前段时间跟着斯坦福大学的机器学习网络公开课进行学习。网站地址:https://www.coursera.org,授课老师是 吴恩达,英文名 Andrew Ng。
课程非常好,并且涵盖了非常大的信息量。课后上完后,发现很有必要把一些这用的东西记下来。于是决定动手把之前学习的课程全整理一遍。
首先了解下机器学习的相关背景知识
什么是机器学习
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
当今机器学习应用在哪些领域
无人驾驶,医疗,人工智能,图像识别 和自然语言处理等方面。相信几年之后,无人汽车应用在人们实际生活中能成为现实。
机器学习分 Supervised Learning 监督学习 和 Unsupervised Learning 无监督学习
监督学习
在监督学习中,我们给出了一个数据集,已经知道我们的正确的输出应该是什么样子,有一个关于输入和输出之间的关系的想法。
监督学习问题分为“回归”和“分类”的问题。
在一个回归的问题,我们试图预测结果在一个连续的输出,这意味着我们正试图将输入变量映射到一些连续函数。
在一个分类问题,我们不是试图预测结果在一个离散输出。换句话说,我们正试图将输入变量映射到离散的类别。
例子:
给定房屋的面积,试图预测他们的价格。价格大小的函数是一个连续的输出,这是一个回归的问题。
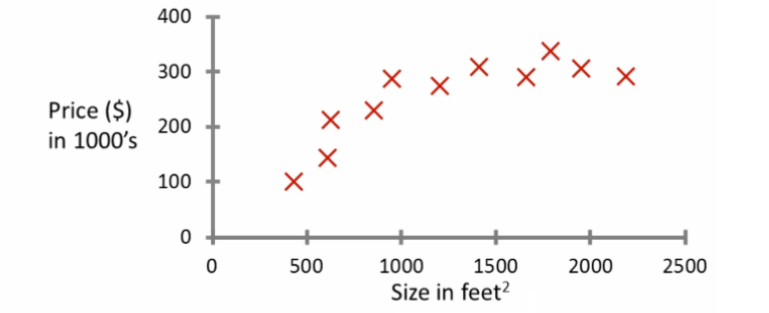
如果我们的输出变成,房子的售价比要价多还是少。这就成了一个分类问题,
无监督学习
无监督学习,让我们解决这样的问题,只有输入数据集,不知道或知道很少我们的结果应该是什么样子,但我们可以从数据得出一个结构。

无监督学习的预测结果没有反馈,即,没有老师纠正你。聚类和联想记忆都是无监督学习。
例子:
聚类:一组1000篇的论文中,并找到一种方法来(例如根据词频、句子长度、页数等 )为这些文章分组。
联想:假设一个医生有多年经验,在他的脑海中形成了病人特点和疾病之间的关联。通过病人的症状家族病史,物理属性、精神面貌等特点。
该医生联想类似的患者从而推断出可能的疾病。在这种情况下我们想估计出从病人特征映射到疾病的函数。
该课程将广泛介绍机器学习、数据挖掘和统计模式识别。
相关主题包括:
(i) 监督式学习(参数和非参数算法、支持向量机、核函数和神经网络)。
(ii) 无监督学习(集群、降维、推荐系统和深度学习)。
(iii) 机器学习实例(偏见/方差理论;机器学习和AI领域的创新)。
课程将引用很多案例和应用,您还需要学习如何在不同领域应用学习算法,例如智能机器人(感知 和控制)、文本理解(网络搜索和垃圾邮件过滤)、计算机视觉、医学信息学、音频、数据库挖掘等领域。
另外学习该课程需要用到 微积分,矩阵,概率 和 统计方面的知识。
课后的练习使用 matlab 或 octave 。Andrew 推荐使用octave 免费软件。
课程讲义的wiki地址:https://share.coursera.org/wiki/index.php/ML:Main
下一篇,机器学习—单变量线性回归。