模块概念
模块的四种形式
1.自定义模块
自己写的.py文件,里面编写了一堆函数
2.第三方模块
已被编译为共享库或者DLL的c或c++的扩展
3.内置模块
使用c编写并链接到python解释器的内置模块
4.包
把一系列模块组织到一起的文件夹(每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包)
导入模块的两种方式
模块的重复导入会直接引用之前创造好的结果,不会重复执行模块的文件,即重复导入会发生:sys=sys=模块名称空间的内存地址,所以不存在import的模块代码执行两次,除非别的模块import你
import首次导入模块发生的3件事
1.以模块名字为准创造一个模块的名称空间
2.执行模块对应的文件,将执行过程中的名称都丢到模块的名称空间
3.当前执行文件中就可以拿到这个模块对象,但是需要通过模块对象执行它内部的函数
from...import...
1.以模块名字为准创造一个模块的名称空间
2.执行模块对应的文件,将执行过程中的名称都丢到模块的名称空间
3.当前执行文件中就可以拿到这个模块中的某个函数对象,然后可以执行它,相比import不用加前缀
优点:不用加前缀,代码更加精简
缺点:容易与当前执行文件中名称空间中的名字冲突
循环导入问题
循环导入,会因为值没有找到报错
解决方案
1.将import相关代码放在函数内部,可以保证下次不会被执行到,需要使用的时候执行相关函数即可
zx2.py
def zx():
import zx1
print(zx1.y)
x = 10
zx()
zx1.py
def zx():
import zx2
print(zx2.x)
y = 10
10
2.把变量放在import上面,确保能找到值
zx1.py
y=10
import zx2
print(zx2.x)
zx2.py
x=20
import zx1
print(zx1.y)
具体运行过程可以使用DEBUG查看
模块搜索路劲的顺序
1.先从内存中寻找已经加载的模块
2.内置的模块
3.自定义模块
4.环境变量sys.path中去找
可通过以下方法找环境变量,然后环境变量可以自己添加
import sys
print(f"sys.path: {sys.path}")
python文件的两种用途
1.脚本,可以直接用来执行
2.模块,被其他脚本导入使用
当执行text.py时__name__=__main__,当text.py被当做模块import时,__name__=tetx
text.py
def f1():
print('from f1')
def f2():
print('from f2')
print(__name__)
if __name__ == '__main__':
f1()
f2()
包
导入包的三件事
1.创建一个包的名称空间
2.由于包只是一个文件夹,因此会找到__init__.py运行,会将包下需要引用的.py文件执行,将执行过程中的产生的对象,存放在包的名称空间
3.然后在执行文件中import可以拿到包的对象
包的关键__init__.py
init.py是整个包的关键,文件夹是否包,就看有没有这个py文件,然后里面的内容,是决定包功能的代码。(具体写法和模块相同)
手工打包
经过大量实验探究其原理
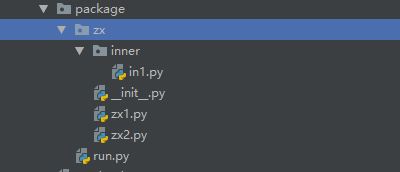
如图run为执行文件,zx为二层的包
1.run执行文件,执行import zx,执行文件只能找到zx包,然后运行__init.py__文件,由于zx里面的py文件都是属于zx包的,而且执行文件调用也是通过zx调用的,所以要指明父包。
import zx
zx.z1()
zx.z2()
zx.in2()
init.py
from zx.zx1 import z1
from .zx2 import z2
from .inner.in1 import in2
可以zx.或者.的方式,然后如果zx下面还有包,zx下面的包可以普通文件夹,也可以是带init.py的包,以上代码是普通文件,如果是包的话同理,去寻找init.py文件即可,一层一层传递对象引用。
绝对导入和相对导入
绝对导入:
# aaa/.py
from aaa.m1 import func1
from aaa.m2 import func2
相对导入:
- .代表当前被导入文件所在的文件夹
- ..代表当前被导入文件所在的文件夹的上一级
- ...代表当前被导入文件所在的文件夹的上一级的上一级
from .m1 import func1
from .m2 import func2