转载:https://www.cnblogs.com/chensiqiqi/p/6382080.html
sed 介绍
- Sed命令是操作,过滤和转换文本内容的强大工具。常用功能有增删改查(增加,删除,修改,查询),其中查询的功能中最常用的2大功能是过滤(过滤指定字符串),取行(取出指定行)
- Sed软件从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行
- 节省内存使用,快速处理文本文件
sed 命令选项
Sed软件有两个内置的存储空间:
- 模式空间(pattern space):是sed软件从文本读取一行文本然后存入的缓冲区(这个缓冲区是在内存中的),然后使用sed命令操作模式空间的内容。
- 保持空间(hold space):是sed软件另外一个缓冲区,用来存放临时数据,也是在内存中,但是模式空间和保持空间的用途是不一样的。Sed可以交换保持空间和模式空间的数据,但是不能在保持空间上执行普通的sed命令,也就是说我们可以在保持空间存储数据。
5,选项说明
| option[选项] | 解释说明(带*的为重点) |
|---|---|
| -n | 取消默认的sed软件的输出,常与sed命令的p连用。* |
| -e | 一行命令语句可以执行多条sed命令 |
| -f | 选项后面可以接sed脚本的文件名 |
| -r | 使用扩展正则表达式,默认情况sed只识别基本正则表达式* |
| -i | 直接修改文件内容,而不是输出到终端,如果不使用-i选项sed软件只是修改在内存中的数据,并不会影响磁盘上的文件* |
| sed -commands[sed命令] | 解释说明(带*的为重点) |
|---|---|
| a | 追加,在指定行后添加一行或多行文本* |
| c | 取代指定的行 |
| d | 删除指定的行* |
| D | 删除模式空间的部分内容,直到遇到换行符 结束操作,与多行模式相关 |
| i | 插入,在指定行前添加一行或多行文本* |
| h | 把模式空间的内容复制到保持空间 |
| H | 把模式空间的内容追加到保持空间 |
| g | 把保持空间的内容复制到模式空间 |
| G | 把保持空间的内容追加到模式空间 |
| x | 交换模式空间和保持空间的内容 |
| l | 打印不可见的字符 |
| n | 清空模式空间的内容并读入下一行 |
| N | 不清空模式空间,并读取下一行数据并追加到模式空间* |
| p | 打印模式空间内容,通常p会与选项-n一起使用* |
| P(大写) | 打印模式空间的内容,直到遇到换行符 结束操作 |
| q | 退出Sed |
| r | 从指定文件读取数据 |
| s | 取代,s#old#new#g==>这里g是s命令的替代标志,注意和g命令区分。* |
| w | 另存,把模式空间的内容保存到文件中 |
| y | 根据对应位置转换字符 |
| :label | 定义一个标签 |
| b label | 执行该标签后面的命令 |
| t | 如果前面的命令执行成功,那么就跳转到t指定的标签处,继续往下执行后续命令。否则,仍然继续正常的执行流程 |
| 特殊符号 | 解释说明(带*的为重点) |
|---|---|
| ! | 对指定行以外的所有行应用命令* |
| = | 打印当前行行号 |
| ~ | “First~step”表示从First行开始,以步长Step递增 |
| & | 代表被替换的内容 |
| : | 实现一行命令语句可以执行多条sed命令* |
| {} | 对单个地址或地址范围执行批量操作 |
| + |
地址范围中用到的符号,做加法运算 |
第二章
实验样例
cat >>/test/files/person.txt<<KOF
101,zoulixiang,CEO
102,Alex,coo
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
KOF
sed中到底使用单引号还是双引号?这里给大家详细说说引号的区别。
- 双引号:把双引号的内容输出出来;如果内容中有命令,变量等,会先把命令,变量解析出结果,然后再输出最终内容来。双引号内命令或变量的写法为`命令或变量`或$(命令或变量)
- 单引号:所见即所得,将单引号内的内容原样输出,阻止所有字符的转义
- 不加引号:不会将含有空格的字符串视为一个整体输出,如果内容中有命令,变量等,会先把命令,变量解析出结果,然后再输出最终内容来,如果字符串含有空格等特殊字符,则不能完整输出,则需改加双引号。
- 倒引号(反引号Esc键下方):进行命令的替换,在倒引号内部的shell命令将会被执行,其结果输出代替用倒引号括起来的文本。
实例1:
[root@harbor files]# sed '2a 106,dandan,CSO' person.txt
101,zoulixiang,CEO
102,Alex,coo
106,dandan,CSO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
命令解释:
2a :a为追加, 2代表第二行, 0,1,2 所有即在103上面。但不写入文件中(需要加其他参数)
[root@harbor files]# sed '2i $PATH' person.txt
101,zoulixiang,CEO
$PATH
102,Alex,coo
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
命令解释:
' ' 单引号 : 原样输出
实例3:
[root@harbor files]# sed "2i $PATH" person.txt
