http://blog.csdn.net/zhangskd/article/details/11225301
前言
先来直观的比较下普通链表和哈希链表:
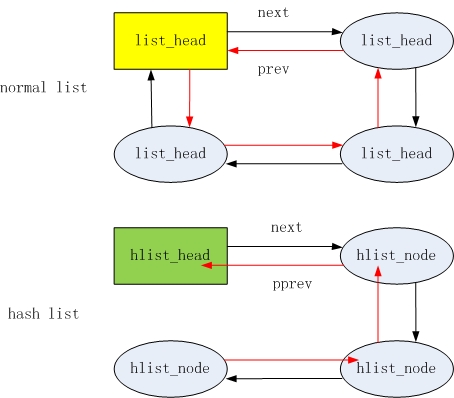
普通链表
普通链表的表头和节点相同
- struct list_head {
- struct list_head *next, *prev;
- };
哈希链表
哈希链表头
- struct hlist_head {
- struct hlist_node *first;
- };
哈希链表节点
- struct hlist_node {
- struct hlist_node *next, **pprev;
- };
设计原理
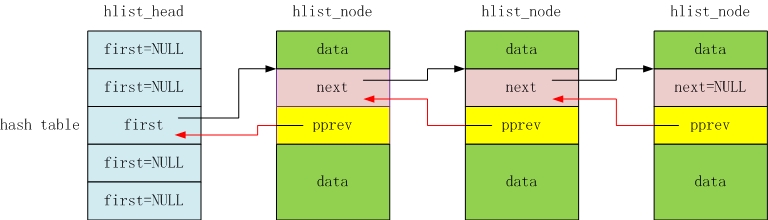
Linux链表设计者认为双指针表头双循环链表对于HASH表来说过于浪费,因而另行设计了一套用于HASH表的hlist数据结构,
即单指针表头双循环链表。hlist表头仅有一个指向首节点的指针,而没有指向尾节点的指针,这样在海量的HASH表中存储
的表头就能减少一半的空间消耗。
这里还需要注意:struct hlist_node **pprev,也就是说pprev是指向前一个节点(也可以是表头)中next指针的指针。
Q:为什么不使用struct hlist_node *prev,即让prev指向前一个节点呢?
A:因为这时候表头(hlist_head)和节点(hlist_node)的数据结构不同。如果使用struct hlist_node *prev,只适用于前一个为节点
的情况,而不适用于前一个为表头的情况。如果每次操作都要考虑指针类型转换,会是一件麻烦的事情。
所以,我们需要一种统一的操作,而不用考虑前一个元素是节点还是表头。
struct hlist_node **pprev,pprev指向前一个元素的next指针,不用管前一个元素是节点还是表头。
当我们需要操作前一个元素(节点或表头),可以统一使用*(node->pprev)来访问和修改前一元素的next(或first)指针。
原理图如下:
常用操作
(1) 初始化
- /*
- * Double linked lists with a single pointer list head.
- * Mostly useful for hash tables where the two pointer list head is too wasteful.
- * You lose the ability to access the tail in O(1).
- */
- #define HLIST_HEAD_INIT { .first = NULL }
- #define HLIST_HEAD (name) struct hlist_head name = { .first = NULL }
- #define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
(2) 插入
- /* next must be != NULL */
- static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next)
- {
- n->pprev = next->pprev;
- n->next = next;
- next->pprev = &n->next;
- *(n->pprev) = n;
- }
(3) 删除
- static inline void __hlist_del(struct hlist_node *n)
- {
- struct hlist_node *next = n->next;
- struct hlist_node **prev = n->pprev;
- *pprev = next;
- if (next)
- next->pprev = pprev;
- }
(4) 遍历
- #define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *) 0)->MEMBER)
- /*
- * container_of - cast a member of a structure out to the containing structure
- * @ptr: the pointer to the member.
- * @type: the type of the container struct this is embedded in.
- * @member: the name of the member within the struct.
- */
- #define container_of(ptr, type, member) ({
- const typeof(((type *) 0)->member) * __mptr = (ptr);
- (type *) ((char *) __mptr - offsetof(type, member)); })
- #define hlist_entry(ptr, type, member) container_of(ptr, type, member)
- #define hlist_for_each(pos, head)
- for (pos = (head)->first; pos; pos = pos->next)
- /**
- * hlist_for_each_entry - iterate over list of given type
- * @tpos: the type * to use as a loop cursor.
