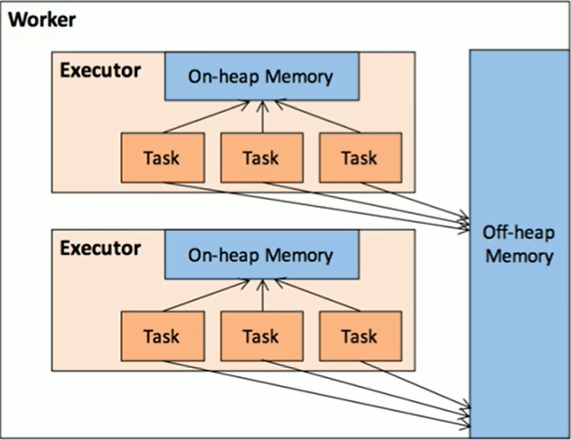
作为一个JVM进程,EXecutor的内存管理建立在JVM的内存管理之上,Spark对JVM的对内空间进行了更为详细的分配,以充分利用内存。同时,Spark引入了堆外内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化内存的使用。
堆内内存收到JVM统一管理,堆外内存是直接向操作系统进行内存的申请和释放。
1.堆内内存
由Spark程序启动时的-executor-memory或者spark.executor.memory参数配置。
Executor内运行的并发任务在缓存RDD数据和广播数据时占用的内存被规划为存储内存,在执行Shuffle时占用的的内存被规范为执行内存,剩余部分不做特殊规划,spark内部的对象实例,或者自定义的Spark应用程序中的对象实例,均占用剩余的空间。
Spark并不能控制堆内内存的使用,只能记录。堆内内存由JVM管控,所以Spark标记为释放的对象实例,很有可能在实际并没有被JVM回收,导致实际可以用的内存小于Spark记录的可用内存。古不能全避免OOM。
2.堆外内存
为了进一步优化内存的使用提高Shuffle时排序的效率,spark引入堆外内存,存储经过序列化的二进制数据。利用JDK Unsafe API,Spark可以直接操作系统堆外内存,减少不必要的内存开销。
3.内存管理
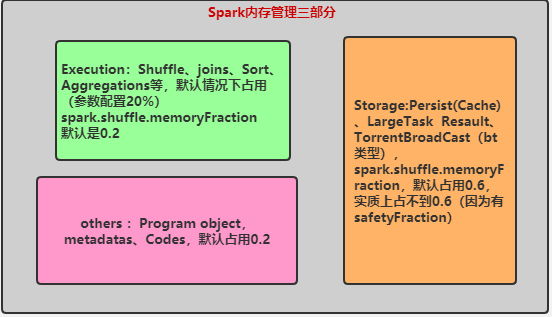
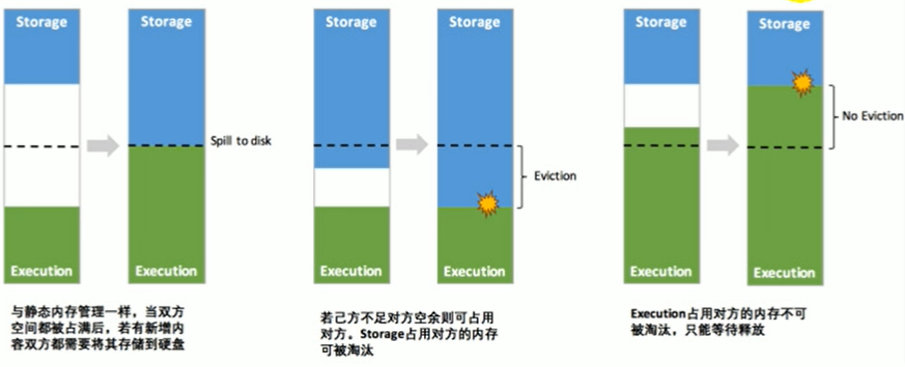
对于堆内内存,在Spark1.6之前使用的是静态内存管理,每个内存区域都分配固定空间,互相不可逾越,存储内存60%,运行内存20%,其他内存20%,并且都要预留内存,防止OOM。1.6之后使用的是统一管理,存储内存和执行内存共享一块内存空间(60%),可以动态使用对方的空闲区域。堆外内存,不用预留空间(内存空间由Spark管理,可以不用担心OOM),但是老版本存储内存和执行内存也是写死的,新版本才变为动态管理。不管是堆内还是堆内内存,当存储内存占用了运行内存时,shuffle操作需要更多内存时,被占用的内存会被强制收回,溢出的存储内存的东西或写出磁盘或丢弃,要看缓存级别。反之,当执行内存需要更多空间时,此时存储内存只能等待对方释放。
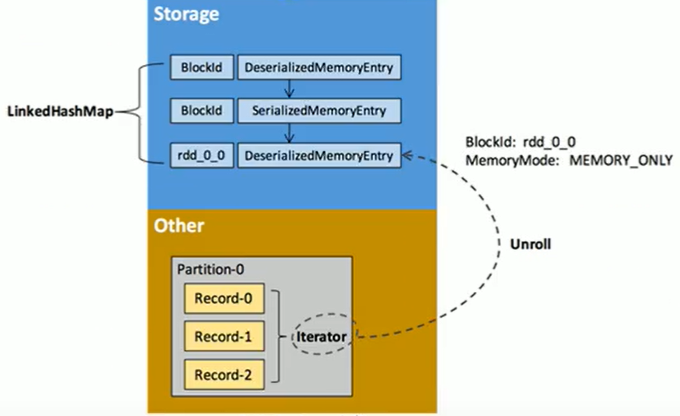
4.RDD缓存过程
避免产生内存碎片,以unroll方式进行,缓存到存储内存后,以block形式存储。