101,zoulixiang,CEO
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
102,Alex,coo
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
[root@harbor files]#
命令解释:
" "双引号:先将 $PATH(代表环境变量) 输出到屏幕中
实例4
[root@harbor files]# echo "zoulixiang";echo "zoulixinag"
zoulixiang
zoulixinag
;代表将两条命令换行
[root@harbor files]# echo -e "zoulixiang
zoulixiang"
zoulixiang
zoulixiang
[root@harbor files]#
命令解释:
/n 为分隔符, 和;效果一样
e参数表示字符串中如果出现以下特殊字符( 代表换行, 代表Tab键等),则加以特殊处理,而不会将它当成一般文字输出。
实例5
[root@harbor files]# sed '2a 106,dandan,CSO
107,bingbing,CCO' person.txt
101,zoulixiang,CEO
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
效果同上
实例6
[root@harbor files]# echo
> zoulixiang
> is
> me
zoulixiang is me
[root@harbor files]#
命令解释
这个符号可以将一条完整的命令分成多行,举个例子:
实例7
优化SSH配置(一键完成增加若干参数)
Port 52113
PermitRootLogin no
PermitEmptyPasswords no
UseDNS no
GSSAPIAuthentication no
sed -i '13i Port 52113 PermitRootLogin no PermitEmptyPasswords no UseDNS no GSSAPIAuthentication no' /etc/ssh/sshd_config
命令解释
13i 在13行前增加 这5行命令 ; sed 前面加i 直接对文件内容做出修改
实战8
[root@harbor files]# sed -n '15,17p' /etc/ssh/sshd_config
# semanage port -a -t ssh_port_t -p tcp #PORTNUMBER
#
#Port 22
[root@harbor files]#
命令解释
查看文本内容, 选项-n 与命令p 的具体用法
实战9
[root@harbor files]# cat person.txt
101,zoulixiang,CEO
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
[root@harbor files]# sed -i '1d' person.txt
[root@harbor files]# cat person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
[root@harbor files]#
命令解释
-i 对文件内容修改, 1d: 代表删除第一行 d 代表delete 的意思
6.2.2.1指定执行的地址范围
sed软件可以对单行或多行文本进行处理。如果在sed命令前面不指定地址范围,那么默认会匹配所有行。
用法:n1[,n2]{sed -commands}
地址用逗号分隔开,n1,n2可以用数字,正则表达式,或者二者的组合表示。
| 地址范围 | 含义 |
|---|---|
| 10{sed-commands} | 对第10行操作 |
| 10,20{sed-commands} | 对10到20行操作,包括第10,20行 |
| 10,+20{sed-commands} | 对10到30(10+20)行操作,包括第10,30行 |
| 1~2{sed-commands} | 对1,3,5,7.....行操作 |
| 10,${sed-commands} | 对10到最后一行($代表最后一行)操作,包括第10行 |
| /chensiqi/{sed-commands} | 对匹配chensiqi的行操作 |
| /chensiqi/,/Alex/{sed-commands} | 对匹配chensiqi的行到匹配Alex的行操作 |
| /chensiqi/,${sed-commands} | 对匹配chensiqi的行到最后一行操作 |
| /chensiqi/,10{sed-commands} | 对匹配chensiqi的行到第10行操作,注意:如果前10行没有匹配到chensiqi,sed软件会显示10行以后的匹配chensiqi的行 |
| 1,/Alex/{sed-commands} | 对第1行到匹配Alex的行操作 |
| /chensiqi/,+2{sed-commands} |
对匹配chensiqi的行到其后的2行操作 |
第10章
实例1
[root@harbor files]# sed '2,5d' person.txt
102,Alex,coo
105,Jery,CTO
命令解释
删除第2行到第5行。
实例2
[root@harbor files]# sed '/yy/d' person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
104,Tom,CIO
105,Jery,CTO
[root@harbor files]#
命令解释:匹配 yy并且删除
实例3
[root@harbor files]# sed '/yy/,/Tom/d' person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
105,Jery,CTO
[root@harbor files]#
命令解释
匹配两个并且删除
实例4
[root@harbor files]# sed '4,$d' person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
[root@harbor files]#
命令解释
从第4行开始直到行尾都删除
实例4
[root@harbor files]# cat person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
[root@harbor files]# sed '/Alex/,3d' person.txt
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
[root@harbor files]#
命令解释
匹配Alex 以下三行都删除
实例5
[root@harbor files]# sed '$a 109,test,COF' person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
108,qiqi,CFF
101,qiqi1,CFO
109,test,COF
[root@harbor files]#
命令解释:
$a 行尾追加的意思
[root@harbor files]# sed '$a 109,test,COF' person.txt |sed '/yy/,3d'
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
104,Tom,CIO
105,Jery,CTO
108,qiqi,CFF
101,qiqi1,CFO
109,test,COF
[root@harbor files]# sed '$a 109,test,COF' person.txt |sed '/yy/,$d'
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
[root@harbor files]#
命令解释
$a 行尾追加, 匹配yy 删除以下3行
$a 行尾追加, 匹配yy 删除以下行尾
第11章
例子:
- 1~2 匹配1,3,5,7.....#-->用于只输出奇书行,大伙仔细观察一下每个数字的差值。
- 2~2 匹配2,4,6,8....#-->用于只输出偶数行
- 1~3 匹配1,4,7,10.....
- 2~3 匹配2,5,8,11.....
[root@chensiqi1 ~]# seq 10
1
2
3
4
5
6
7
8
9
10
命令说明:seq命令能够生成从1到10的数字序列。
[root@chensiqi1 ~]# seq 10 | sed -n '1~2p'
1
3
5
7
9
命令说明:
上面的命令主要验证特殊符号“~”的效果,其他sed命令用法n和p请见后文详解,大家只需要知道这个命令可以将“1~2”指定的行显示出来即可。
上面例子测试了“1~2”的效果,大家也可以手动测试一下“2~2”,“1~3”,“2~3”,看一下他们的结果是不是符合等差数列。
[root@chensiqi1 ~]# seq 1 2 10
1
3
5
7
9
命令说明:seq命令格式seq起始值 公差 结束值
[root@chensiqi1 ~]# sed '1~2d' person.txt
102,zhangyang,CTO
104,yy,CFO
命令说明:“1~2”这是指定行数的另一种格式,从第1行开始以步长2递增的行(1,3,5),因此删掉第1,3,5行,即所有的奇数行。
[root@chensiqi1 ~]# sed '1,+2d' person.txt
104,yy,CFO
105,feixue,CIO
命令说明:这其实是做个加法运算,‘1,+2d’==>删除第1行到第3(1+2)行的文本。
从第1行开始删除+2d 知道第2行(0,1,2)
实例3
[root@harbor files]# sed '2,3!d' person.txt
106,dandan,CSO
107,bingbing,CCO
命令解释
从第2行开始保留到第3行, ! 代表取反的意思, 保留
实例4
打印文件内容但不包含yy
[root@harbor files]# sed '/yy/d' person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
104,Tom,CIO
105,Jery,CTO
108,qiqi,CFF
101,qiqi1,CFO
命令说明:删除包含“yy”的行,就直接用正则匹配字符串yy即可
第12章
sed 替换
首先说一下按行替换,这个功能用的很少,所以大家了解即可。这里用到的sed命令是:
“c”:用新行取代旧行,记忆方法:c的全拼是change,意思是替换。
实例1
[root@harbor files]# sed '1c 106,zoulixiang,coo' person.txt
106,zoulixiang,coo
106,dandan,CSO
107,bingbing,CCO
103,yy,CFO
104,Tom,CIO
105,Jery,CTO
108,qiqi,CFF
101,qiqi1,CFO
命令解释
1c 代表替换第一行
文本替换
- 接下来说的这个功能,有工作经验的同学应该非常的熟悉,因为使用sed软件80%的场景就是使用替换功能。
- 这里用到的sed命令,选项:
“s”:单独使用-->将每一行中第一处匹配的字符串进行替换==>sed命令
“g”:每一行进行全部替换-->sed命令s的替换标志之一(全局替换),非sed命令。
“-i”:修改文件内容-->sed软件的选项,注意和sed命令i区别。
sed软件替换模型
sed -i 's/目标内容/替换内容/g' chensiqi.log
sed -i 's#目标内容#替换内容#g'
观察特点
1,两边是引号,引号里面的两边分别为s和g,中间是三个一样的字符/或#作为定界符。字符#能在替换内容包含字符/有助于区别。定界符可以是任意字符如:或|等,但当替换内容包含定界符时,需要转义:或|.经过长期实践,建议大家使用#作为定界符。
2,定界符/或#,第一个和第二个之间的就是被替换的内容,第二个和第三个之间的就是替换后的内容。
3,s#目标内容#替换内容#g ,“目标内容”能用正则表达式,但替换内容不能用,必须是具体的。因为替换内容使用正则的话会让sed软件无所适从,它不知道你要替换什么内容。
4,默认sed软件是对模式空间(内存中的数据)操作,而-i选项会更改磁盘上的文件内容。
实例1
[root@harbor files]# sed 's#yy#cc#g' person.txt
102,Alex,coo
106,dandan,CSO
107,bingbing,CCO
103,cc,CFO
104,Tom,CIO
105,Jery,CTO
108,qiqi,CFF
101,qiqi1,CFO
[root@harbor files]#
命令解释
直接将yy替换成了cc
实例2
[root@chensiqi1 ~]# sed '3s#0#9#' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
193,Alex,COO
104,yy,CFO
105,feixue,CIO
命令说明:
前面学习的例子在sed命令“s”前没有指定地址范围,因此默认是对所有行进行操作。
而这个案例要求只将第3行的0换成9,这里就用到了我们前面学过的地址范围知识,在sed命令“s”前加上“3”就代表对第3行进行替换
#直接将第三行的0替换成了9
实例3 变量替换
[root@harbor files]# cat > test.txt <<EOF
> a
> b
> a
> EOF
[root@harbor files]# cat test.txt
a
b
a
[root@harbor files]#
[root@harbor files]# x=a
[root@harbor files]# y=b
[root@harbor files]# echo $x
a
[root@harbor files]# echo $x $y
a b
[root@harbor files]#
[root@harbor files]# sed s#$x#$y#g test.txt
b
b
b
命令解释
将变量x=a 替换成了 $y=b 最终输出的都是 y=b
实例4使用eval命令:
# eval sed 's#$x#$y#g' test.txt
b
b
b
命令说明:这里给大家扩展一个Linux内置命令eval,这个命令能读入变量,并将他们组合成一个新的命令,然后执行。首先eval会解析变量$x和变量$y,最后达到的效果和双引号是一样的。扩展:最快速的获取IP地址的方法
[root@harbor files]# hostname -I |awk '{print $2}'
192.168.1.195
命令解释
直接获取IP
6.2.3.4 分组替换()和1的使用说明
sed软件的()的功能可以记住正则表达式的一部分,其中,1为第一个记住的模式即第一个小括号中的匹配内容,2第二个记住的模式,即第二个小括号中的匹配内容,sed最多可以记住9个。
例:echo "I am chensiqi teacher."如果想保留这一行的单词chensiqi,删除剩下部分,使用圆括号标记想保留的部分。
[root@chensiqi1 ~]# echo "I am chensiqi teacher." | sed 's#^.*am ([a-z]+) tea.*$#1#g'
chensiqi
[root@chensiqi1 ~]# echo "I am chensiqi teacher." | sed -r 's#^.*am ([a-z]+) tea.*$#1#g'
chensiqi
[root@chensiqi1 ~]# echo "I am chensiqi teacher." | sed -r 's#I (.*) (.*) teacher.#12#g'
amchensiqi
命令说明:
sed如果不加-r后缀,那么默认不支持扩展正则表达式,需要符号进行转义。小括号的作用是将括号里的匹配内容进行分组以便在第2和第3个#号之间进行sed的反向引用,1代表引用第一组,2代表引用第二组
实例1
[root@harbor files]# ip addr |sed -n '9p' |sed -r 's#inet (.*) brd.*$#1#g'
192.168.2.198/24
[root@harbor files]# ip addr |sed -n '9p' |sed -r 's#inet (.*) brd.*$#1#g' |awk -F"/" '{print $1}'
192.168.2.198
再来看个题目:请执行命令取出linux中的eth0的IP地址?
[root@chensiqi1 ~]# ifconfig eth0 | sed -n '2p'
inet addr:192.168.197.133 Bcast:192.168.197.255 Mask:255.255.255.0
[root@chensiqi1 ~]# ifconfig eth0 | sed -n '2p' | sed -r 's#^.*addr:(.*) Bcast:.*$#1#g'
192.168.197.133
也可以进行组合
[root@chensiqi1 ~]# ifconfig eth0 | sed -rn '2s#^.*addr:(.*) Bcast:.*$#1#gp'
192.168.197.133
命令说明:
这道题是需要把ifconfig eth0执行结果的第2行的IP地址取出来,上面答案的思路是用IP地址来替换第2行的内容。
企业案例4:系统开机启动项优化(利用sed)
[root@chensiqi1 ~]# chkconfig --list | egrep -v "sshd|crond|rsyslog|sysstat|network" | awk '{print $1}' |sed -r 's#^(.*)#chkconfig 1 off#g' |bash
这题也可以应用awk直接一步到位
[root@chensiqi1 ~]# chkconfig --list | egrep -v "sshd|crond|network|rsyslog|sysstat" | awk '{print "chkconfig",$1,"off"}' | bash
[root@harbor files]# sed -r 's#(.*),(.*),(.*)#& --- 1 2 3#' person.txt
102,Alex,coo --- 102 Alex coo
106,dandan,CSO --- 106 dandan CSO
107,bingbing,CCO --- 107 bingbing CCO
103,yy,CFO --- 103 yy CFO
104,Tom,CIO --- 104 Tom CIO
105,Jery,CTO --- 105 Jery CTO
108,qiqi,CFF --- 108 qiqi CFF
101,qiqi1,CFO --- 101 qiqi1 CFO
[root@harbor files]# sed -r 's#(.*),(.*),(.*)# 1 2 3#' person.txt
102 Alex coo
106 dandan CSO
107 bingbing CCO
103 yy CFO
104 Tom CIO
105 Jery CTO
108 qiqi CFF
101 qiqi1 CFO
命令说明:
1,这里将分组替换和&符号放在一起对比
2,命令中的分组替换使用了3个小括号,每个小括号分别代表每一行以逗号作为分隔符的每一列。
3,上面命令的&符号代表每一行,即模型中‘s#目标内容#替换内容#g’的目标内容。
实例1
[root@harbor files]# for i in {1..5};do echo "<h3>test<h3>" > stu_102999_$i\_fin.jpg; done
创建测试文件
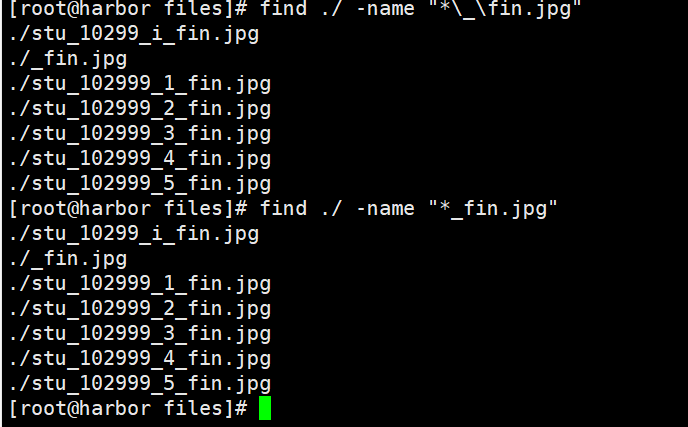
实例2
批量重命名
[root@harbor files]# find ./ -name "*_fin.jpg" |sed -r 's#^(.*)_fin(.*)#12#g'
./stu_10299_i.jpg
./.jpg
./stu_102999_1.jpg
./stu_102999_2.jpg
./stu_102999_3.jpg
./stu_102999_4.jpg
./stu_102999_5.jpg
[root@harbor files]# find ./ -name "*_fin.jpg" |sed -r 's#^(.*)_fin(.*)#& 12#g'
./stu_10299_i_fin.jpg ./stu_10299_i.jpg
./_fin.jpg ./.jpg
./stu_102999_1_fin.jpg ./stu_102999_1.jpg
./stu_102999_2_fin.jpg ./stu_102999_2.jpg
./stu_102999_3_fin.jpg ./stu_102999_3.jpg
./stu_102999_4_fin.jpg ./stu_102999_4.jpg
./stu_102999_5_fin.jpg ./stu_102999_5.jpg
[root@harbor files]# ffind ./ -name "*_fin.jpg" |sed -r 's#^(.*)_fin(.*)#mv & 12#g'
-bash: ffind: command not found
[root@harbor files]# find ./ -name "*_fin.jpg" |sed -r 's#^(.*)_fin(.*)#mv & 12#g'
mv ./stu_10299_i_fin.jpg ./stu_10299_i.jpg
mv ./_fin.jpg ./.jpg
mv ./stu_102999_1_fin.jpg ./stu_102999_1.jpg
mv ./stu_102999_2_fin.jpg ./stu_102999_2.jpg
mv ./stu_102999_3_fin.jpg ./stu_102999_3.jpg
mv ./stu_102999_4_fin.jpg ./stu_102999_4.jpg
mv ./stu_102999_5_fin.jpg ./stu_102999_5.jpg
[root@harbor files]# ls
awkfile.txt file3.txt ip.txt stu_102999_. stu_102999_3_fin.jpg stu_10299_i_fin.jpg
count.txt file.txt person.txt stu_102999_1_fin.jpg stu_102999_4_fin.jpg stu_10299_.jpg
file2.txt _fin.jpg reg.txt stu_102999_2_fin.jpg stu_102999_5_fin.jpg test.txt
[root@harbor files]# find ./ -name "*_fin.jpg" |sed -r 's#^(.*)_fin(.*)#mv & 12#g'
mv ./stu_10299_i_fin.jpg ./stu_10299_i.jpg
mv ./_fin.jpg ./.jpg
mv ./stu_102999_1_fin.jpg ./stu_102999_1.jpg
mv ./stu_102999_2_fin.jpg ./stu_102999_2.jpg
mv ./stu_102999_3_fin.jpg ./stu_102999_3.jpg
mv ./stu_102999_4_fin.jpg ./stu_102999_4.jpg
mv ./stu_102999_5_fin.jpg ./stu_102999_5.jpg
[root@harbor files]# find ./ -name "*_fin.jpg" |sed -r 's#^(.*)_fin(.*)#mv & 12#g' |bash
[root@harbor files]# ls
awkfile.txt file2.txt file.txt person.txt stu_102999_. stu_102999_2.jpg stu_102999_4.jpg stu_10299_i.jpg test.txt
count.txt file3.txt ip.txt reg.txt stu_102999_1.jpg stu_102999_3.jpg stu_102999_5.jpg stu_10299_.jpg
命令说明:
1.“1”代表前面“(^.*)”匹配内容,“&”代表“s# #”里被替换的内容,这里匹配到的是完整的文件名。
2.使用bash命令执行,bash命令执行标准输入的语句,如同我们在命令行输入语句后敲回车。
第13章
6.2.4.1 按行查询
[root@chensiqi1 ~]# sed '2p' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@chensiqi1 ~]# sed -n '2p' person.txt
102,zhangyang,CTO
命令说明:选项-n取消默认输出,只输出匹配的文本,大家只需要记住使用命令p必用选项-n。
[root@chensiqi1 ~]# sed -n '2,3p' person.txt
102,zhangyang,CTO
103,Alex,COO
命令说明:查看文件的第2行到3行,使用地址范围“2,3”。取行就用sed,最简单
[root@chensiqi1 ~]# sed -n '1~2p' person.txt
101,chensiqi,CEO
103,Alex,COO
105,feixue,CIO
命令说明:打印文件的1,3,5行。~代表步长
[root@chensiqi1 ~]# sed -n 'p' person.txt
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
命令说明:不指定地址范围,默认打印全部内容。按字符串查询
[root@harbor files]# sed -n '/CTO/p' person.txt
105,Jery,CTO
[root@harbor files]# sed -n '/CTO/,/CFO/p' person.txt
105,Jery,CTO
108,qiqi,CFF
101,qiqi1,CFO
[root@harbor files]#
6.2.4.3 混合查询
[root@chensiqi1 ~]# sed -n '2,/CFO/p' person.txt
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
命令说明:打印第2行到含CFO的行。
[root@chensiqi1 ~]# sed -n '/feixue/,2p' person.txt
105,feixue,CIO
