Java 8 API 示例:字符串、数值、算术和文件
译者:飞龙
大量的教程和文章都涉及到Java8中最重要的改变,例如lambda表达式和函数式数据流。但是此外许多现存的类在JDK 8 API中也有所改进,带有一些实用的特性和方法。
这篇教程涉及到Java 8 API中的那些小修改 -- 每个都使用简单易懂的代码示例来描述。让我们好好看一看字符串、数值、算术和文件。
处理字符串
两个新的方法可在字符串类上使用:join和chars。第一个方法使用指定的分隔符,将任何数量的字符串连接为一个字符串。
String.join(":", "foobar", "foo", "bar");
// => foobar:foo:bar
第二个方法chars从字符串所有字符创建数据流,所以你可以在这些字符上使用流式操作。
"foobar:foo:bar"
.chars()
.distinct()
.mapToObj(c -> String.valueOf((char)c))
.sorted()
.collect(Collectors.joining());
// => :abfor
不仅仅是字符串,正则表达式模式串也能受益于数据流。我们可以分割任何模式串,并创建数据流来处理它们,而不是将字符串分割为单个字符的数据流,像下面这样:
Pattern.compile(":")
.splitAsStream("foobar:foo:bar")
.filter(s -> s.contains("bar"))
.sorted()
.collect(Collectors.joining(":"));
// => bar:foobar
此外,正则模式串可以转换为谓词。这些谓词可以像下面那样用于过滤字符串流:
Pattern pattern = Pattern.compile(".*@gmail\.com");
Stream.of("bob@gmail.com", "alice@hotmail.com")
.filter(pattern.asPredicate())
.count();
// => 1
上面的模式串接受任何以@gmail.com结尾的字符串,并且之后用作Java8的Predicate来过滤电子邮件地址流。
处理数值
Java8添加了对无符号数的额外支持。Java中的数值总是有符号的,例如,让我们来观察Integer:
int可表示最多2 ** 32个数。Java中的数值默认为有符号的,所以最后一个二进制数字表示符号(0为正数,1为负数)。所以从十进制的0开始,最大的有符号正整数为2 ** 31 - 1。
你可以通过Integer.MAX_VALUE来访问它:
System.out.println(Integer.MAX_VALUE); // 2147483647
System.out.println(Integer.MAX_VALUE + 1); // -2147483648
Java8添加了解析无符号整数的支持,让我们看看它如何工作:
long maxUnsignedInt = (1l << 32) - 1;
String string = String.valueOf(maxUnsignedInt);
int unsignedInt = Integer.parseUnsignedInt(string, 10);
String string2 = Integer.toUnsignedString(unsignedInt, 10);
就像你看到的那样,现在可以将最大的无符号数2 ** 32 - 1解析为整数。而且你也可以将这个数值转换回无符号数的字符串表示。
这在之前不可能使用parseInt完成,就像这个例子展示的那样:
try {
Integer.parseInt(string, 10);
}
catch (NumberFormatException e) {
System.err.println("could not parse signed int of " + maxUnsignedInt);
}
这个数值不可解析为有符号整数,因为它超出了最大范围2 ** 31 - 1。
算术运算
Math工具类新增了一些方法来处理数值溢出。这是什么意思呢?我们已经看到了所有数值类型都有最大值。所以当算术运算的结果不能被它的大小装下时,会发生什么呢?
System.out.println(Integer.MAX_VALUE); // 2147483647
System.out.println(Integer.MAX_VALUE + 1); // -2147483648
就像你看到的那样,发生了整数溢出,这通常是我们不愿意看到的。
Java8添加了严格数学运算的支持来解决这个问题。Math扩展了一些方法,它们全部以exact结尾,例如addExact。当运算结果不能被数值类型装下时,这些方法通过抛出ArithmeticException异常来合理地处理溢出。
try {
Math.addExact(Integer.MAX_VALUE, 1);
}
catch (ArithmeticException e) {
System.err.println(e.getMessage());
// => integer overflow
}
当尝试通过toIntExact将长整数转换为整数时,可能会抛出同样的异常:
try {
Math.toIntExact(Long.MAX_VALUE);
}
catch (ArithmeticException e) {
System.err.println(e.getMessage());
// => integer overflow
}
处理文件
Files工具类首次在Java7中引入,作为NIO的一部分。JDK8 API添加了一些额外的方法,它们可以将文件用于函数式数据流。让我们深入探索一些代码示例。
列出文件
Files.list方法将指定目录的所有路径转换为数据流,便于我们在文件系统的内容上使用类似filter和sorted的流操作。
try (Stream<Path> stream = Files.list(Paths.get(""))) {
String joined = stream
.map(String::valueOf)
.filter(path -> !path.startsWith("."))
.sorted()
.collect(Collectors.joining("; "));
System.out.println("List: " + joined);
}
上面的例子列出了当前工作目录的所有文件,之后将每个路径都映射为它的字符串表示。之后结果被过滤、排序,最后连接为一个字符串。如果你还不熟悉函数式数据流,你应该阅读我的Java8数据流教程。
你可能已经注意到,数据流的创建包装在try-with语句中。数据流实现了AutoCloseable,并且这里我们需要显式关闭数据流,因为它基于IO操作。
返回的数据流是
DirectoryStream的封装。如果需要及时处理文件资源,就应该使用try-with结构来确保在流式操作完成后,数据流的close方法被调用。
查找文件
下面的例子演示了如何查找在目录及其子目录下的文件:
Path start = Paths.get("");
int maxDepth = 5;
try (Stream<Path> stream = Files.find(start, maxDepth, (path, attr) ->
String.valueOf(path).endsWith(".js"))) {
String joined = stream
.sorted()
.map(String::valueOf)
.collect(Collectors.joining("; "));
System.out.println("Found: " + joined);
}
find方法接受三个参数:目录路径start是起始点,maxDepth定义了最大搜索深度。第三个参数是一个匹配谓词,定义了搜索的逻辑。上面的例子中,我们搜索了所有JavaScirpt文件(以.js结尾的文件名)。
我们可以使用Files.walk方法来完成相同的行为。这个方法会遍历每个文件,而不需要传递搜索谓词。
Path start = Paths.get("");
int maxDepth = 5;
try (Stream<Path> stream = Files.walk(start, maxDepth)) {
String joined = stream
.map(String::valueOf)
.filter(path -> path.endsWith(".js"))
.sorted()
.collect(Collectors.joining("; "));
System.out.println("walk(): " + joined);
}
这个例子中,我们使用了流式操作filter来完成和上个例子相同的行为。
读写文件
将文本文件读到内存,以及向文本文件写入字符串在Java 8 中是简单的任务。不需要再去摆弄读写器了。Files.readAllLines从指定的文件把所有行读进字符串列表中。你可以简单地修改这个列表,并且将它通过Files.write写到另一个文件中:
List<String> lines = Files.readAllLines(Paths.get("res/nashorn1.js"));
lines.add("print('foobar');");
Files.write(Paths.get("res/nashorn1-modified.js"), lines);
要注意这些方法对内存并不十分高效,因为整个文件都会读进内存。文件越大,所用的堆区也就越大。
你可以使用Files.lines方法来作为内存高效的替代。这个方法读取每一行,并使用函数式数据流来对其流式处理,而不是一次性把所有行都读进内存。
try (Stream<String> stream = Files.lines(Paths.get("res/nashorn1.js"))) {
stream
.filter(line -> line.contains("print"))
.map(String::trim)
.forEach(System.out::println);
}
如果你需要更多的精细控制,你需要构造一个新的BufferedReader来代替:
Path path = Paths.get("res/nashorn1.js");
