1. 将新闻的正文内容保存到文本文件。
2. 将新闻数据结构化为字典的列表:
- 单条新闻的详情-->字典news
- 一个列表页所有单条新闻汇总-->列表newsls.append(news)
- 所有列表页的所有新闻汇总列表newstotal.extend(newsls)
3. 安装pandas,用pandas.DataFrame(newstotal),创建一个DataFrame对象df.
4. 通过df将提取的数据保存到csv或excel 文件。
5. 用pandas提供的函数和方法进行数据分析:
- 提取包含点击次数、标题、来源的前6行数据
- 提取‘学校综合办’发布的,‘点击次数’超过3000的新闻。
- 提取'国际学院'和'学生工作处'发布的新闻。
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas #获取点击次数 def getClickCount(newsUrl): newId=re.search('\_(.*).html',newsUrl).group(1).split('/')[1] clickUrl="http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(newId) clickStr = requests.get(clickUrl).text count = re.search("hits').html('(.*)');", clickStr).group(1) return count #数据写入文件 def writeNewsContent(content): f=open('Get News.txt','a',encoding='utf-8') f.write(content) f.close() #获取新闻详情 def getNewsDetail(newsurl): resd=requests.get(newsurl) resd.encoding='utf-8' soupd=BeautifulSoup(resd.text,'html.parser') news={} news['title']=soupd.select('.show-title')[0].text # news['newsurl']=newsurl info=soupd.select('.show-info')[0].text news['dt']=datetime.strptime(info.lstrip('发布时间:')[0:19],'%Y-%m-%d %H:%M:%S') news['click'] = int(getClickCount(newsurl)) if info.find('来源')>0: news['source'] =info[info.find('来源:'):].split()[0].lstrip('来源:') else: news['source']='none' if info.find('作者:') > 0: news['author'] = info[info.find('作者:'):].split()[0].lstrip('作者:') else: news['author'] = 'none' # news['content']=soupd.select('.show-content')[0].text.strip() #获取文章内容并写入到文件中 content=soupd.select('.show-content')[0].text.strip() writeNewsContent(content) return news def getListPage(listPageUrl): res=requests.get(listPageUrl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') newsList=[] for news in soup.select('li'): if len(news.select('.news-list-title'))>0: a=news.select('a')[0].attrs['href'] newsList.append(getNewsDetail(a)) return (newsList) def getPageNumber(): ListPageUrl="http://news.gzcc.cn/html/xiaoyuanxinwen/" res=requests.get(ListPageUrl) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') n = int(soup.select('.a1')[0].text.rstrip('条'))//10+1 return n newsTotal=[] firstPage='http://news.gzcc.cn/html/xiaoyuanxinwen/' newsTotal.extend(getListPage(firstPage)) n=getPageNumber() for i in range(n,n+1): listUrl= 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) newsTotal.extend(getListPage(listUrl)) #数据写入excel文件 df=pandas.DataFrame(newsTotal) df.to_excel("Get News.xlsx") #提取包含点击次数、标题、来源的前6行数据 print(df.head(6)) #提取‘学校综合办’发布的,‘点击次数’超过3000的新闻。 print(df[['author','click','source']]) print(df[df['click']>3000]) #提取'国际学院'和'学生工作处'发布的新闻。 sou=['国际学院','学生工作处'] print(df[df['source'].isin(sou)])
运行效果图如下:

内容存储进文本:
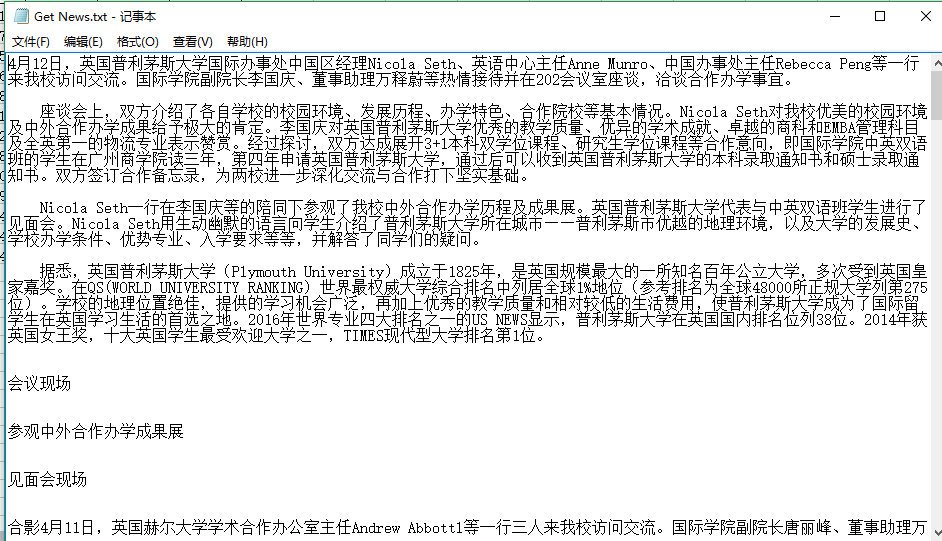
内容存储进excel文件:
