这次尝试用逻辑回归来解决泰坦尼克号的问题。本文参考了https://zhuanlan.zhihu.com/p/28408516 和 https://www.cnblogs.com/BYRans/p/4713624.html
逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。二分类问题是指预测的y值只有两个取值的问题。
逻辑回归和线性回归都属于广义上的线性模型。逻辑回归假设因变量y服从伯努利分布,线性回归假设因变量y服从高斯分布。
逻辑回归通过Sigmoid函数引入了非线性因素。
用python画一下函数图像吧。
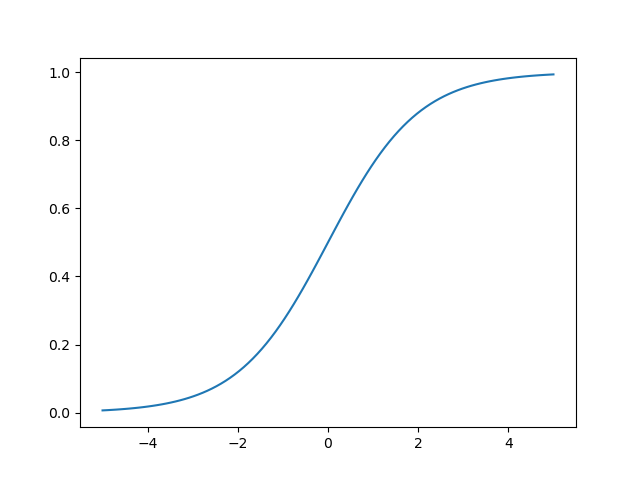
逻辑回归本质上是线性回归,只是在特征到结果的映射中增加了一层函数映射。逻辑回归的表达式:
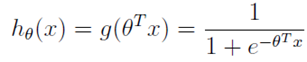
函数h的意思是在给定的x和θ的条件下g = 1的概率。决策边界,也称为决策面,是用于在N维空间,将不同类别样本分开的平面或曲面。
决策边界其实就是一个方程,在逻辑回归中,决策边界由xθ**t = 0定义。(也就是,在该平面或曲面一侧的样本在逻辑回归中被归为一类,另一侧被归为另一类。
下面开始干活吧,参考了 https://blog.csdn.net/zpxcod007/article/details/79966273
先增加一个Family字段,根据SibSp与Parch之和分类。如果船上没有亲属,值为0,有1-3位亲属,值为1,有4位或以上亲属,值为3
train_data["Family"] = train_data["SibSp"] + train_data["Parch"]
train_data.loc[(train_data.Family == 0), "Family"] = 0
train_data.loc[((train_data.Family > 0) & (train_data.Family < 4)), "Family"] = 1
train_data.loc[(train_data.Family >= 4), "Family"] = 2
test_data["Family"] = test_data["SibSp"] + test_data["Parch"]
test_data.loc[(test_data.Family == 0), "Family"] = 0
test_data.loc[((test_data.Family > 0) & (test_data.Family < 4)), "Family"] = 1
test_data.loc[(test_data.Family >= 4), "Family"] = 2
然后进行建模分析
from sklearn.linear_model import LogisticRegression as LR
from sklearn.model_selection import KFold, cross_val_score
kf = KFold(5, random_state = 0)
predictors = ['Pclass', 'Sex', 'Age', 'Family', 'Embarked', 'Cabin']
lr = LR(C = 0.1, solver = "liblinear", penalty = "l2")
lr.fit(train_data[predictors], train_data["Survived"])
print(cross_val_score(lr, train_data[predictors], train_data["Survived"], cv = kf).mean())
accuracys = []
testLR = LR(C = 0.1, solver = "liblinear", penalty = "l2")
for train, test in kf.split(train_data):
testLR.fit(train_data.loc[train, predictors], train_data.loc[train, "Survived"])
pred = testLR.predict_proba(train_data.loc[test, predictors])
# print(pred.shape)
new_pred = pred[:, 1]
new_pred[new_pred >= 0.5] = 1
new_pred[new_pred < 0.5] = 0
accuracy = len(new_pred[new_pred == train_data.loc[test, "Survived"]])/len(test)
accuracys.append(accuracy)
print(np.mean(accuracys))
结果
0.8069549934090766
0.8069549934090766
测试的准确率达80%。输出提交到kaggle上看看。

跟线性回归一样……学其它方法吧。
画个图看看

再查一下model_selection的KFold函数,sklearn.model_selection.KFold(n_splits=3, shuffle=False, random_state=None)
其是做K折交叉验证,将训练/测试数据集划分n_splits个互斥子集,每次用其中一个子集当作验证集,剩下的n_splits-1个作为训练集,进行n_splits次训练和测试,得到n_splits个结果。
然后用split(X, y=None, groups=None):将数据集划分成训练集和测试集,返回索引生成器。
本文代码: https://github.com/zwdnet/MyQuant/blob/master/titanic/submit03.py!
我发文章的四个地方,欢迎大家在朋友圈等地方分享,欢迎点“在看”。
我的个人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客园博客地址: https://www.cnblogs.com/zwdnet/
我的微信个人订阅号:赵瑜敏的口腔医学学习园地