try (BufferedReader reader = Files.newBufferedReader(path)) {
System.out.println(reader.readLine());
}
或者,你需要写入文件时,简单地构造一个BufferedWriter来代替:
Path path = Paths.get("res/output.js");
try (BufferedWriter writer = Files.newBufferedWriter(path)) {
writer.write("print('Hello World');");
}
BufferedReader也可以访问函数式数据流。lines方法在它所有行上面构建数据流:
Path path = Paths.get("res/nashorn1.js");
try (BufferedReader reader = Files.newBufferedReader(path)) {
long countPrints = reader
.lines()
.filter(line -> line.contains("print"))
.count();
System.out.println(countPrints);
}
目前为止你可以看到Java8提供了三个简单的方法来读取文本文件的每一行,使文件处理更加便捷。
不幸的是你需要显式使用try-with语句来关闭文件流,这会使示例代码有些凌乱。我期待函数式数据流可以在调用类似count和collect时可以自动关闭,因为你不能在相同数据流上调用终止操作两次。
在 Java 8 中避免 Null 检查
译者:ostatsu
如何预防 Java 中著名的 NullPointerException 异常?这是每个 Java 初学者迟早会问到的关键问题之一。而且中级和高级程序员也在时时刻刻规避这个错误。其是迄今为止 Java 以及很多其他编程语言中最流行的一种错误。
Null 引用的发明者 Tony Hoare 在 2009 年道歉,并称这种错误为他的十亿美元错误。
我将其称之为自己的十亿美元错误。它的发明是在1965 年,那时我用一个面向对象语言(ALGOL W)设计了第一个全面的引用类型系统。我的目的是确保所有引用的使用都是绝对安全的,编译器会自动进行检查。但是我未能抵御住诱惑,加入了 Null 引用,仅仅是因为实现起来非常容易。它导致了数不清的错误、漏洞和系统崩溃,可能在之后 40 年中造成了十亿美元的损失。
无论如何,我们必须要面对它。所以,我们到底能做些什么来防止 NullPointerException 异常呢?那么,答案显然是对其添加 null 检查。由于 null 检查还是挺麻烦和痛苦的,很多语言为了处理 null 检查添加了特殊的语法,即空合并运算符 —— 其在像 Groovy 或 Kotlin 这样的语言中也被称为 Elvis 运算符。
不幸的是 Java 没有提供这样的语法糖。但幸运的是这在 Java 8 中得到了改善。这篇文章介绍了如何利用像 lambda 表达式这样的 Java 8 新特性来防止编写不必要的 null 检查的几个技巧。
我已经在另一篇文章中说明了我们可以如何利用 Java 8 的 Optional 类型来预防 null 检查。下面是那篇文章中的示例代码。
假设我们有一个像这样的类层次结构:
class Outer {
Nested nested;
Nested getNested() {
return nested;
}
}
class Nested {
Inner inner;
Inner getInner() {
return inner;
}
}
class Inner {
String foo;
String getFoo() {
return foo;
}
}
解决这种结构的深层嵌套路径是有点麻烦的。我们必须编写一堆 null 检查来确保不会导致一个 NullPointerException:
Outer outer = new Outer();
if (outer != null && outer.nested != null && outer.nested.inner != null) {
