() except Exception: print("存储失败!", result) def main(): try: total = search() # print(total) total = int(re.compile('(d+)').search(total).group(1)) # print(total) for i in range(2, total + 1): next_page(i) except Exception: print("出错啦!") finally: browser.close() # 最后一定都要关闭浏览器 if __name__ == '__main__': main()

参考博文: