针对电商交易,设计了交易下单/支付/确认收货事务事实表, 用于统计下单/支付/确认收货的子订单数、GMV等。但仍然有很多需求, 此事务事实表很难满足,比如统计买家下单到支付的时长、买家支付到卖家发货的时长、买家从下单到确认收货的时长等。如果使用事务事实表进行统计,则逻辑复杂且性能很差。对于类似于研究事件之间时间间隔的需求,釆用累积快照事实表可以很好地解决。
累积型快照事实表的设计过程
2.1.选择业务过程
选择业务过程,在多事务事实表当中介绍了业务的流转过程,主要有四个事件,即买家下单、买家支付、卖家发货、 买家确认收货业务过程。对于这四个业务过程,在事务统计中只关注下单、支付和确认收货三个业务过程;而在统计事件时间间隔的需求中, 卖家发货也是关键环节。所以针对累积快照事实表,我们选择这四个业务过程进行讨论。
2.2.确定粒度
确定粒度,一般都是参考多事务事实表,遵循最小粒度优先原则,比如订单商品粒度。
2.3.确定维度
确定维度,拿交易的多事务事实表来讲,维度主要有买家、卖家、 店铺、商品、类目、发货地区、收货地区等。四个业务过程对应的时间字段,格式为日期+时间,分别为下单时间、支付时间、发货时间、确认收货时间等。
2.4.确定事实
确定事实,对于累积快照事实表,需要将各业务过程对应的事实均放入事实表中。比如淘宝交易累积快照事实表,包含了各业务过程对应的事实,如下单对应的下单金额,支付对应的折扣、邮费和支付金额,确认收货对应的金额等。累积快照事实表解决的最重要的问题是统计不同业务过程之间的时间间隔,建议将每个过程的时间间隔作为事实放在事实表中。
2.5.退化维度
退化维度,在大数据的事实表模型设计中,更多的是考虑提高下游用户的使用效率,降低数据获取的复杂性,减少关联的表数量。 一方面,存储成本降低了,而相比之下CPU成本仍然较高;另一方面, 在大数据时代,很多维表比事实表还大,如淘宝几十亿的商品、几亿的买家等,在分布式数据仓库系统中,事实表和维表关联的成本很高。所以在传统的维度模型设计完成之后,在物理实现中将各维度的常用属性退化到事实表中,以大大提高对事实表的过滤查询、统计聚合等操作的效率,具体详情不再赘述。
2.6.实例
累积快照事实表和事务性事实表直观上差异比较大的一点就是:累积快照事实表,多个业务过程,只存在一条记录,当业务过程发生了,只是修改这一条记录,而事务性事实表是会产生多条记录,表相对比较稀疏。

三.累积型快照事实表的特性
累积快照事实表适用于具有较明确起止时间的短生命周期的实体, 比如交易订单、物流订单等,对于实体的每一个实例,都会经历从诞生到消亡等一系列步骤。对于商品、用户等具有长生命周期的实体,一般采用周期快照事实表更合适。
累积快照事实表的典型特征是多业务过程日期,用于计算业务过程之间的时间间隔。但结合阿里巴巴数据仓库模型建设的经验,对于累积快照事实表,还有一个重要作用是保存全量数据。对于淘宝交易,需要保留历史截至当前的所有交易数据,其中一种方式是在ODS层保留和源系统结构完全相同的数据;但由于使用时需要关联维度,较为麻烦, 所以在公共明细层需要保留一份全量数据,淘宝交易累积快照事实表就承担了这样的作用——存放加工后的事实,并将各维度常用属性和订单杂项维度退化到此表中。通常用于数据探查、统计分析、数据挖掘等。
四.累积型快照事实表的特殊处理
4.1非线性过程
实际实践中,累积型快照事实表累积的业务过程不一定都是线性的,买家下单、买家支付、卖家发货、 买家确认收货这是正常的流程,也有可能存在买家手工或者第三方人员手工关闭订单,即订单关闭状态,这也意味着该几个业务过程生命周期的终结。所以应该设立一个标识,当订单交易完成或者订单关闭都算作生命周期的终结。
4.2多源过程
实际实践中,可能还存在买家退货退款,物流相关情况等,这些都是可能发现循环业务过程的情况,针对这些情况,考虑是否将售后和物流等业务过程加入,就需要考虑加入以后是否会影响粒度,还有针对不确定循环次数的业务过程,是加第一次还是最后一次,都是需要考虑具体业务情况来定的。
五.累积型快照事实表如何实现
5.1全量表的实现方式
第一种方式是全量表的形式。此全量表一般为日期分区表,每天的分区存储昨天的全量数据和当天的增量数据合并的结果,保证每条记录的状态最新。(保存历史分区,而不是只保留最新的状态,实践证明历史分区也有存在的必要性,虽然不常用。)此种方式适用于全量数据较少的情况。如果数据量很大, 此全量表数据量不断膨胀,存储了大量永远不再更新的历史数据,对 ETL和分析统计性能影响较大。可以想象一下,每天每个分区都要存储历史至今所有的数据,这个带来的存储开销是非常巨大的。
5.2全量表的改进方式(解决存储开销问题)
第二种方式是全量表的变化形式。此种方式主要针对事实表数据量很大的情况。较短生命周期的业务实体一般从产生到消亡都有一定的时间间隔,可以测算此时间间隔,或者根据商业用户的需求确定一个相对较大的时间间隔。比如针对交易订单,我们以200天作为订单从产生到消亡的最大间隔(一个用户基本上不可能200天前支付了,200天以后还没有确认收货的情况,但是实际情况往往存在那么几单异常情况)。设计最近200天的交易订单累积快照事实表,每天的分区存储最近200天的交易订单,而200天之前的订单则按照gmt_Create创建分区存储在归档表中。此方式存在的一个问题是200天的全量表根据商业需求需要保留多天的分区数据,而由于数据量较大,存储消耗较大。
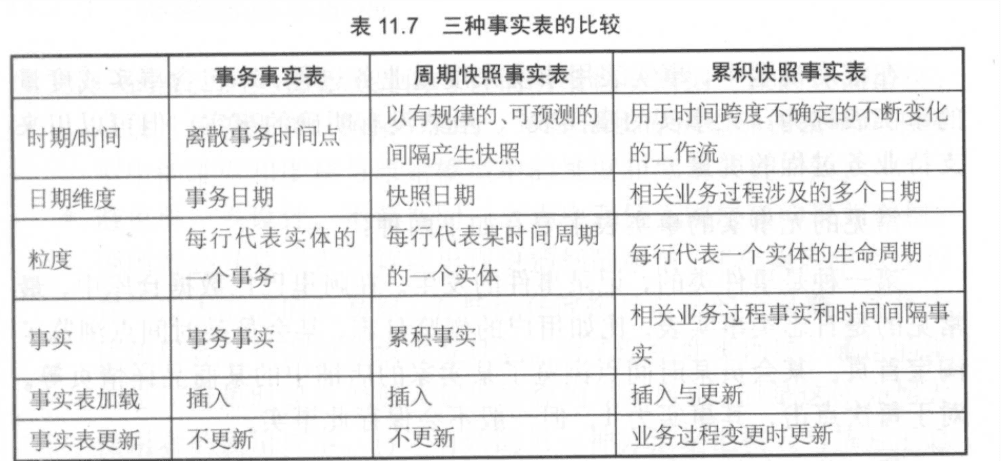
六.三种事实表的比较
6.1事务性事实表
事务事实表记录的事务层面的事实,用于跟踪业务过程的行为,并 支持几种描述行为的事实,保存的是最原子的数据,也称为“原子事实 表”。事务事实表中的数据在事务事件发生后产生,数据的粒度通常是 每个事务一条记录。一旦事务被提交,事实表数据被插入,数据就不能 更改,其更新方式为增量更新。
6.2周期型快照事实表
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实, 如余额、库存、层级、温度等,时间间隔为每天、每月、每年等,典型的例子如库存日快照表等。周期快照事实表的日期维度通常记录时间段 的终止日,记录的事实是这个时间段内一些聚集事实值或状态度量。事 实表的数据一旦插入就不能更改,其更新方式为增量更新。
6.3累积型快照事实表
累积快照事实表被用来跟踪实体的一系列业务过程的进展情况,它 通常具有多个日期字段,用于研究业务过程中的里程碑过程的时间间 隔。另外,它还会有一个用于指示最后更新日期的附加日期字段。由于事实表中许多日期在首次加载时是不知道的,而且这类事实表在数据加 载完成后,可以对其数据进行更新,来补充业务状态变更时的日期信息和事实。