System.out.println(outer.nested.inner.foo);
}
我们可以通过利用 Java 8 的 Optional 类型来摆脱所有这些 null 检查。map 方法接收一个 Function 类型的 lambda 表达式,并自动将每个 function 的结果包装成一个 Optional 对象。这使我们能够在一行中进行多个 map 操作。Null 检查是在底层自动处理的。
Optional.of(new Outer())
.map(Outer::getNested)
.map(Nested::getInner)
.map(Inner::getFoo)
.ifPresent(System.out::println);
还有一种实现相同作用的方式就是通过利用一个 supplier 函数来解决嵌套路径的问题:
Outer obj = new Outer();
resolve(() -> obj.getNested().getInner().getFoo());
.ifPresent(System.out::println);
调用 obj.getNested().getInner().getFoo()) 可能会抛出一个 NullPointerException 异常。在这种情况下,该异常将会被捕获,而该方法会返回 Optional.empty()。
public static <T> Optional<T> resolve(Supplier<T> resolver) {
try {
T result = resolver.get();
return Optional.ofNullable(result);
}
catch (NullPointerException e) {
return Optional.empty();
}
}
除了lambda,最实用的特性是新的数据流API。集合操作在任何我见过的代码库中都随处可见。而且对于那些集合操作,数据流是提升代码可读性的好方法。
但是一件关于数据流的事情十分令我困扰:数据流只提供了几个终止操作,例如reduce和findFirst属于直接操作,其它的只能通过collect来访问。工具类Collctors提供了一些便利的收集器,例如toList、toSet、joining和groupingBy。
例如,下面的代码对一个字符串集合进行过滤,并创建新的列表:
stringCollection
.stream()
.filter(e -> e.startsWith("a"))
.collect(Collectors.toList());
在迁移了300k行代码到数据流之后,我可以说,toList、toSet、和groupingBy是你的项目中最常用的终止操作。所以我不能理解为什么不把这些方法直接集成到Stream接口上面,这样你就可以直接编写:
stringCollection
.stream()
.filter(e -> e.startsWith("a"))
.toList();
这在开始看起来是个小缺陷,但是如果你需要一遍又一遍地编写这些代码,它会非常烦人。
有toArray()方法但是没有toList(),所以我真心希望一些便利的收集器可以在Java9中这样添加到Stream接口中。是吧,Brian?ಠ_ಠ
注:Stream.js是浏览器上的Java 8 数据流API的JavaScript接口,并解决了上述问题。所有重要的终止操作都可以直接在流上访问,十分方便。详情请见API文档。
无论如何,IntelliJ IDEA声称它是最智能的Java IDE。所以让我们看看如何使用IDEA来解决这一问题。
使用 IntelliJ IDEA 来帮忙
IntelliJ IDEA自带了一个便利的特性,叫做实时模板(Live Template)。如果你还不知道它是什么:实时模板是一些常用代码段的快捷方式。例如,你键入sout并按下TAB键,IDEA就会插入代码段System.out.println()。更多信息请见这里。