- * @pos: the &struct hlist_node to use a loop cursor.
- * @head: the head for your list.
- * @member: the name of the hlist_node within the struct.
- */
- #define hlist_for_each_entry(tpos, pos, head, member)
- for (pos = (head)->first;
- pos && ({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;});
- pos = pos->next)
哈希链表变种
以下是作者的说明:
Special version of lists, where end of list is not a NULL pointer,
but a 'nulls' marker, which can have many different values.
(up to 2^31 different values guaranteed on all platforms)
In the standard hlist, termination of a list is the NULL pointer.
In this special 'nulls' variant, we use the fact the objects stored in
a list are aligned on a word (4 or 8 bytes alignment).
We therefore use the last significant bit of 'ptr':
Set to 1: This is a 'nulls' end-of-list maker (ptr >> 1)
Set to 0: This is a pointer to some object (ptr)
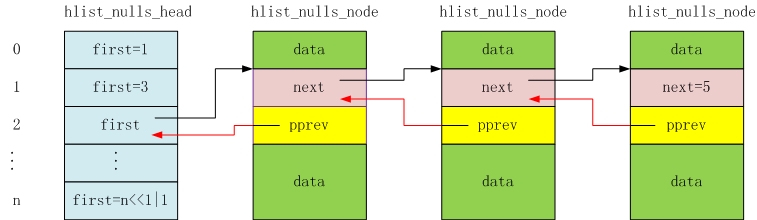
设计原理
当遍历标准的哈希链表时,如果节点为NULL,表示链表遍历完了。
哈希链表变种和标准哈希链表的区别是:链表的结束节点不是NULL。如果first或者next指针的最后一位为1,
就说明遍历到链表尾部了。
Q:为什么可以根据节点指针的最后一位是否为1来判断链表是否结束?
A:因为在一个结构体中,其元素是按4字节(32位机器)或者8字节(64位机器)对齐的。所以有效的节点指针的
最后一位总是为0。因此我们可以通过把节点指针的最后一位置为1,来作为结束标志。
- /* 表头 */
- struct hlist_nulls_head {
- struct hlist_nulls_node *first;
- };
- /* 节点 */
- struct hlist_nulls_node {
- struct hlist_nulls_node *next, **pprev;
- };
原理图如下:
常用操作
(1) 初始化
- #define INIT_HLIST_NULLS_HEAD(ptr, nulls)
- ((ptr)->first = (struct hlist_nulls_node *) (1UL | (((long) nulls) << 1)))
(2) 判断是否为结束标志
- /*
- * ptr_is_a_nulls - Test if a ptr is a nulls
- * @ptr: ptr to be tested
- */
- static inline int is_a_nulls(const struct hlist_nulls_node *ptr)
- {
- return ((unsigned long) ptr & 1);
- }
(3) 获取结束标志
- /*
- * get_nulls_value - Get the 'nulls' value of the end of chain
- * @ptr: end of chain
- * Should be called only if is_a_nulls(ptr);
- */
- static inline unsigned long get_nulls_value(const struct hlist_nulls_node *ptr)
- {
- return ((unsigned long)ptr) >> 1;
- }
(4) 插入
把节点n插入为链表的第一个节点。
- static inline void hlist_nulls_add_head(struct hlist_nulls_node *n, struct hlist_nulls_head *h)
- {
- struct hlist_nulls_node *first = h->first;
- n->next = first;
- n->pprev = &h->first;
- h->first = n;
- if (! is_a_nulls(first))
- first->pprev = &n->next;
- }
(5) 删除
- /*
- * These are non-NULL pointers that will result in page faults
- * under normal circumstances, used to verify that nobody uses
- * non-initialized list entries.
- */
- #define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
- #define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
- static inline void __hlist_nulls_del(struct hlist_nulls_node *n)
- {
- struct hlist_nulls_node *next = n->next;
- struct hlist_nulls_node **pprev = n->pprev;
- *pprev = next;
- if (! is_a_nulls(next))
- next->pprev = pprev;
- }
- static inline void hlist_nulls_del(struct hlist_nulls_node *n)
- {
- __hlist_nulls_del(n);
- n->pprev = LIST_POISON2; /* 防止再通过n访问链表 */
- }
(6) 遍历
同标准哈希链表的基本一样。
hlist_nulls_for_each_entry(tpos, pos, head, member)
hlist_nulls_for_each_entry_from(tpos, pos, member)
Author
zhangskd @ csdn blog