好久没有写爬虫了,今天研究了下淘宝商品评论的内容。
一开始用最简单的方法,挂代理,加请求头,对网页请求,是抓不到数据的,在网上找了一些相关文章,也基本已经过时了,就是网站逻辑有改动,用旧的方法是抓不到的。研究了一下,终于有了结果。
1. 百度->淘宝,进入官网
最后选择男装->西装,进入宝贝详情页。下面开始打开调试模式,快捷键Ctrl + Shift + i
2. 想办法找出评论内容所在地址。
先清空调试栏(点击如下):

然后刷新页面,Ctrl + R进行刷新。
下面就开始找评论在哪里。首先点击XHR,推测评论是有AJAX展示的,点击后发现不是。
再去Doc里面找找,也不是。那就从All里面一个一个找吧。
嘿,看到了一个东西,有点像:
切,也不对,接着往下找。
坚持不懈地努力下,终于找到了:
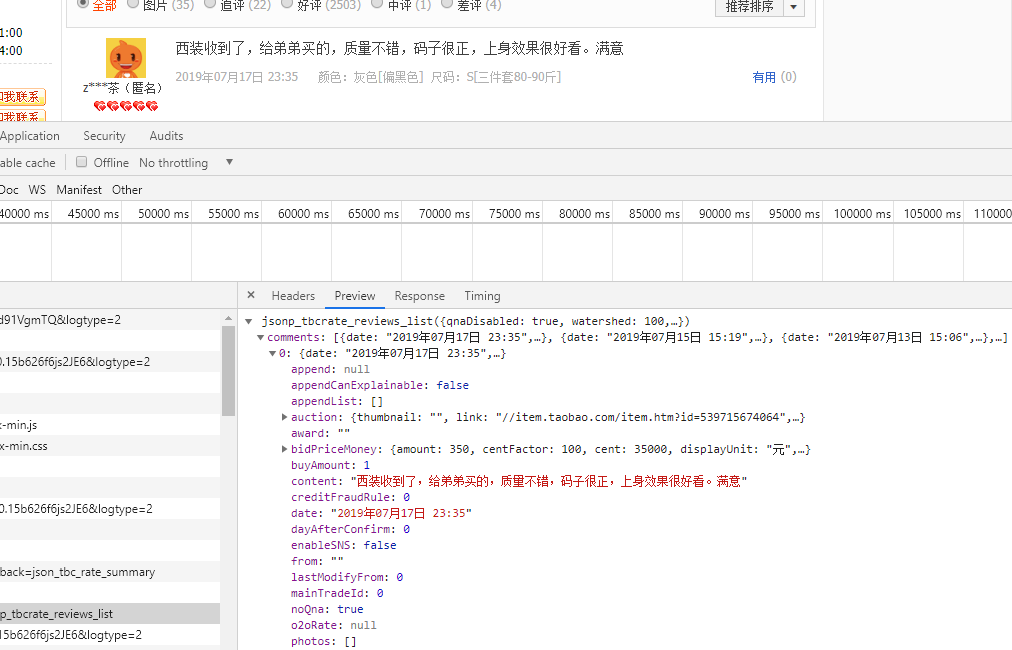
下面对这个url进行解析,只要能请求出来,那就没问题了。
3. 首先,直接添加headers,是请求不到的。那怎么办呢?一点点试呗。
最后尝试到,将请求头,请求参数全部加上,然后携带cookie,才能获取到内容,很难受。
因为,实际生产中,一旦需要验证cookie,才能获取正确响应的网站,我个人是没有太好的解决方法,只要抓取过快,就会被封掉。
代码如下:
import re import requests headers = { 'Referer': 'https://item.taobao.com/item.htm?spm=a219r.lm874.14.173.2d324edc7BaCKr&id=591671671551&ns=1&abbucket=9', 'User-Agent': '请添加自己的useragent', 'cookie':"这里请添加你自己的cookie" } url = 'https://rate.taobao.com/feedRateList.htm?' query_params = { 'auctionNumId': '569127696985', 'userNumId': '2840752540', 'currentPageNum': '1', 'pageSize': '20', 'rateType': '', 'orderType': 'sort_weight', 'attribute': '', 'sku': '', 'hasSku': 'false', 'folded': '0', 'ua': '098#E1hvhpvEvbQvU9CkvvvvvjiPRFM96jECP2M91j3mPmPv1jYbRFzUljtnPLLytjEHRsKjvpvhvvpvvvhCvvOvUvvvphvEvpCWm2KHvvwzaNoUkC4AVA1lYWmQrEt1pYsptbvqrADn9W2+FfmtEpcyTWexRdIAcUmDYE7reB6k1W29QCyawZ4Q0f0DW3CQog0HsXZpebyCvm9vvvvvphvvvvvv96CvpvB/vvm2phCvhRvvvUnvphvppvvv96CvpCCvkphvC99vvOCzpuyCvv9vvUv0cP8JVvGCvvpvvvvvRphvCvvvvvm5vpvhvvmv99==', '_ksTS': '1563849303999_1462', 'callback': 'jsonp_tbcrate_reviews_list' } response = requests.get(url=url, headers=headers, params=query_params).text print(response) contents = re.compile('"content":"(.*?)"').findall(response) for content in contents: print(content)
代码没有任何封装,能看就行,不影响交流。至于翻页部分,就不再看了。