数据库是所有架构中不可缺少的一环,一旦数据库出现性能问题,那对整个系统都回来带灾难性的后果。并且数据库一旦出现问题,由于数据库天生有状态(分主从)带数据(一般还不小),所以出问题之后的恢复时间一般不太可控,所以,对数据库的优化是需要我们花费很多精力去做的。接下来就给大家介绍一下微博数据库这些年的一点经验,希望可以对大家有帮助。
硬件层优化
这一层最简单,最近几年相信大家对SSD这个名词并不陌生,其超高的IOPS在刚出现在大家视野中的时候就让人惊艳了一把,而随着最近价格的不断下调,已经非常具有性价比,目前微博已经把SSD服务器作为数据库类服务的标配。
我们来看下我们早些年自己对SSD的OLTP的性能测试:

 

可以看到OLTP的qps可以达到2.7w左右,配合1m2s的架构可以支持5w的qps,在一些简单场景下,甚至可以不必配置cache层来做缓存。
ps:硬件测试最好自己进行实测,官方数据仅能作为一个参考值,因为很多时候性能要严重依赖于场景,细化到不同的SQL会得到相差很大的结论,故最好自行测试。
微博在12年的时候使用PCIE-FLASH支撑了feed系统在春晚3.5w的qps,在初期很好的支撑了业务的发展,为架构优化和改造争取了非常多的时间。
并且大家可以看到,目前很多的云厂商的物理机基本全都是SSD设备,AWS更是虚机都提供SSD盘来提供IO性能,可以预见未来IO将不会在是数据库遇到的最大瓶颈点。
经验:如果公司不差钱,最好直接投入SSD or PCIE-FLASH设备,而且投入的时间越早越好。
系统层优化
配合SSD硬件之后,系统层原有的一些设计就出现了问题,比如IO scheduler,系统默认的为CFQ,主要针对的是机械硬盘进行的优化,由于机械硬盘需要通过悬臂寻道,所以CFQ是非常适合的。
Complete Fair Queuing
该算法为每一个进程分配一个时间窗口,在该时间窗口内,允许进程发出IO请求。通过时间窗口在不同进程间的移动,保证了对于所有进程而言都有公平的发出IO请求的机会。同时CFQ也实现了进程的优先级控制,可保证高优先级进程可以获得更长的时间窗口。
但是由于SSD盘已经没有了寻道而是基于电子的擦除,所以CFQ算法已经明显的不合适了,一般情况下网上都推荐使用NOOP算法,但是我个人更推荐DEADLINE算法。我们看下这2种算法的特点。
NOOP算法只拥有一个等待队列,每当来一个新的请求,仅仅是按FIFO的思路将请求插入到等待队列的尾部,默认认为 I/O不会存在性能问题,比较节省CPU资源。
DEADLINE调度算法通过降低性能而获得更短的等待时间,它使用轮询的调度器,简洁小巧,提供了最小的读取延迟和尚佳的吞吐量,特别适合于读取较多的环境。
从算法的特点看,NOOP确实更适合SSD介质,非常的简单,但是由于数据库型服务有很多复杂查询,简单的FIFO可能会造成一些事务很难拿到资源从而一直处于等待状态,所以个人更推荐使用DEADLINE。ps:更主要的是因为对这2个算法的压测显示性能并没有太明显的区别。
以下是我们自己在线上业务调整之后的效果:
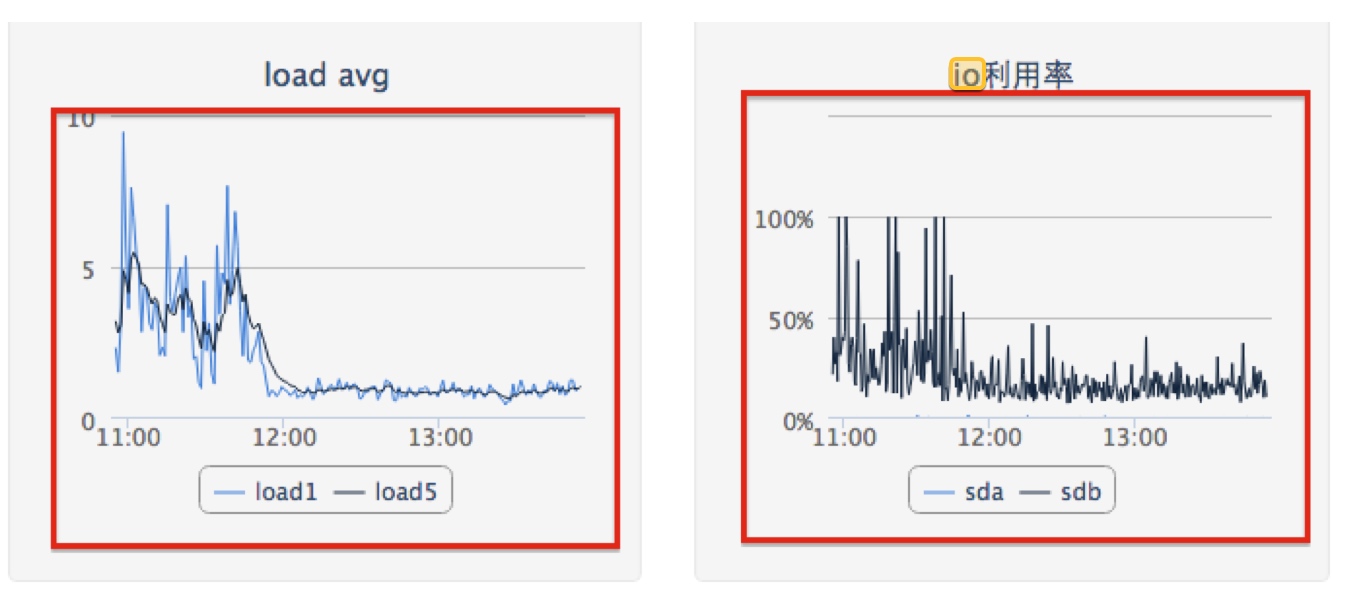
 

除了以上这点之外,还有一些小地方也许要调整,虽然收益不会看上去这么明显,但是聚沙成塔,积少成多,还是非常值得优化的。
- 使用EXT4 or XFS
- 在mount的时候加上 noatime属性
- raid卡的读写策略改为write back
- 使用jemalloc替换现有的Glibc
经验:重点放在针对IO的优化上,数据库尤其是MySQL是IO密集型服务,解决IO的问题会减少不必要的问题。
MySQL自身的优化
我们先说说有那些参数可以带来性能的改变
- innodb_max_dirty_pages_pct
争议比较大,一般来说都是在75-90之间,主要控制BP中的脏数据刷盘的时机,如果太小会频繁刷盘造成IO上升,如果太大会导致MySQL正常关闭的时候需要很长的时间才能normal shutdown,具体需要看实际场景,个人推荐90
- innodb_io_capacity
磁盘IO吞吐,具体为缓冲区落地的时候,可以刷脏页的数量,默认200,由于使用了SSD硬盘,所以推荐设置到3000-5000
- innodb_read_io_threads
- innodb_write_io_threads
增加后台处理线程的数目,默认为4,推荐改成8
- sync_binlog
- innodb_flush_log_at_trx_commit
著名的双1参数,对性能影响非常的大
sync_binlog控制刷binlog的策略,MySQL在每写N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
innodb_flush_log_at_trx_commit控制log buffer刷log file的策略,设置为0的时候每秒刷新一次,设置为1的时候每次commit都会刷新。
从上述描述就可以看出如果追求数据的安全性,那么设置双一是最安全的,如果追求性能最大化,那么双0最合适,这中间可以相差至少2倍的性能。
- innodb_log_file_size
innodb redo log的size大小,5.5最大4G,5.6最大256G,这个越大可以提升写的性能,大部分时候不需要等待checkpoint覆盖就可以一直write。
- query_cache_type
看上去很美的东西,但是在实际生产环境中,多次给我们带来了故障,由于每次表的更新都会清空buffer,并且对于sql的匹配是逐个字符效验实际效果很长,大部分时间并没有得到cache的效果,反而得到了很多wait for query cache lock。建议关闭。
以上,仅针对MySQL 5.5,目前我们还在摸索5.6和5.7由于还没有大规模线上使用,所以还谈不上有什么经验。
经验:如果有人力可以投入,可以学习BAT针对数据库进行二次开发,通过path的方式获得更高的性能和稳定性。如果没有人力,只要深入了解MySQL自身参数的影响也可以满足业务的需求,不用一味的追源码级别的开发改造。
业务优化
所谓的业务优化其实说白了很多时候就是index的优化,我们DBA常说一条慢SQL就能将上面所有的优化都付之一炬,CPU直接打满,RT全都都飙升到500ms甚至1s以上。
优化慢查有三宝:
- pt-query-digest
- explain
- show profiling
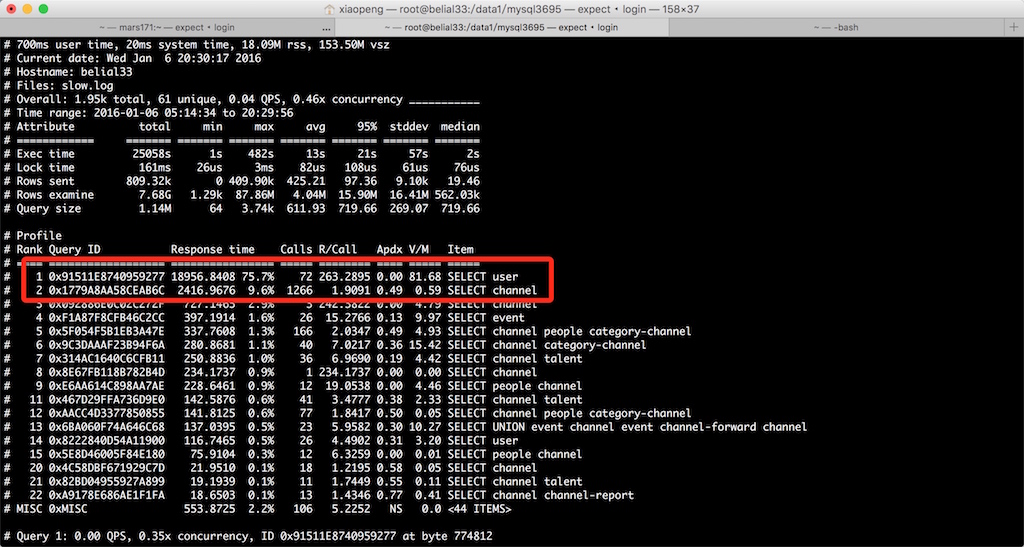
首先,使用pt-query-digest可以定位到定位影响最中的慢查是哪条。
 
然后通过explain具体分析慢查晓的问题所在
 
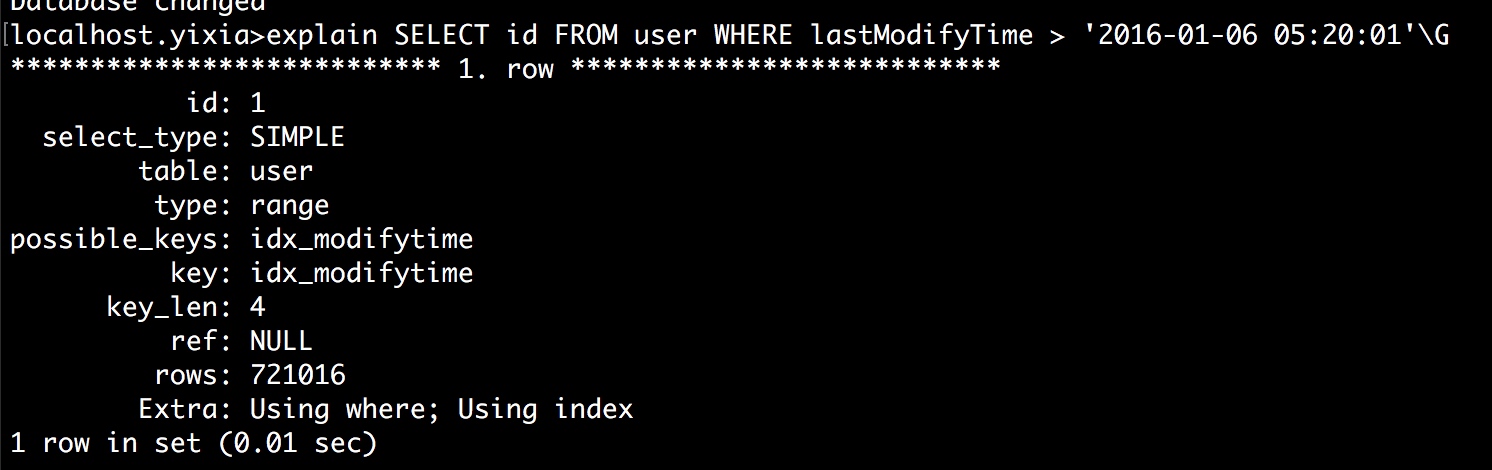
重点查看type,rows和extra这三个字段。
其中type的顺序如下:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
最后,如果问题还是比较严重,可以通过show profiling来定位一下到底是那个环节出现的问题。
 
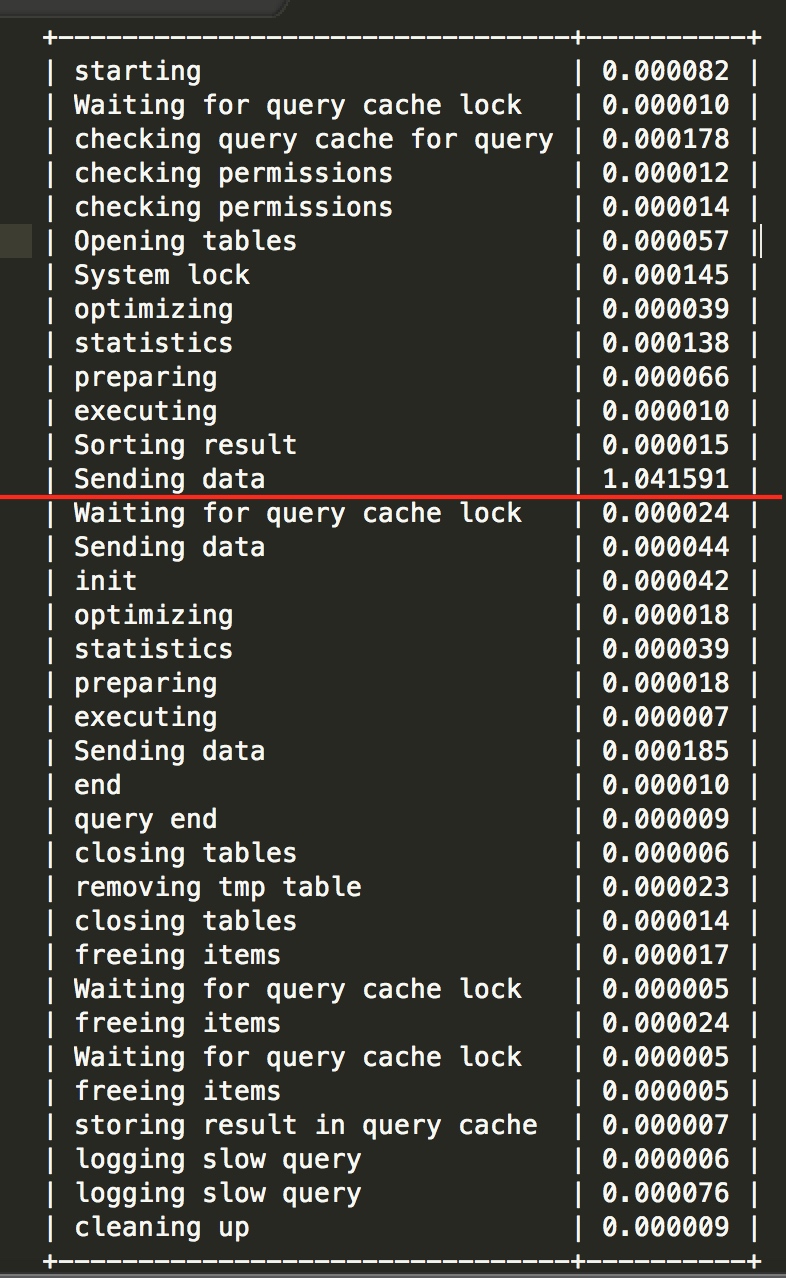
可以看到sending data最消耗时间,这时候就需要找到底为什么在sending上消耗了这么多的时间,是结果集太大,还是io性能不够了,诸如此类
以下就是一个复杂语句的优化结果,可以从rows那里明显的看出减少了很多查询的开销。

 

经验:最好建立慢查询监控系统,每天都花时间在慢查的优化上,避免一条SQL引发的血案之类的事情发生。
架构优化
最后,也就是终极手段了,那就是架构优化,其实很多时候,当我们将上面几个方向都做了之后发现还没有很好的效果,那就必须找开发同学一起聊一下了。ps:当然找PM同学聊一下人生会更有效果。
记得有一次,我们找开发聊了一下,最后开发决定将这个功能改掉,这个时候你会突然发现无论什么优化手段都比不上「不做」这个优化手段,简直无敌了。
根据我个人的经验来说架构层的优化有如下几个普适原则:
- cache为王
热点数据必须使用Redis或者mc之类的cache抗量,让MySQL抗流量是不明智的。
- 使用队列消峰
众所周知MySQL的异步同步机制是单线程的,所有主库上的并发到从库上都是通过io-thread来慢慢做的,即使主库写入速度再快,从库延迟了,整个集群还是不可用,所以最好采用队列来进行一定的写入消峰,使写入维持在一个较为均衡的水平。
- 适度的过度设计
很多产品最开始的时候比较小,但是有可能上线之后广受好评一下用活跃度就上来了,这个时候如果数据库出现瓶颈需要拆分需要开发、DBA、架构师等等一起配合来做,而且很有可能没有时间。所以在产品初期进行一定的过度设计会为未来这种情况打好铺垫。最明显的就是拆库拆表,最好在一开始就对业务进行适度的垂直拆分和比较过度的水平拆分,以便应对业务的高速增长。
举一个栗子:
 

- 通过mcq降低对MySQL的写入性能的要求。
- 通过mc和Redis来承担用户的实际访问,90%的量依靠cache层承载和屏蔽。
- MySQL作为最终的数据落地,存储全量的数据,但是仅支撑部分业务查询,小于10%。
经验:让合适的软件做适合的事情,不要光从技术层面思考优化方案,也要从需求方面去分解。
总结中的总结
转一篇很经典的数据库优化漏斗法则,很多年前就看到过,现在再看依然觉得适用,大家共勉。
 
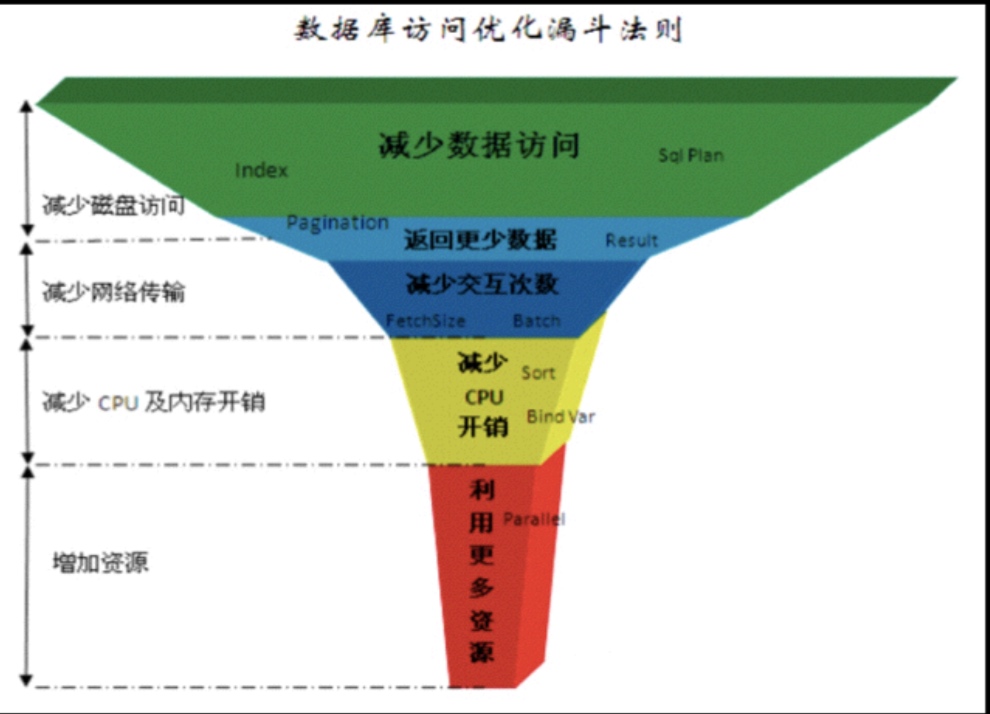
唯一不适用的就是最下的增加资源,SSD真是个好东西,谁用谁知道。