命令说明:特殊情况,前两行没有匹配到feixue,就向后匹配,如果匹配到feixue就打印此行。所以这种混合地址不推荐使用。
6.2.4.4 过滤多个字符
[root@chensiqi1 ~]# sed -rn '/chensiqi|yy/p' person.txt
101,chensiqi,CEO
104,yy,CFO
命令说明:
使用扩展正则“|”,为了不使用转义符号“”,因此使用-r选项开启扩展正则表达式模式7,sed命令应用知识扩展
7.1 sed修改文件的同时进行备份
[root@chensiqi1 ~]# cat person.txt
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@chensiqi1 ~]# sed -i.bak 's#zhangyang#NB#g' person.txt
[root@chensiqi1 ~]# cat person.txt
101,chensiqi,CEO
102,NB,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@chensiqi1 ~]# cat person.txt.bak
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
命令行说明:
在-i参数的后边加上.bak(.任意字符),sed会对文件进行先备份后修改7.1 sed修改文件的同时进行备份
[root@chensiqi1 ~]# cat person.txt
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@chensiqi1 ~]# sed -i.bak 's#zhangyang#NB#g' person.txt
[root@chensiqi1 ~]# cat person.txt
101,chensiqi,CEO
102,NB,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@chensiqi1 ~]# cat person.txt.bak
101,chensiqi,CEO
102,zhangyang,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
命令行说明:
在-i参数的后边加上.bak(.任意字符),sed会对文件进行先备份后修改7.2 特殊符号=获取行号
[root@chensiqi1 ~]# sed '=' person.txt
1
101,chensiqi,CEO
2
102,NB,CTO
3
103,Alex,COO
4
104,yy,CFO
5
105,feixue,CIO
命令说明:使用特殊符号“=”就可以获取文件的行号,这是特殊用法,记住即可。从上面的命令结果我们也发现了一个不好的地方:行号和行不在一行。
[root@chensiqi1 ~]# sed '1,3=' person.txt
1
101,chensiqi,CEO
2
102,NB,CTO
3
103,Alex,COO
104,yy,CFO
105,feixue,CIO
命令说明:只打印1,2,3行的行号,同时打印输出文件中的内容
[root@chensiqi1 ~]# sed '/yy/=' person.txt
101,chensiqi,CEO
102,NB,CTO
103,Alex,COO
4
104,yy,CFO
105,feixue,CIO
命令说明:
只打印正则匹配行的行号,同时输出文件中的内容
[root@chensiqi1 ~]# sed -n '/yy/=' person.txt
4
命令说明:只显示行号但不显示行的内容即取消默认输出。
[root@chensiqi1 ~]# sed -n '$=' person.txt
5
命令说明:
“$”代表最后一行,因此显示最后一行的行号,变相得出文件的总行数。方法改进:
[root@chensiqi1 ~]# sed '=' person.txt | sed 'N;s#
# #'
1 101,chensiqi,CEO
2 102,NB,CTO
3 103,Alex,COO
4 104,yy,CFO
5 105,feixue,CIO
命令说明:前面sed获取文件的行号有一个缺点,我们这里使用Sed命令N来补偿这个缺点。Sed命令N读取下一行数据并附加到模式空间。7.3 sed如何取不连续的行
[root@chensiqi1 ~]# sed -n '1p;3p;5p' person.txt
101,chensiqi,CEO
103,Alex,COO
105,feixue,CIO7.4 特殊符号{}的使用
[root@chensiqi1 ~]# sed -n '2,4p;=' person.txt
1
102,NB,CTO
2
103,Alex,COO
3
104,yy,CFO
4
5
命令说明:-n去掉默认输出,2,4p,输出2到4行内容,=输出全部的行的行号
[root@chensiqi1 ~]# sed -n '2,4{p;=}' person.txt
102,NB,CTO
2
103,Alex,COO
3
104,yy,CFO
4
命令说明:
‘2,4{p;=}’代表统一输出2,4行的行号和内容