处理 复杂的要求的时候,有时一个mapreduce程序是完成不了的,往往需要多个mapreduce程序,这个时候就要牵扯到各个任务之间的依赖关系,所谓 依赖就是一个MR Job 的处理结果是另外的MR 的输入,以此类推,完成几个mapreduce程序,得到最后的结果
下面是用Mapreduce写的tf-idf算法微博关键字广告推送案例,总共三个job,贴出完整代码。
第一个job代码如下:
FirstMapper
import java.io.IOException;
import java.io.StringReader;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
/**
* 第一个MR,计算TF和计算
* @author root
*
*/
public class FirstMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String [] v=value.toString().trim().split(" ");//制表符隔开
if(v.length>=2){
String id=v[0].trim();
String content=v[1];
StringReader sr=new StringReader(content);
IKSegmenter ikSegmenter=new IKSegmenter(sr, true);
Lexeme word=null;
while((word=ikSegmenter.next())!=null){
String w=word.getLexemeText();
context.write(new Text(w+"_"+id),new IntWritable(1) );//某个词出现一次,输出1
}
context.write(new Text("count"), new IntWritable(1));//微博条数,每读一条输出1
}else {
System.out.println(value.toString()+"-----------------");
}
}
}
FirstPartition
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
/**
* 第一个map自定义分区
* @author root
*
*/
public class FirstPartition extends HashPartitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numReduceTasks) {
if(key.equals(new Text("count"))){
return 3;//代表第四个区,从0开始
}else{
return super.getPartition(key, value, numReduceTasks-1);
}
}
}
FirstReduce
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* C1_001,2 c1在001的微博中出现2次
* C2_002,1
* count ,1000 微博条数
* @author root
*
*/
public class FirstReduce extends Reducer<Text, IntWritable, Text,IntWritable >{
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
int sum=0;
for(IntWritable i:arg1){
//按微博分组,累加每个词在每条微博中出现的次数
sum=sum+i.get();
}
if(arg0.equals(new Text("count"))){
System.out.println(arg0.toString()+"-----"+sum);//微博总条数
}
arg2.write(arg0,new IntWritable(sum));
}
}
第二个job:
SecondMapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* 统计df:词在多少个微博中出现过
* @author root
*
*/
public class TwoMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//获取当前mapper task 的数据片段
FileSplit fs=(FileSplit) context.getInputSplit();
if(!fs.getPath().getName().contains("part-r-00003")){//一个reduce一个文件,part-r-00003代表第四个分区生成的文件,文件内容为“count 微博条数”
//其余三个分区记录了词组在某条微博中出现的次数;
String[] v=value.toString().trim().split(" ");
if(v.length>=2){
String []ss=v[0].split("_");
if(ss.length>=2){
String word=ss[0];
context.write(new Text(word), new IntWritable(1));//词在微博中出现n次,每一条输出1
}
}else{
System.out.println(value.toString()+"---------------");
}
}
}
}
ScondReduce
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TwoReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
int sum=0;
for(IntWritable i:arg1){
sum=sum+i.get();
}
arg2.write(arg0, new IntWritable(sum));
}
}
第三个job:
ThirdMapper
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.text.NumberFormat;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/*最后计算
* @author root
*
*/
public class LastMapper extends Mapper<LongWritable,Text,Text,Text> {
// 存放微博总数
public static Map<String,Integer> cmap=null;
//存放df
public static Map<String,Integer> df=null;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
FileSplit fs=(FileSplit) context.getInputSplit();
if(!fs.getPath().getName().endsWith("part-r-00003")){
String[] v = value.toString().trim().split(" ");
if(v.length>=2){
int tf=Integer.parseInt(v[1].trim());
String []ss=v[0].split("_");
if(ss.length>=2){
String word=ss[0];
String uid=ss[1];
double s=tf*Math.log(cmap.get("count")/df.get(word));
NumberFormat nf=NumberFormat.getInstance();
nf.setMinimumIntegerDigits(5);
context.write(new Text(uid), new Text(word+":"+nf.format(s)));
}else{
System.out.println(value.toString()+"------");
}
}
}
}
// 在map方法执行之前
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
System.out.println("----------------");
if(cmap==null || cmap.size()==0 || df==null || df.size()==0){
URI [] ss=context.getCacheFiles();
if(ss!=null){
for(int i=0;i<ss.length;i++){
URI uri=ss[i];
if(uri.getPath().endsWith("part-r-00003")){//该文件存放的微博的总条数
Path path=new Path(uri.getPath());
BufferedReader br=new BufferedReader(new FileReader(path.getName()));
String line=br.readLine();
if(line.startsWith("count")){
