今日内容:
1.线程理论
2.锁: 牺牲了效率,保证了数据的安全(重点)
3.守护线程
4.GIL锁:(重点)
5.计算密集型和IO密集型
6.信号量,事件(了解)
7.补充. 子进程中不能input
1.线程理论
什么是线程:cpu的执行单位(实体)
进程: 资源分配单位
线程的创建和销毁的开销特别小
线程之间的资源共享,共享的是同一个进程中的资源
资源的共享涉及的最主要的问题就是数据的安全问题,这里我们就要用到加锁来实现.
线程的2种创建方式
方法1:
from threading import Thread
def f1(n):
print(n)
if __name__=='__main__':
t=Thread(target=f1,args=(3,) )
t.start()
方法2:
class mythread(thread):
def __init__(self,n):
super().__init__()
self.n=n
def run(self):
print(f'{n}号种子选手.')
if __name__=='__main__':
m=mythread('alex')
m.start()
2.锁: 牺牲了效率,保证了数据的安全(重点)
死锁现象: 当程序代码中出现了锁的嵌套,两个程序相互争抢拿锁,导致一方拿到一把锁,但是需要下一把锁的时候,双方都在等待对方开锁,所以导致了死锁的现象.
递归锁:(重点推荐) 他可以解决死锁的现象
import RLock 首先递归锁本身就是一个互斥锁,维护了一个计数器,每次acquire一次就加一,release一次就减一,当计数器的值为0的时候,剩下的程序才能继续抢这个锁.
3.守护线程: 等待所有的非守护线程结束时他直接结束. 如果守护线程之外的所有线程执行完毕后,守护线程直接完毕(守护线程已经执行了的部分也是会被打印的)
守护进程: 主进程的代码结束后,守护进程直接结束(不管运没运行完毕).
import time
from threading import Thread
from multiprocessing import Process
def f1():
time.sleep(2)
print('1号线程')
def f2():
time.sleep(3)
print('2号线程')
if __name__ == '__main__':
# t1 = Thread(target=f1,)
# t2 = Thread(target=f2,)
# t1.daemon = True
# t2.daemon = True
# t1.start()
# t2.start()
# print('主线程结束')
t1 = Process(target=f1, )
t2 = Process(target=f2, )
# t1.daemon = True
# # t2.daemon = True
t1.start()
t2.start()
print('主进程结束'
4.GIL锁:(重点)
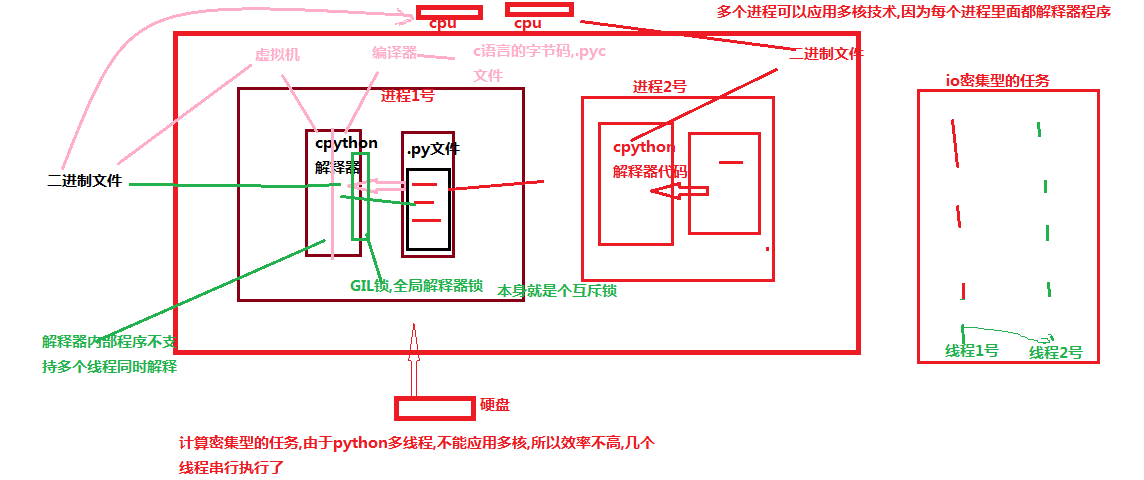
GIL锁: 全局解释器锁,他的本身就是一个互斥锁
解释器内部程序不支持多个线程同时解释
多个进程可以应用多核技术,因为每个进程里面都有解释器程序
这个图的含义是代码可以有多个进程进入cpu去执行,但是一个进程里面只允许有一个线程进入python解释器中解释.
原理: 首先硬盘接收到一个执行进程的数据,硬盘去内存开启一个空间,然后进程中的n条代码去cpython解释器中争抢进入cpython 解释器.由于解释器中存在GIL锁,所以只能有一条数据进入cpython解释器中去执行代码.争抢到的代码先到编译器中编译成c语言的字节码(.pyc文件),然后到虚拟机中转化为2进制文件,最后虚拟机将2进制文件发送给cpu去执行这段代码.
5.计算密集型和IO密集型
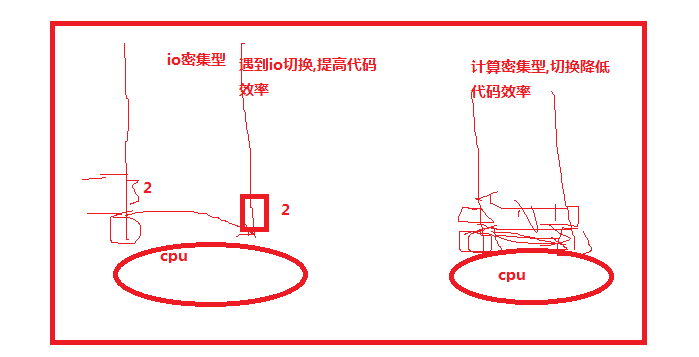
计算密集型数据,
如果两边同时运行,这边计算一点点,然后切换到另一遍计算一点点,也是可以的,但是再切换的同时切换也是会耗时间的,如果一个程序代码量很大,机器来回进行切换所耗的时间也是很长的.
IO密集型数据
这样程序遇到了IO就进行切换,提高了代码的运行效率
6.信号量,事件(了解)
7.补充. 子进程中不能input
from threading import Thread
from multiprocessing inport Process
def f1():
name=input('请输入你的姓名:') # 子程序中不能使用input
print(name)
if __name__=='__main__':
input('请输入你的信息:') #主程序中可以使用input,
t=Thread(target=f1,)
t.start()
print('主程序结束')