数据表结构
CREATE TABLE `ad_keyword` ( `id` int(11) NOT NULL AUTO_INCREMENT, `plan_goods_id` int(11) DEFAULT NULL, `impr_num` int(11) DEFAULT NULL, `click_num` int(11) DEFAULT NULL, `total_spend` int(11) DEFAULT NULL, `pay_gmv` int(11) DEFAULT NULL, `orders_num` int(11) DEFAULT NULL, `roi` double DEFAULT NULL, `clk_rate` double DEFAULT NULL, `word` varchar(200) DEFAULT NULL, `date` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`), KEY `word_index` (`word`), KEY `date_index` (`date`), KEY `ad_id_index` (`plan_goods_id`) ) ENGINE=InnoDB AUTO_INCREMENT=127133688 DEFAULT CHARSET=utf8;
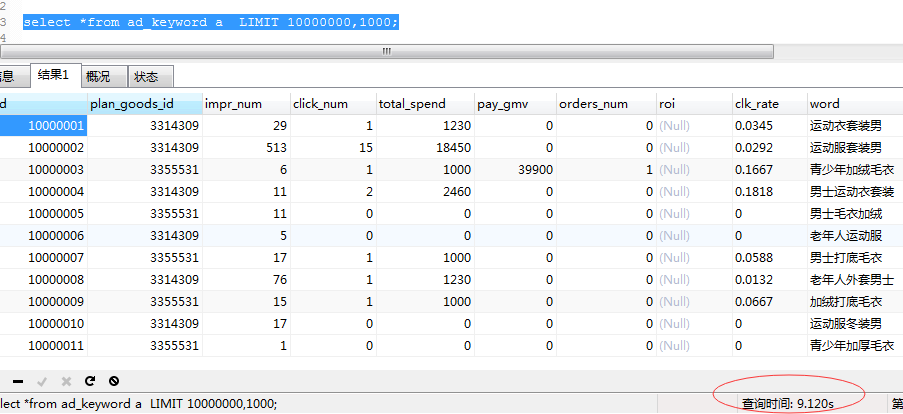
select *from ad_keyword a LIMIT 10000000,1000;
数据库表中数据大概为1.2亿,每次查询都要花上10多秒。而且分页大小是1000.
优化后:
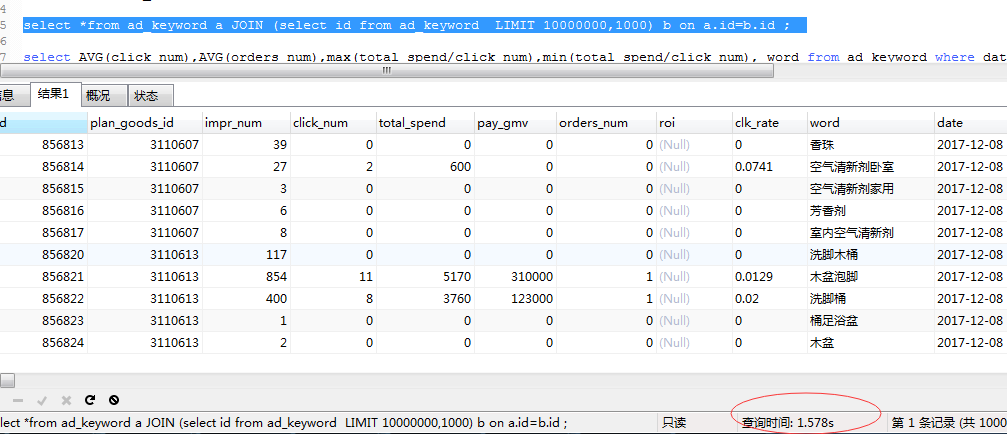
select *from ad_keyword a JOIN (select id from ad_keyword LIMIT 10000000,1000) b on a.id=b.id ;
从中我们也能总结出两件事情:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2. 对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列)只用了1.57秒。