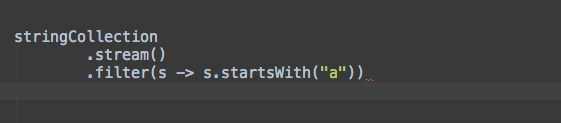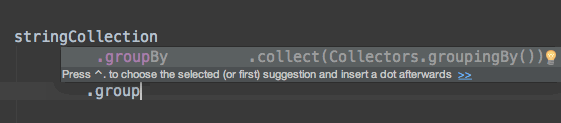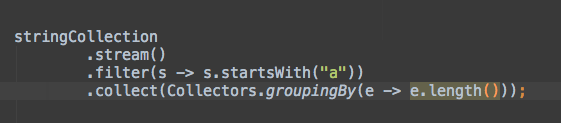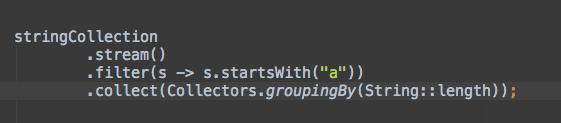
如何用实时模板来解决上述问题?实际上我们只需要为所有普遍使用的默认数据流收集器创建我们自己的实时模板。例如,我们可以创建.toList缩写的实时模板,来自动插入适当的收集器.collect(Collectors.toList())。
下面是它在实际工作中的样子:
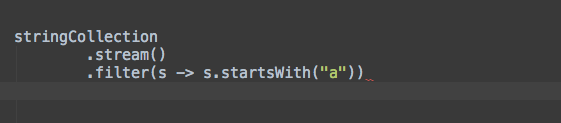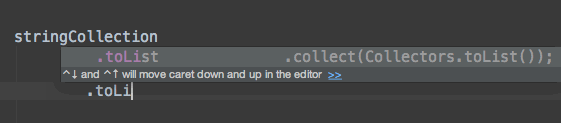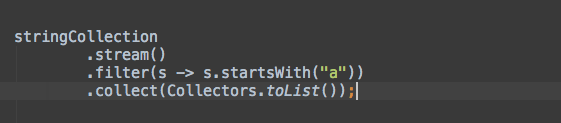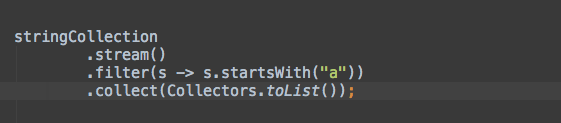
构建你自己的实时模板
让我们看看如何自己构建它。首先访问设置(Settings)并在左侧的菜单中选择实时模板。你也可以使用对话框左上角的便利的输入过滤。
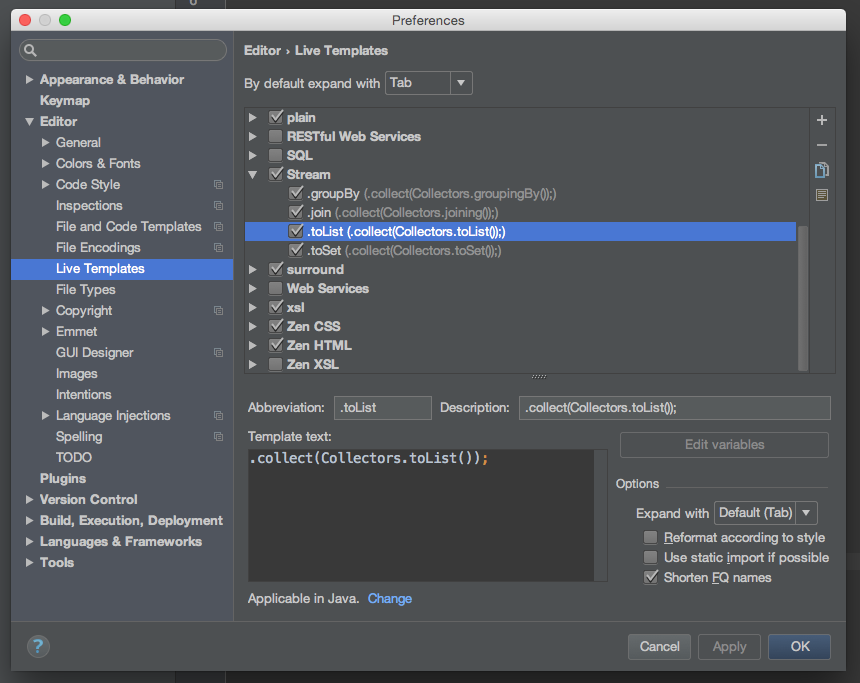
下面我们可以通过右侧的+图标创建一个新的组,叫做Stream。接下来我们向组中添加所有数据流相关的实时模板。我经常使用默认的收集器toList、toSet、groupingBy 和 join,所以我为每个这些方法都创建了新的实时模板。
这一步非常重要。在添加新的实时模板之后,你需要在对话框底部指定合适的上下文。你需要选择Java → Other,然后定义缩写、描述和实际的模板代码。
// Abbreviation: .toList
.collect(Collectors.toList())
// Abbreviation: .toSet
.collect(Collectors.toSet())
// Abbreviation: .join
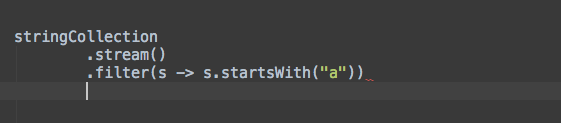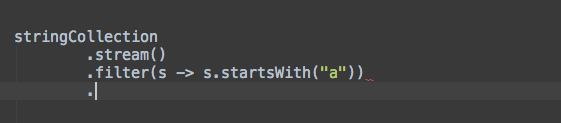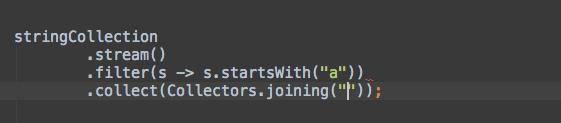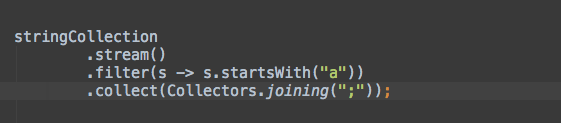
.collect(Collectors.joining("$END$"))
// Abbreviation: .groupBy
.collect(Collectors.groupingBy(e -> $END$))
特殊的变量$END$指定在使用模板之后的光标位置,所以你可以直接在这个位置上打字,例如,定义连接分隔符。
提示:你应该开启"Add unambiguous imports on the fly"(自动添加明确的导入)选项,便于让IDEA自动添加
java.util.stream.Collectors的导入语句。选项在Editor → General → Auto Import中。
让我们在实际工作中看看这两个模板:
连接
分组
请记住,这两个解决方案可能没有传统 null 检查那么高的性能。不过在大多数情况下不会有太大问题。
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥
感谢阿贝云提供的免费云服务器和免费虚拟主机,1C1G5M配置,安装的centos7,运行十分流畅,毫无延迟,
可以学习linux系统,yum之类,也可以把自己本地服搭配内网穿透给别人访问,真香,看视频听歌曲无压力,可以发布文件到服务给朋友随时下载*
运行起来也相当流畅,网速个人使用是真的赞,特别是延迟,通过域名可以很快查找,响应速度也特别快,存储空间也是相当可以,作为自己云盘也是无压力的
还可以搭建一些开源的采集站,自己看视频,美滋滋,分享给好友,发布出去都可以,总之很方便
满足了基本使用,搭建一些web服务,文件云盘属于自己的博客都是极好的,欢迎大家使用
¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥¥