通过这个类,大家可以在脱离浏览器的基础上模拟浏览器对互联网上的资源的访问和发送信息。
WebClient类不能被继承,在dotnet1.1框架中已经为我们提供了WebRequest和WebResponse两个强大的类来
处理向URI标示的资源和获取数据了。然后,不足的是利用WebRequest和WebResponse时设置过于复杂。
使用起来颇为费劲。于是乎有了现在的WebClient,WebClient其实可以理解为对WebRequest和WebResponse等
协作的封装。它使人们使用起来更加简单方便,然后它也有先天不足的地方。那就是缺少对cookies/session的
支持,用户无法对是否自动url转向的控制,还有就是缺少对代理服务器的支持。关于session/url转向控制/代理
服务器的使用我将在以后关于WebRequest/WebResponse的话题里面向大家介绍。下面先给大家简单介绍一
下WebClinet类。
类名:WebClient
命名空间System.Net.WebClient
公共构造函数
| WebClient 构造函数 | 初始化 WebClient 类的新实例。 |
公共属性
| BaseAddress | 获取或设置 WebClient 发出请求的基 URI。 |
| Container(从 Component 继承) | 获取 IContainer,它包含 Component。 |
| Credentials | 获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 |
| Headers | 获取或设置与请求关联的标头名称/值对集合。 |
| QueryString | 获取或设置与请求关联的查询名称/值对集合。 |
| ResponseHeaders | 获取与响应关联的标头名称/值对集合。 |
| Site(从 Component 继承) | 获取或设置 Component 的 ISite。 |
公共方法
| CreateObjRef(从 MarshalByRefObject 继承) | 创建一个对象,该对象包含生成用于与远程对象进行通讯的代理所需的全部相关信息。 |
| Dispose(从 Component 继承) | 已重载。释放由 Component 占用的资源。 |
| DownloadData | 从具有指定 URI 的资源下载数据。 |
| DownloadFile | 从具有指定 URI 的资源将数据下载到本地文件。 |
| Equals(从 Object 继承) | 已重载。确定两个 Object 实例是否相等。 |
| GetHashCode(从 Object 继承) | 用作特定类型的哈希函数,适合在哈希算法和数据结构(如哈希表)中使用。 |
| GetLifetimeService(从 MarshalByRefObject 继承) | 检索控制此实例的生存期策略的当前生存期服务对象。 |
| GetType(从 Object 继承) | 获取当前实例的 Type。 |
| InitializeLifetimeService(从 MarshalByRefObject 继承) | 获取控制此实例的生存期策略的生存期服务对象。 |
| OpenRead | 为从具有指定 URI 的资源下载的数据打开一个可读的流。 |
| OpenWrite | 已重载。打开一个流以将数据写入具有指定 URI 的资源。 |
| ToString(从 Object 继承) | 返回表示当前 Object 的 String。 |
| UploadData | 已重载。将数据缓冲区上载到具有指定 URI 的资源。 |
| UploadFile | 已重载。将本地文件上载到具有指定 URI 的资源。 |
| UploadValues | 已重载。将名称/值集合上载到具有指定 URI 的资源。 |
从上表中我们可以看到WebClient提供四种将数据上载到资源的方法:
- OpenWrite 返回一个用于将数据发送到资源的 Stream。
- UploadData 将字节数组发送到资源并返回包含任何响应的字节数组。
- UploadFile 将本地文件发送到资源并返回包含任何响应的字节数组。
- UploadValues 将 NameValueCollection 发送到资源并返回包含任何响应的字节数组。
另外WebClient还提供三种从资源下载数据的方法:
- DownloadData 从资源下载数据并返回字节数组。
- DownloadFile 从资源将数据下载到本地文件。
- OpenRead 从资源以 Stream 的形式返回数据。
下面我们将通过一个简单的应用程序来测试WebClient的最简单用法作为本小节的结束让大家对WebClient有个初步的认识
例子1:利用WebClient实现对博客园首页的访问
首先我们用HttpLook对这次访问进行分析,为了方便分析我特别将浏览器对图片的访问去掉 让我们能看到更简便的分析结果
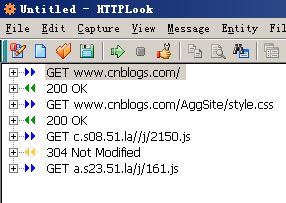
我们可以看到整个过程中我们发起了4次资源请求,其中第一次是对博客园首页进行访问
第二次访问的是样式表文件,第三和四次访问的是js脚本。
我们点击第一项可以看见关于这次资源访问的http头部信息,所谓http头部就是我们不能看见的浏览器和远程服务器传递的一些不可见元素。
 GET / HTTP/1.1
GET / HTTP/1.12
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*3
Accept-Language: zh-cn4
UA-CPU: x865
Accept-Encoding: gzip, deflate6
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)7
Host: www.cnblogs.com8
Connection: Keep-Alive9
Cookie: .DottextCookie=(隐藏) 这些http信息包含了浏览器访问的过程。其中
第一行:请求地址的相对路径和使用协议 相对路径为/ 协议采用http1.1
第二行:表示我们请求的资源种类。
第三行:我们的语言是简体中文。
第四行:我们使用的cup结构。这个http头在一般的网页中并不过见。估计是博客园的一次调查??
第五行:标示采用gzip方式压缩html编码进行传递。只有一些浏览器支持的gzip解压缩时采用这种方式传递文本。由于我们
要写的程序不具备gzi解压缩的能力 所以我们不考虑使用这种方式发送请求。
第六行:浏览器说明
第七行:当前主机地址
第八行:连接请求状态
第九行:cookies信息
我在新建的应用程序里面利用WebClient来实现这了一过程。
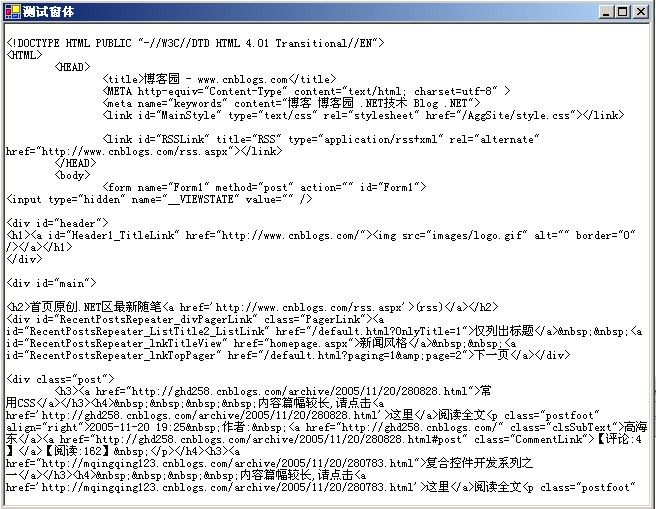
下面我将就关键实现做一些解释
WebClient _client=new WebClient();2
_client.BaseAddress="http://www.cnblogs.com";3
_client.Headers.Add("Accept","image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*");4
_client.Headers.Add("Accept-Language","zh-cn");5
_client.Headers.Add("UA-CPU","x86");6
//_client.Headers.Add("Accept-Encoding","gzip, deflate");7
_client.Headers.Add("User-Agent","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)");8
System.IO.Stream objStream=_client.OpenRead("/");9
System.IO.StreamReader _read=new System.IO.StreamReader(objStream,System.Text.Encoding.UTF8);10
textBox1.Text=_read.ReadToEnd();
第一行:新建一个WebClient 实例_client
第二行~第七行:将上边捕捉到的Http头部放入到_client实例,注意第六行的被注释掉了。因为我们的程序无法进行gzip解码所以如果这样请求
获得的资源可能无法解码。当然我们可以给程序加入gzip处理的模块 那是题外话了。
第八行:利用_client.OpenRead(string URI)的方法获取网上资源的Stream
第九行:利用StreamReader将Stream用我们需要的编码方法去解析。这里使用了UTF8。对应不同的网站可以使用Default等不同的解码方法。
第十行:将我们解码后的内容放到textBox1里面显示出来
好了 大致关于WebClient的介绍就到这里了。以后将为大家陆续介绍WebClient的各种属性和方法。
利用WebClient做个资源小偷其实是很简单的,所以大家一定要防盗链阿!!!