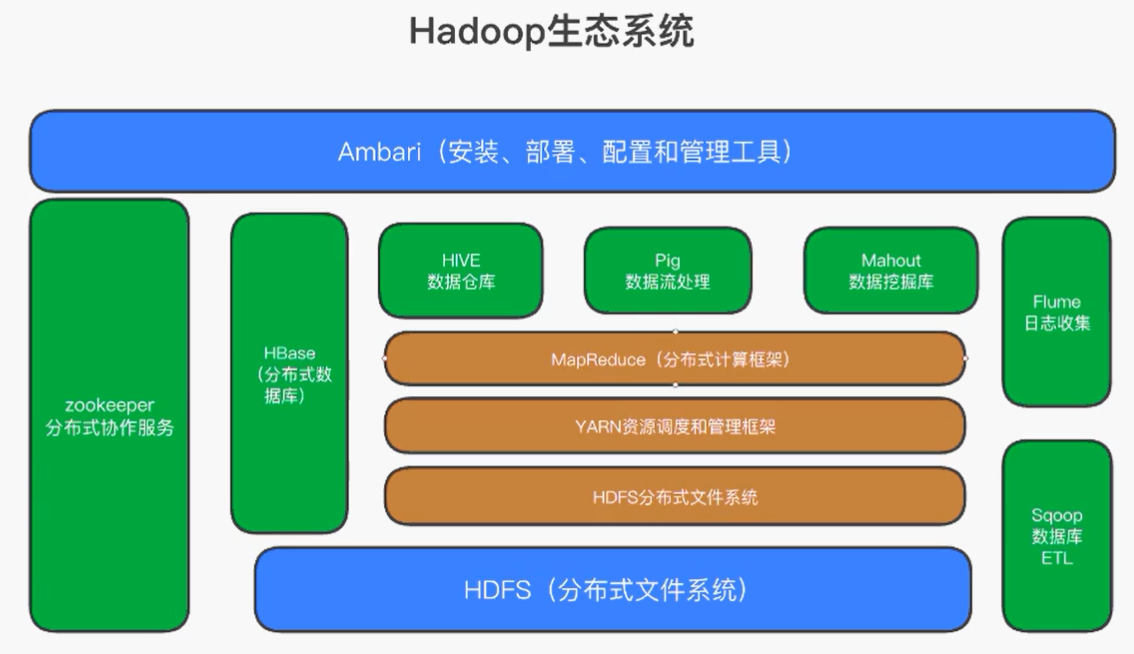
HDFS集群:
NameNode:整个HDFS集群的管理者,不存储文件数据,只记录文件“元数据” 信息
DataNode:用来存储数据的节点
Block:数据块,由NameNode对数据文件进行切分的最小单元(Hadoop 2.x和1.x中默认128M,Hadoop 3.x中默认为64M)
Replica:副本,HDFS为了保证数据的高可用,默认会对一个数据块进行三次备份
hadoop的解压缩目录结构
bin: 可执行的二进制脚本文件
etc/hadoop: hadoop系统配置文件所在目录 hadoop-env.sh配置环境 core-site.xml 配置HDFS集群核心配置(实际就是配置NameNode) hdfs-site.xml 对hdfs文件系统做配置(针对DataNode)
sbin:可执行二进制脚本文件
share:hadoop的文档和运行的核心包
配置hadoop环境
1.添加环境变量

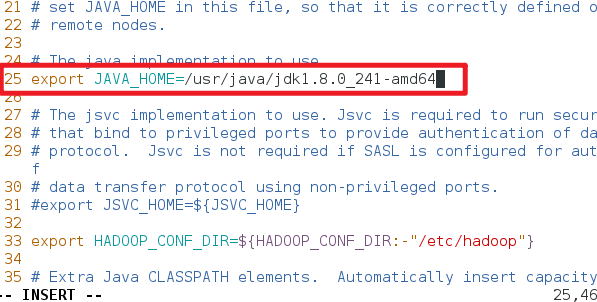
2.修改etc/hadoop-env.sh文件,将java_home路径修改为绝对路径
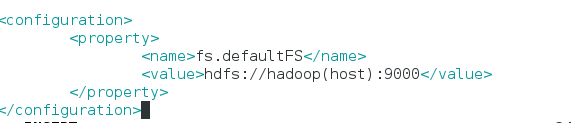
3.配置core-site.xml,配置NameNode的全局入口
4.配置hdfs-site.xml,用来对hdfs文件系统做相关配置

5.配置slaves,用来决定哪些机器为DataNode节点
6.格式化NameNode,格式化成Hadoop可以识别hdfs文件系统(只需格式化一次)