String []ls=line.split(" ");//制表符左边是count 右边是总微博数
cmap=new HashMap<String,Integer>();
cmap.put(ls[0], Integer.parseInt(ls[1].trim()));
}
br.close();
}else if(uri.getPath().endsWith("part-r-00000")){//每个次在所有微博中出现的总次数
df=new HashMap<String,Integer>();
Path path=new Path(uri.getPath());
BufferedReader br=new BufferedReader(new FileReader(path.getName()));
String line;
while((line=br.readLine())!=null){
String []ls=line.split(" ");
df.put(ls[0],Integer.parseInt(ls[1].trim()));
}
br.close();
}
}
}
}
}
}
ThirdReduce
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class LastReduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text arg0, Iterable<Text> arg1, Reducer<Text, Text, Text, Text>.Context arg2)
throws IOException, InterruptedException {
StringBuffer sb=new StringBuffer();
for(Text i:arg1){
sb.append(i.toString()+" ");
}
arg2.write(arg0, new Text(sb.toString()));
}
}
以下是JobControl代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class StarJob {
// 启动函数
public static void main(String[] args) throws IOException {
Configuration config=new Configuration();
config.set("fs.defaultFS", "hdfs://node4:8020");
FileSystem fs=FileSystem.get(config);
JobConf conf = new JobConf(StarJob.class);
// 第一个job的配置
@SuppressWarnings("deprecation")
Job job1 = new Job(conf, "join1");
job1.setJarByClass(StarJob.class);
job1.setJobName("weibo1");
job1.setMapperClass(FirstMapper.class);
job1.setCombinerClass(FirstReduce.class);
job1.setReducerClass(FirstReduce.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
job1.setNumReduceTasks(4);
job1.setPartitionerClass(FirstPartition.class);
// 加入控制容器
ControlledJob ctrljob1 = new ControlledJob(conf);
ctrljob1.setJob(job1);
// job1的输入输出文件路径
FileInputFormat.addInputPath(job1, new Path("hdfs://node4:8020/usr/input/tf-idf"));
Path path1=new Path("hdfs://node4:8020/usr/output/weibo1");
if(fs.exists(path1)){
fs.delete(path1,true);
}
FileOutputFormat.setOutputPath(job1, path1);
// 第二个作业的配置
@SuppressWarnings("deprecation")
Job job2 = new Job(conf, "Join2");
job2.setJarByClass(StarJob.class);
job2.setJobName("weibo2");
job2.setMapperClass(TwoMapper.class);
job2.setCombinerClass(TwoReduce.class);
job2.setReducerClass(TwoReduce.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(IntWritable.class);
// 作业2加入控制容器
ControlledJob ctrljob2 = new ControlledJob(conf);
ctrljob2.setJob(job2);
// 设置多个作业直接的依赖关系
// 如下所写:
// 意思为job2的启动,依赖于job1作业的完成
ctrljob2.addDependingJob(ctrljob1);
// 输入路径是上一个作业的输出路径,因此这里填path1,要和上面对应好
FileInputFormat.addInputPath(job2, path1);
// 输出路径从新传入一个参数,这里需要注意,因为我们最后的输出文件一定要是没有出现过得
// 因此我们在这里new Path(args[2])因为args[2]在上面没有用过,只要和上面不同就可以了
Path path2=new Path("hdfs://node4:8020/usr/output/weibo2");
if(fs.exists(path2)){
fs.delete(path2,true);
}
FileOutputFormat.setOutputPath(job2, path2);
//第三个作业的配置
@SuppressWarnings("deprecation")
Job job3=new Job(conf,"join3");
job3.setJarByClass(StarJob.class);
job3.setJobName("weibo3");
// DistributedCache.addCacheFile(uri, conf);
//2.5
//把微博总数加载到内存
// job3.addCacheFile(new Path("hdfs:node4:8020/usr/output/weibo1/part-r-00003").toUri());
//把df加载到内存
// job3.addCacheFile(new Path("hdfs:node4:8020/usr/output/weibo2/part-r-00000").toUri());
job3.setOutputKeyClass(Text.class);
job3.setOutputValueClass(Text.class);
job3.setMapperClass(LastMapper.class);
job3.setReducerClass(LastReduce.class);
// 作业3加入控制容器
ControlledJob ctrljob3 = new ControlledJob(conf);
ctrljob3.setJob(job3);
ctrljob3.addDependingJob(ctrljob2);
FileInputFormat.addInputPath(job3, path2);
Path path3=new Path("hdfs://node4:8020/usr/output/weibo3");
if(fs.exists(path3)){
fs.delete(path3,true);
}
FileOutputFormat.setOutputPath(job3, path3);
// 主的控制容器,控制上面的总的3个子作业
JobControl jobCtrl = new JobControl("myctrl");
// 添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
jobCtrl.addJob(ctrljob3);
// 在线程启动,记住一定要有这个
Thread t = new Thread(jobCtrl);
t.start();
while (true) {
if (jobCtrl.allFinished()) {// 如果作业成功完成,就打印成功作业的信息
System.out.println(jobCtrl.getSuccessfulJobList());
System.out.println("所有job执行完毕");
jobCtrl.stop();
break;
}
}
}
}
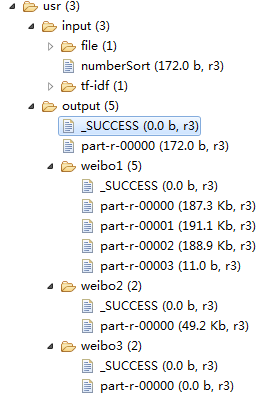
执行成功后文件下图所示
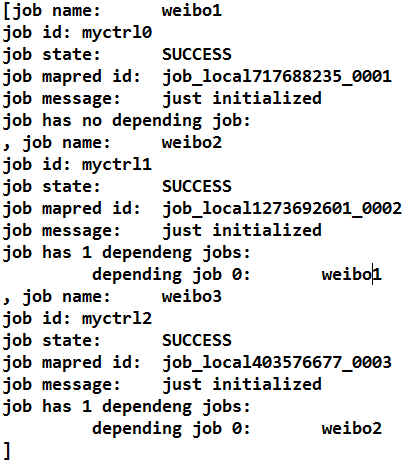
控制台打印: