SRE的职责划分却不尽相同,那么SRE究竟在做什么?
SRE的职责
SRE主要负责Google所有核心业务系统的可用性、性能、容量相关的事情,根据《Site Reliability Engineering 》一书提及的内容,笔者做简单汇总,Google SRE的工作主要包括但不限于如下:
- 基础设施容量规划
- 生产系统的监控
- 生产系统的负载均衡
- 发布与变更工程管理
- on-call(轮值) 与 Firefighting(紧急故障救火)
- 与业务团队协作,共同完成疑难问题的处理
- ...
在 Google SRE 书中,对 SRE 日常工作状态有个准确的描述:至多 50% 的时间精力处理操作相关事宜,50% 以上的精力通过软件工程保障基础设施的稳定性和可扩展性。
而在国内,非常多的SRE部门与传统运维部门职责类似,本质来说负责的是互联网服务背后的技术运维工作。区别于传统的运维SRE,如何在业务研发团队落地SRE,我们做了一年多的探索与实践,笔者认为业务团队SRE的核心是:以软件工程的方法论重新定义研发运维,驱动并赋能业务演进。
阿里数据库稳定性治理
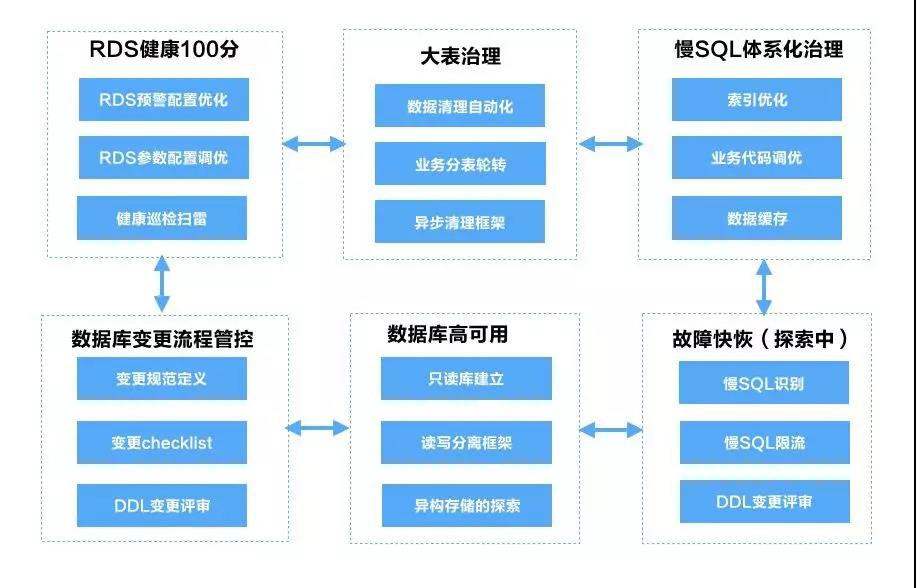
数据库是应用的核心命脉,对于ECS管控来说,所有的核心业务全部跑在RDS之上,如果数据库发生故障,对应用的损害无论从管控面或者数据面都是致命的。所以,SRE做的第一件事情就是守住核心命脉,对 数据库稳定性进行全面的治理。
首先,我们先来看一下ECS管控在规模化业务下,数据库面临的问题:
- 空间增长过快,无法支撑业务近期发展需求。
- 慢SQL频发,严重影响应用稳定性。
- 数据库变更故障率高,DDL大表变更引起的故障占比高。
- RDS性能指标异常,数据库各种性能指标异常。
- RDS报警配置混乱,报警信息存在遗漏,误报的情况。
对于数据库的问题我们的策略是数据库+业务两手抓,单纯优化数据库或者业务调优效果都不是最佳的。比如典型的数据库大表问题,占用空间大,查询慢,如果单纯从数据库层面进行空间扩容,索引优化可以解决短期问题,当业务规模足够大的时候,数据库优化一定会面临瓶颈,这个时候需要业务调优双管齐下。
容量规模、极致性能、高可用性等
下面简单介绍一下优化思路:
- 数据库占用空间大问题,两个思路,降低当前数据库占用空间,同时控制数据空间增长。我们通过归档历史数据释放数据空洞来达到数据页复用,从而控制数据库磁盘空间增长;但是delete数据并不会释放表空间,为了释放已经占用大量空间的大表,我们业务上进行了改造,通过生产中间表轮转来解决。
- 慢SQL频发问题,数据库优化与业务改造两手抓。数据库层面通过索引优化来提高查询效率,同时减少无效数据来减少扫描行数;应用层面通过缓存降低数据库读次数、优化业务代码等方式减少与规避慢SQL。
- 数据库变更故障率高问题,管控流程增强,增加Review流程。DDL变更类型多,由于开发人员对数据库的专业性与敏感度不够导致数据库引发变更增多,对于这类情况,我们针对DDL变更增加了 检查项列表与评审流程,控制数据库变更风险。
- 数据库性能指标与配置问题,以项目方式推进数据库健康度提升,统一管控数据库预警配置。
- 慢SQL限流与快恢的探索。慢SQL严重情况会导致RDS整体不可用,当前我们正在探索如何通过自动/半自动化的方式限流慢SQL来保障数据库稳定性。
下图是ECS在数据库稳定性治理上的几个探索。
2)监控预警治理