python基础python中的可变不可变类型数据类型列表元祖列表和元组常用函数字符串字典将两个列表组合成字典集合字符编码python2和python3的区别python2和python3中编码转换深拷贝、浅拷贝三元运算IO多路复用select、poll 、epoll(同步io)进程(资源分配的单位)、线程(操作系统调度的最小单位)、协程进程: 一个在运行起来的程序 系统给他分配资源 (运行在内存) 提资源进程说明进程池线程: 操作系统最小的调度单位,状态保存在cpu的栈中常用方法join()方法isAlive()方法getName()方法setDaemon()方法线程锁线程特性线程池协程: 微线程,纤程。 类似于单线程,不同于单线程,因为它可以实现并发效果,因为有gevent(封装了c语言的greenlet) 遇io自动切换(greenlet可以检测io),把这个io请求交给epoll猴子补丁协程优点:缺点:高阶函数1.map2.reduce3.filter4.sorted5.lambda(匿名函数)GIL全局解释器锁1、什么是GIL2、GIL的作用3、GIL的影响4、如何避免GIL的影响5 为什么有时候加了GIL全局解释器锁 ,还要在加线程锁?线程锁装饰器、迭代器、生成器迭代器 含有iter和next方法 (包含next方法的可迭代对象就是迭代器)迭代器的定义:可迭代对象迭代器和可迭代对象关系:迭代器仅是一容器对象,它实现了迭代器协议。它有两个基本方法iter方法会返回一个迭代器(iterator),所谓的迭代器就是具有next方法的对象。在调用next方法时,迭代器会返回它的下一个值,如果next方法被调用,但迭代器中没有值可以返就会引发一个StopIteration异常生成器yield运行机制手写斐波那契迭代器生成器区别装饰器装饰器必须准寻得原则:手写三级装饰器装饰器的应用场景闭包闭包特点os和sys模块的作用?面向对象面向对象方法静态方法类方法属性方法特殊(魔术)方法单例模式面向对象属性公有属性普通属性私有属性反射新式类和经典类的区别面向对象深度优先和广度优先是什么?三大特性:封装,继承,多态Encapsulation 封装(隐藏实现细节)Inheritance 继承(代码重用)Polymorphism 多态(接口重用)垃圾回收机制1.引用计数原理优点缺点2.标记-清除原理3.分代回收三种读文件方式1.readline()2.readlines()3.read(size)tcp udptcp三次握手四次挥手TCP与UDP比较Websocket数据结构栈栈的定义栈的特点栈的基本操作栈的应用场景队列队列的定义队列的使用方法链表单链表链表反转双链表单向循环链表数组python中list与数组比较字典实现原理哈希表Python常用模块subprocesssubprocess原理subprocess.Popen()subprocess.PIPE paramikoParamiko模块作用re常用正则表达式符号匹配时忽略大小写syssys基本方法ostimetime()模块中的重要函数**time()模块时间转换**datetime
python基础
python中的可变不可变类型
可变数据类型:列表、字典
不可变数据类型:数字、字符串、元组
数据类型
列表
append 用于在列表末尾追加新的对象
count 方法统计某个元素在列表中出现的次数
a = ['aa','bb','cc','aa','aa']
print(a.count('aa')) #the result : 3
extend方法可以在列表的末尾一次性追加另一个序列中的多个值
a = [1,2,3]
b = [4,5,6]
a.extend(b) #the result :[1, 2, 3, 4, 5, 6]
index 函数用于从列表中找出某个值第一个匹配项的索引位置
insert 方法用于将对象插入到列表中 结合下标使用
pop 方法会移除列表中的一个元素(默认是最后一个),并且返回该元素的值
remove 方法用于移除列表中某个值的第一个匹配项
a = ['aa','bb','cc','aa']
a.remove('aa') #the result : ['bb', 'cc', 'aa']
reverse 方法将列表中的元素反向存放
sort 方法用于对列表进行排序
enumrate 和for循环差不多 只是能获取下标的同时还能获取item
li = [11,22,33]
for k,v in enumerate(li, 1):
print(k,v)
#打印结果如下:
1 11
2 22
3 33
元祖
元祖和列表一样、只不过元祖是只读列表
列表和元组常用函数
com(x,y) 比较两个值
len(seq) 返回序列的长度
list(seq) 把序列转换成列表
max(args) 返回序列或者参数集合中得最大值
min(args) 返回序列或者参数集合中的最小值
reversed(seq) 对序列进行反向迭代
sorted(seq) 返回已经排列的包含seq 所有元素的列表
tuple(seq) 把序列转换成元组
字符串
使用百分号(%)字符串格式化
使用format字符串格式化
find方法可以在一个较长的字符串中查找子串,他返回子串所在位置的最左端索引,如果没有找到则返回-1
a = 'abcdefghijk'
print(a.find('abc')) #the result : 0
print(a.find('abc',10,100)) #the result : 11 指定查找的起始和结束查找位置
join方法 是非常重要的字符串方法,连接序列中的元素,并且需要被连接的元素都必须是字符串。
a = ['1','2','3']
print('+'.join(a)) # 1+2+3
split方法 是非常重要的字符串,用来将字符串分割成序列
print('1+2+3+4'.split('+')) # ['1', '2', '3', '4']
strip 方法返回去除首位空格(不包括内部)的字符串
print(" test test ".strip()) #“test test”
replace方法 返回某字符串所有匹配项均被替换之后得到字符串
print("This is a test".replace('is','is_test')) # This_test is_test a test
字典
clear方法清除字典中所有的项,这是一个原地操作,所以无返回值(或则说返回None)
d = {}
d['Tom']=8777
d['Jack']=9999
print(d) # {'Jack': 9999, 'Tom': 8777}
d.clear()
print(d) # {}
copy方法返回一个具有相同 ”键-值” 对的新字典,而不是副本
d = {'Tom':8777,'Fly':6666}
a = d.copy()
a['Tom'] = '改变后的值'
print(d) #{'Fly': 6666, 'Tom': 8777}
print(a) #{'Fly': 6666, 'Tom': '改变后的值'}
# 查看内存地址
d={'tom':122,'fly':221}
id(d)
1932459885696
a=d.copy()
a
{'tom': 122, 'fly': 221}
id(a)
1932488640048
fromkeys方法使用给定的键建立新的字典,每个键都对应一个默认的值None。
get方法是一个访问字典项的方法
for循环字典的三种方法
d = {'Tom':8777,'Jack':8888,'Fly':6666}
for k,v in d.items():
print(k,v)
for k in d.values():
print(k)
for k in d.keys():
print(k)
d = {'Tom':8777,'Jack':8888,'Fly':6666}
for k,v in d.items():
print(k,v)
for k in d.values():
print(k)
for k in d.keys():
print(k)
pop方法 用于获得对应与给定键的值,然后将这个”键-值”对从字典中移除
update方法可以利用一个字典项更新另一个字典,提供的字典中的项会被添加到旧的字典中
>>> a
{'tom': 122, 'fly': 221}
>>> b={'age':20}
>>> a.update(b)
>>> a
{'tom': 122, 'fly': 221, 'age': 20}
将两个列表组合成字典
keys = ['a', 'b']
values = [1, 2]
#1、zip生成字典
print(dict(zip(keys,values))) # {'a': 1, 'b': 2}
#2、for循环推倒字典
print({keys[i]: values[i] for i in range(len(keys))}) # {'a': 1, 'b': 2}
集合
list_1 = [1,2,3,4,5,1,2]
#1、去重(去除list_1中重复元素1,2)
list_1 = set(list_1) #去重: {1, 2, 3, 4, 5}
print(list_1)
list_2 = set([4,5,6,7,8])
#2、交集(在list_1和list_2中都有的元素4,5)
print(list_1.intersection(list_2)) #交集: {4, 5}
#3、并集(在list_1和list_2中的元素全部打印出来,重复元素仅打印一次)
print(list_1.union(list_2)) #并集: {1, 2, 3, 4, 5, 6, 7, 8}
#4、差集
print(list_1.difference(list_2)) #差集:在list_1中有在list_2中没有: {1, 2, 3}
print(list_2.difference(list_1)) #差集:在list_1中有在list_2中没有: {8, 6, 7}
#5、子集
print(list_1.issubset(list_2)) #子集: False List_1中的元素是否全部在list2中
#6、父集
print(list_1.issuperset(list_2)) #父集: False List_1中是否包含list_2中的所有元素
#7、交集
print(list_1 & list_2) #交集 {4, 5}
#8、union并集
print(list_1 | list_2) #并集: {1, 2, 3, 4, 5, 6, 7, 8}
#9、difference差集
print(list_1 - list_2) #差集: {1, 2, 3}
#10、在集合中添加一个元素999
list_1.add(999)
print(list_1) #Add()方法: {1, 2, 3, 4, 5, 999}
#11、删除集合中任意一个元素不会打印删除的值
list_1.pop() #Pop()方法: 无返回值
#12、discard删除集合中的指定元素,如过没有则返回None
print(list_1.discard("ddd")) #Discard()方法: 删除指定的值,没有返回None
字符编码
-
ASCII
ASCII不支持中文字符
-
GBK
是中国的中文字符(中国人自己研发的),其包含了简体中文和繁体中文的字符
-
Unicode : 万国编码(Unicode 包含GBK)
-
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码
-
规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536
-
这里还有个问题:使用的字节增加了,那么造成的直接影响就是使用的空间就直接翻倍了
-
-
Utf-8 : 可变长码, 是Unicode 的扩展集
-
UTF-8编码:是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类
-
ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存
-
python2和python3的区别
-
从编码的角度来说
python2 默认编码方式ASCII码(不能识别中文,要在文件头部加上 #-- encoding:utf-8 -- 指定编码方式)
python3 默认编码方式UTF-8(能识别中文,是Unicode 的扩展集)
(可识别中文)
-
从输出(print)的角度来说
python2中加不加括号都可以打印
python3中必须加括号
-
从输入(input)的角度来说
python2 raw_input()
python3 input()
-
从range()函数的角度来说
python2 range()/xrange()
python3 range()
-
从类的角度来说
python3 中都是新式类python2 中经典类和新式类混合
新式类中使用广度优先,经典类中使用深度优先
python3 可以使用superpython2 不能使用super
-
从字符串的角度来说
python2中字符串有str和unicode两种类型
python3 中字符串有str和字节(bytes) 两种类型
-
从语法格式角度来说
python3中不再支持u中文的语法格式
python2中支持
python2和python3中编码转换
-
在python3中字符串默认是unicode所以不需要decode(),直接encode(编码)成想要转换的编码如gb2312
-
在python2中默认是ASCII编码,必须先转换成Unicode,Unicode 可以作为各种编码的转换的中转站
深拷贝、浅拷贝
-
深拷贝就是将一个对象拷贝到另一个对象中,这意味着如果你对一个对象的拷贝做出改变时,不会影响原对象。在Python中,我们使用函数deepcopy()执行深拷贝
-
而浅拷贝则是将一个对象的引用拷贝到另一个对象上,所以如果我们在拷贝中改动,会影响到原对象。我们使用函数copy()执行浅拷贝
-
浅拷贝只是增加了一个指针指向一个存在的地址,
-
而深拷贝是增加一个指针并且开辟了新的内存,这个增加的指针指向这个新的内存。
三元运算
-
三元运算格式: result=值1 if x<y else 值2 if条件成立result=1,否则result=2
-
作用:三元运算,又称三目运算,主要作用是减少代码量,是对简单的条件语句的缩写
#一个简单的三元运算
a=name='小草' if1=1 else '小花'
print(a) # 小草
#三元运算 + lambda
f = lambda x:x if x % 2 != 0 else x + 100
print(f(10)) # 110
IO多路复用
select、poll 、epoll(同步io)
无论是sellect、poll、epoll他们三个都是在I/O多路复用中检测多个socket链接,与数据从内核态到数据态没有什么关系
https://www.cnblogs.com/xiaonq/p/7907871.html#i3
-
select,poll,epoll都是IO多路复用中的模型
-
内核空间 操作系统才能访问 操作系统 可以调用cpu 挂起进程
用户空间 如qq 微信 运行在用户空间
IO多路复用(重点)
特点: 用户还是要等待数据从内核拷贝到用户进程
Windows下只支持select
Epoll有回调 会把数据加到链表中
Select 不管你有没数据 都放到链表中
协程利用epoll greelit监听请求
协程又称微线程,协程最主要的作用是在类似单线程的条件下实现并发的效果,但实际上还是串行的(像yield一样),为什么能处理并发,因为遇IO自动切换,协程内封装Greenlet(遇到IO手动切换) 和Gevent(遇到IO自动切换),如果是耗时任务就会IO切换任务,会把任务交给操作系统,然后利用epoll,epoll有回调 会把数据加到链表中,告诉协程结果
协程一般用于网络请求 socket 链接
请求本身是从内核copy到用户空间
select (能监控数量有限(最大1024),不告诉用户程序具体哪个连接有数据)
poll(和select一样,仅仅去除了最大监控数量,算是epoll过度)
epoll (不仅没有最大监控数量限制,还能告诉用户程序哪个连接有活跃(数据))通常使用epoll
epoll() 中内核则维护一个链表,epoll_wait 直接检查链表是不是空就知道是否有文件描述符准备好了
在内核实现中 epoll 是根据每个 sockfd 上面的与设备驱动程序建立起来的回调函数实现的。
-
-
在高并发情况下, 连接活跃度不是很高, epoll比select好
-
在并发不高情况下, 连接活跃度高, select比epoll好
进程(资源分配的单位)、线程(操作系统调度的最小单位)、协程
线程是指进程内的一个执行单元,
# 进程
进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
# 线程
线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度
# 协程和线程
协程避免了无意义的调度,由此可以提高性能;但同时协程也失去了线程使用多CPU的能力
进程与线程的区别
(1)地址空间:线程是进程内的一个执行单位,进程内至少有一个线程,他们共享进程的地址空间,而进程有自己独立的地址空间
(2)资源拥有:进程是资源分配和拥有的单位,同一个进程内线程共享进程的资源
(3)线程是处理器调度的基本单位,但进程不是
(4)二者均可并发执行
(5)每个独立的线程有一个程序运行的入口
协程与线程
(1)一个线程可以有多个协程,一个进程也可以单独拥有多个协程,这样Python中则能使用多核CPU
(2)线程进程都是同步机制,而协程是异步
(3)协程能保留上一次调用时的状态
进程: 一个在运行起来的程序 系统给他分配资源 (运行在内存) 提资源
通信的三种方式
1 进程队列queue
2 管道pipe
3 共享数据manage
进程说明
多个进程可以在不同的 CPU 上运行,互不干扰
同一个CPU上,可以运行多个进程,由操作系统来自动分配时间片
进程池
开多进程是为了并发,通常有几个cpu核心就开几个进程,但是进程开多了会影响效率,主要体现在切换的开销,所以引入进程池限制进程的数量。
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
线程: 操作系统最小的调度单位,状态保存在cpu的栈中
常用方法
join()方法
实现所有线程都执行结束后再执行主线程
如果一个线程或者在函数执行的过程中调用另一个线程,并且希望待其完成操作后才能执行, 那么在 调用线程的时就可以使用被调线程的join方法join([timeout]) timeout:可选参数,线程运行的最长时间
isAlive()方法
查看线程是否还在运行
getName()方法
获得线程名
setDaemon()方法
主线程退出时,需要子线程随主线程退出,则设置子线程的setDaemon()
线程锁
线程锁也叫用户锁 也叫互斥锁、当前线程还未操作完成前其他所有线程都无法对其操作,即使已经释放了GIL锁
线程特性
线程,必须在一个存在的进程中启动运行
线程使用进程获得的系统资源,不会像进程那样需要申请CPU等资源
线程无法给予公平执行时间,它可以被其他线程抢占,而进程按照操作系统的设定分配执行时间
线程池
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互。在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
协程: 微线程,纤程。 类似于单线程,不同于单线程,因为它可以实现并发效果,因为有
gevent(封装了c语言的greenlet) 遇io自动切换(greenlet可以检测io),把这个io请求交给epoll
greenlet框架封装了yield语句、挂起函数,直到稍后使用next()或send()操作进行恢复为止
猴子补丁
用过gevent就会知道,会在最开头的地方gevent.monkey.patch_all();
作用是把标准库中的thread/socket等给替换掉.无需修改任何代码,把它变成了非阻塞
协程优点:
1.无需线程上下文切换的开销 2.无需原子操作锁定及同步的开销 3.方便切换控制流,简化编程模型 4.高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
1.无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能 运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应
2.线程阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
-
并行 :是多个程序运行在多个cpu上
-
并发 :是一个时间段内,有几个程序在同一个cpu上运行,但是任意时刻只有一个程序在cpu上运行
一般多线程可以称为并发 ,因为一个进程可以有多个线程,强调的是一个进程
-
详细介绍 https://v3u.cn/book/p4.html 1.5
高阶函数
1.map
一般情况map()函数接收两个参数,一个函数(该函数接收一个参数),一个序列,将传入的函数依次作用到序列的每个元素,并返回一个新的Iterator(迭代器)。 例如有这样一个list:['pYthon', 'jaVa', 'kOtlin'],现在要把list中每个元素首字母改为大写,其它的改为小写,可以这样操作:
>>> def f(s):
... return s.title()
...
>>> l = map(f, ['pYthon', 'jaVa', 'kOtlin'])
>>> list(l)
['Python', 'Java', 'Kotlin']
2.reduce
和map()用法类似,reduce把传入的函数作用在一个序列上,但传入的函数需要接收两个参数,传入函数的计算结果继续和序列的下一个元素做累积计算。
例如有一个list,里边的元素都是字符串,要把它拼接成一个字符串:
>>> from functools import reduce
>>> def f(x, y):
... return x + y
...
>>> reduce(f, ['ab', 'c', 'de', 'f'])
'abcdef'
3.filter
filter()同样接收一个函数和一个序列,然后把传入的函数依次作用于序列的每个元素,如果传入的函数返回true则保留元素,否则丢弃,最终返回一个Iterator。
例如一个list中元素有纯字母、纯数字、字母数字组合的,我们要保留纯字母的:
>>> def f(s):
... return s.isalpha()
...
>>> l = filter(f, ['abc', 'xyz', '123kg', '666'])
>>> list(l)
['abc', 'xyz']
4.sorted
sorted()函数就是用来排序的,同时可以自己定义排序的规则。
>>> sorted([6, -2, 4, -1])
[-2, -1, 4, 6]
>>> sorted([6, -2, 4, -1], key=abs)
[-1, -2, 4, 6]
>>> sorted([6, -2, 4, -1], key=abs, reverse=True)
[6, 4, -2, -1]
>>> sorted(['Windows', 'iOS', 'Android'])
['Android', 'Windows', 'iOS']
>>> d = [('Tom', 170), ('Jim', 175), ('Andy', 168), ('Bob', 185)]
>>> def by_height(t):
... return t[1]
...
>>> sorted(d, key=by_height)
[('Andy', 168), ('Tom', 170), ('Jim', 175), ('Bob', 185)]
5.lambda(匿名函数)
lambda只是一个表达式,函数体比def简单很多。
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
格式:lambda的一般形式是关键字lambda后面跟一个或多个参数,紧跟一个冒号,之后是一个表达式。
m=lambda i:i
lista=sorted([1,-2,3,-4,5,-6],key=abs)
print(lista) #结果: [1, -2, 3, -4, 5, -6]
# 利用 filter、lambda表达式 获取列表中元素小于33的所有元素
l1= [11,22,33,44,55]
a = filter(lambda x: x<33, l1)
print(list(a))
GIL全局解释器锁
1、什么是GIL
-
GIL全称Global Interpreter Lock,即全局解释器锁。 作用就是,限制多线程同时执行,保证同一时间内只有一个线程在执行。
-
GIL并不是Python的特性,Python完全可以不依赖于GIL。
2、GIL的作用
-
为了更有效的利用多核处理器的性能,就出现了多线程的编程方式 ,同一个进程里线程资源是共享的,当各个线程访问数据资源时会出现竞状态 ,会出现数据混乱,解决多线程之间数据完整性和状态同步最简单的方式就是加锁。GIL能限制多线程同时执行,保证同一时间内只有一个线程在执行。
3、GIL的影响
-
GIL无疑就是一把全局排他锁。毫无疑问全局锁的存在会对多线程的效率有不小影响。甚至就几乎等于Python是个单线程的程序。
4、如何避免GIL的影响
-
方法一:用进程+协程 代替 多线程的方式 在多进程中,由于每个进程都是独立的存在,所以每个进程内的线程都拥有独立的GIL锁,互不影响。但是,由于进程之间是独立的存在,所以进程间通信就需要通过队列的方式来实现。
-
方法二 : 更换解释器
像JPython和IronPython这样的解析器由于实现语言的特性,他们不需要GIL的帮助。然而由于用了Java/C#用于解析器实现,他们也失去了利用社区众多C语言模块有用特性的机会。所以这些解析器也因此一直都比较小众。
5 为什么有时候加了GIL全局解释器锁 ,还要在加线程锁?
因为cpu是分时分片的 ,如果GIL处理的任务特别繁琐,到一定时间会自动切换其他线程 造成混乱 ,所以要加一个线程锁。
线程锁
-
GIL(全局解释器锁)
GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念,是为了实现不同线程对共享资源访问的互斥,才引入了GIL
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
-
互斥锁(同步锁)
互斥锁是用来解决上述的io密集型场景产生的计算错误,即目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
-
死锁
保护不同的数据就应该加不同的锁。所以当有多个互斥锁存在的时候,可能会导致死锁(有可能是一个线程拿到锁,并没有释放)
-
递归锁(重要)
解决死锁
-
Semaphore(信号量)
实际上也是一种锁,该锁用于限制线程的并发量
装饰器、迭代器、生成器
迭代器 含有iter和next方法 (包含next方法的可迭代对象就是迭代器)
迭代器的定义:
迭代器是访问集合内元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素都被访问一遍后结束。 迭代器只能往前不会后退 。
可迭代对象
可被for循环遍历的对象都是可迭代的(Iterable)类型;
迭代器和可迭代对象关系:
一个实现了iter方法的对象是可迭代的,一个实现next方法的对象是迭代器
迭代器仅是一容器对象,它实现了迭代器协议。它有两个基本方法
㈠ next方法
返回容器的下一个元素
㈡ iter方法
返回迭代器自身
iter方法会返回一个迭代器(iterator),所谓的迭代器就是具有next方法的对象。
在调用next方法时,迭代器会返回它的下一个值,如果next方法被调用,但迭代器中没有值可以返就会引发一个StopIteration异常
生成器
包括含有yield这个关键字,生成器也是迭代器,调动next把函数变成迭代器
生成器工作原理
-
生成器是这样一个函数,它记住上一次返回时在函数体中的位置。
-
对生成器函数的第二次(或第 n 次)调用跳转至该函数中间,而上次调用的所有局部变量都保持不变。
yield运行机制
在Python中,yield就是一个生成器。 如果在函数内使用了yield关键字时,这个函数就是一个生成器
当你问生成器要一个数时,生成器会执行,直至出现 yield 语句,生成器把yield 的参数给你,之后生成器就不会往下继续运行。
当你问他要下一个数时,他会从上次的状态开始运行,直至出现yield语句,把参数给你,之后停下。如此反复
每当调用一次迭代器的next函数,生成器函数运行到yield之处,返回yield后面的值且在这个地方暂停,所有的状态都会被保持住,直到下次next函数被调用,或者碰到异常循环退出
手写斐波那契
def fbnq(n):
a,b=0,1
while n>a:
yield a
a,b=b,a+b
if __name__ == '__main__':
f=fbnq(9)
print(next(f)) #打印结果 0
print(next(f)) #打印结果 1
迭代器生成器区别
每次‘yield’暂停循环时,生成器会保存本地变量的状态。而迭代器并不会使用局部变量,它只需要一个可迭代对象进行迭代。 使用类可以实现你自己的迭代器,但无法实现生成器。 生成器运行速度快,语法简洁,更简单。 迭代器更能节约内存。
装饰器
装饰器作用:本质是函数(装饰其他函数)就是为其他函数添加其他功能
装饰器必须准寻得原则:
-
不能修改被装饰函数的源代码
-
不能修改被装饰函数的调用方式
手写三级装饰器
import time
user,passwd = 'aaa','123'
def auth(auth_type):
print("auth func:",auth_type)
def outer_wrapper(func):
def wrapper(*args, **kwargs):
print("wrapper func args:", *args, **kwargs)
if auth_type == "local":
username = input("Username:").strip()
password = input("Password:").strip()
if user == username and passwd == password:
print("�33[32;1mUser has passed authentication�33[0m")
res = func(*args, **kwargs) # from home
print("---after authenticaion ")
return res
else:
exit("�33[31;1mInvalid username or password�33[0m")
elif auth_type == "ldap":
print("搞毛线ldap,不会。。。。")
return wrapper
return outer_wrapper
def index():
print("welcome to index page")
@auth(auth_type="local") # home = wrapper()
def home():
print("welcome to home page")
return "from home"
@auth(auth_type="ldap")
def bbs():
print("welcome to bbs page")
index()
print(home()) #wrapper()
bbs()
装饰器的应用场景
1,引入日志2,函数执行时间统计3,执行函数前预备处理4,执行函数后清理功能5,权限校验等场景6,缓存7,事务处理
闭包
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用,这样就构成了一个闭包
但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
闭包特点
-
必须有一个内嵌函数
-
内嵌函数必须引用外部函数中的变量
-
外部函数的返回值必须是内嵌函数
os和sys模块的作用?
OS模块是Python标准库中的一个用于访问操作系统功能的模块,使用OS模块中提供的接口,可以实现跨平台访问sys模块主要是用于提供对python解释器相关的操作
面向对象
面向对象方法
静态方法
作用:静态方法可以更好的组织代码,防止代码变大后变得比较混乱。
特性: 静态方法只是名义上归类管理,实际上在静态方法里访问不了类或则实例中的任何属性
静态方法使用场景: 经常有一些跟类有关系的功能但在运行时又不需要实例和类参与的情况下 需要用到静态方法. 比如更改环境变量或者修改其他类的属性等能用到静态方法. 这种情况可以直接用函数解决, 但这样同样会扩散类内部的代码,造成维护困难.
调用方式: 既可以被类直接调用,也可以通过实例调用
class Dog(object):
def __init__(self,name):
self.name = name
@staticmethod
def eat():
print("I am a static method")
d = Dog("ChenRonghua")
d.eat() #方法1:使用实例调用
Dog.eat() #方法2:使用类直接调用
类方法
作用:无需实例化直接被类调用
特性: 类方法只能访问类变量,不能访问实例变量
类方法使用场景: 当我们还未创建实例,但是需要调用类中的方法
调用方式: 既可以被类直接调用,也可以通过实例调用
class Dog(object):
name = '类变量' #在这里如果不定义类变量仅定义实例变量依然报错
def __init__(self,name):
self.name = '实例变量'
self.name = name
@classmethod
def eat(self,food):
print("%s is eating %s"%(self.name,food))
Dog.eat('baozi') #方法1:使用类直接调用
d = Dog("ChenRonghua")
d.eat("包子") #方法2:使用实例d调用
属性方法
作用:属性方法把一个方法变成一个属性,隐藏了实现细节,调用时不必加括号直接d.eat即可调用self.eat()方法
class Dog(object):
def __init__(self, name):
self.name = name
@property
def eat(self):
print(" %s is eating" % self.name)
d = Dog("ChenRonghua")
d.eat()
# 调用会出以下错误, 说NoneType is not callable, 因为eat此时已经变成一个静态属性了,
# 不是方法了, 想调用已经不需要加()号了,直接d.eat就可以了
特殊(魔术)方法
__ doc __ 表示类的描述信息
__ call __ 对象后面加括号,触发执行
__ str __ 如果一个类中定义了__ str __方法,在打印对象时,默认输出该方法的返回值
__ dict __ 查看类或对象中的所有成员
new和init的区别
1、 new是一个静态方法,而init是一个实例方法. 2、 new方法会返回一个创建的实例,而init什么都不返回. 3、 只有在new返回一个cls的实例时后面的init才能被调用. 4、 当创建一个新实例时调用new,初始化一个实例时用init.
单例模式
1、单例模式:永远用一个对象得实例,避免新建太多实例浪费资源2、实质:使用new方法新建类对象时先判断是否已经建立过,如果建过就使用已有的对象3、使用场景:如果每个对象内部封装的值都相同就可以用单例模式
class Foo(object):
instance = None
def __init__(self):
self.name = 'alex'
def __new__(cls, *args, **kwargs):
if Foo.instance:
return Foo.instance
else:
Foo.instance = object.__new__(cls,*args,**kwargs)
return Foo.instance
obj1 = Foo() # obj1和obj2获取的就是__new__方法返回的内容
obj2 = Foo()
print(obj1,obj2)
# 运行结果: <__main__.Foo object at 0x00D3B450> <__main__.Foo object at 0x00D3B450>
# 运行结果说明:
# 这可以看到我们新建的两个Foo()对象内存地址相同,说明使用的•同一个类,没有重复建立类
面向对象属性
class Role(object): #1、在定义类时继承object就是新式类,没有就是就是旧类式
public_object = "public" #2、在类例定义一个公有属性:所有实例都能访问的属性叫“公有属性”
def __init__(self,name,role,weapon,life_value=100,money=15000): #构造函数==初始化方法:模板
self.name = name #3、普通属性
self.__heart= "Normal" #4、私有属性在外面无法访问,在名字前加__(双下划线) 外部无法访问
def shot(self): #5、类的方法
print("%s is shooting..."%self.name)
公有属性
公有属性:在内存中仅存一份
普通属性
普通属性:每个实例对象在内存存一份
私有属性
私有属性:实例在外部无法调用
反射
-
反射的核心本质就是以字符串的形式去导入个模块,利用字符串的形式去执行函数。
Django中的 CBV就是基于反射实现的。
新式类和经典类的区别
❶经典类 没有继承object , 新式类 继承了object
❷多继承中,新式类采用广度优先搜索,而旧式类是采用深度优先搜索,python3中全是广度查询
❸在继承中新式类和经典类写法区别
SchoolMember.__init__(self,name,age,sex) #经典类写法 super(Teacher,self).__init__(name,age,sex) #新式类写法
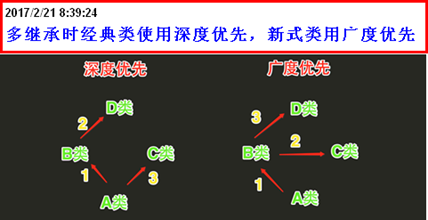
面向对象深度优先和广度优先是什么?
1、区别
-
1) 二叉树的深度优先遍历的非递归的通用做法是采用栈,广度优先遍历的非递归的通用做法是采用队列。
-
2) 深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历。具体说明如下:
-
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。
三大特性:封装,继承,多态
Encapsulation 封装(隐藏实现细节)
在面向对象思想中,对一个类,将数据和过程封包围起来,对外隐藏具体的实现细节 并且数据(成员变量和成员函数)在内部是完全自由使用的,而外部对数据的访问是加访问限定的,某些对操作只能根据由内部提供接口。
Inheritance 继承(代码重用)
继承可以说是一种代码复用的手段,我们在一个现有类上想扩展出一些东西的时候,不需要再次重复编写上面的代码,而是采用一种继承的思想。在派生出的子类里添加一些我们想要的数据或方法,也可以理解为从一般到特殊的过程。
Polymorphism 多态(接口重用)
这里先说运行时多态,其实是指在继承体系中父类的一个接口(必须为虚函数),在子类中有多种不同的实现,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。即通过父类指针或者引用可以访问到子类的接口(虚函数),看上去就像是一个相同的动作,会出现多种不同的结果。
垃圾回收机制
1.引用计数
原理
-
当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1
-
当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
优点
-
引用计数有一个很大的优点,即实时性,任何内存,一旦没有指向它的引用,就会被立即回收,而其他的垃圾收集技术必须在某种特殊条件下才能进行无效内存的回收。
缺点
-
引用计数机制所带来的维护引用计数的额外操作与Python运行中所进行的内存分配和释放,引用赋值的次数是成正比的,
-
这显然比其它那些垃圾收集技术所带来的额外操作只是与待回收的内存数量有关的效率要低。
-
同时,因为对象之间相互引用,每个对象的引用都不会为0,所以这些对象所占用的内存始终都不会被释放掉。
为了解决以上问题:
2.标记-清除
-
标记-清除: 只关注那些可能会产生循环引用的对象,
-
把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放
缺点:标记和清除的过程效率不高
原理
-
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点
-
以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放
3.分代回收
-
将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,垃圾收集的频率随着“代”的存活时间的增大而减小。
-
也就是说,活得越长的对象,就越不可能是垃圾,就应该减少对它的垃圾收集频率。
-
那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。
三种读文件方式
1.readline()
readline()每次读取一行,当前位置移到下一行readline()作用:readline 的用法,速度是fileinput的3倍左右,每秒3-4万行,好处是 一行行读 ,不占内存,适合处理比较大的文件,比如超过内存大小的文件
#readline读取大文件#
f1 = open('test02.py','r')
f2 = open('test.txt','w')
while True:
line = f1.readline()
if not line:
break
f2.write(line)
f1.close()
f2.close()
2.readlines()
readlines()读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素readlines()作用:readlines会把文件都读入内存,速度大大增加,但是没有这么大内存,那就只能乖乖的用readline
#readlines读文件#
f1=open("readline.txt","r")
for line in f1.readlines():
print(line)
3.read(size)
read(size)从文件当前位置起读取size个字节,如果不加size会默认一次性读取整个文件(适用于读取小文件)read(n)读取指定长度的文件
f = open(r"somefile.txt")
print(f.read(7)) # Welcome 先读出 7 个字符
print(f.read(4)) #‘ to ‘ 接着上次读出 4 个字符
f.close()
seek(offset[, whence]) 随机访问 :从文件指定位置读取或写入
f = open(r"somefile.txt", "w")
f.write("01234567890123456789")
f.seek(5)
f.write("Hello, World!")
f.close()
f = open(r"somefile.txt")
print(f.read()) # 01234Hello, World!89
tell 返回当前读取到文件的位置下标
tcp udp
tcp
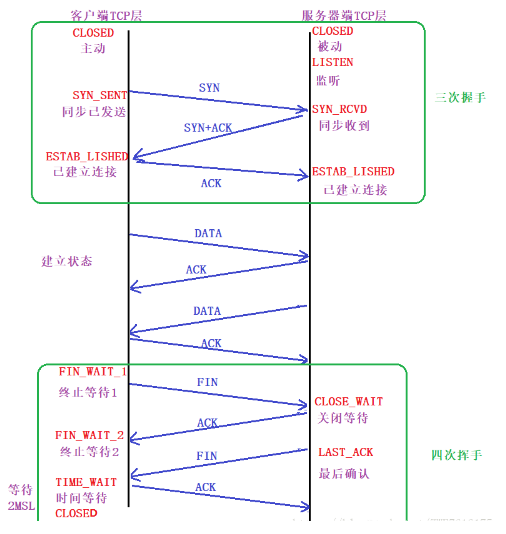
三次握手
####1、第一次握手 # 建立连接时,客户端发送SYN包到服务器,其中包含客户端的初始序号seq=x,并进入SYN_SENT状态,等待服务器确认。 ####2、第二次握手 # 服务器收到请求后,必须确认客户的数据包。同时自己也发送一个SYN包,即SYN+ACK包,此时服务器进入SYN_RECV状态。 ####3、第三次握手 # 客户端收到服务器的SYN+ACK包,向服务器发送一个序列号(seq=x+1),确认号为ack(客户端)=y+1,此包发送完毕, # 客户端和服务器进入ESTAB_LISHED(TCP连接成功)状态,完成三次握手。

四次挥手
#### 1、第一次挥手 # 首先,客户端发送一个FIN,用来关闭客户端到服务器的数据传送,然后等待服务器的确认。其中终止标志位FIN=1,序列号seq=u。 #### 2、第二次挥手 # 服务器收到这个FIN,它发送一个ACK,确认ack为收到的序号加一。 #### 3、第三次挥手 # 关闭服务器到客户端的连接,发送一个FIN给客户端。 #### 4、第四次挥手 # 客户端收到FIN后,并发回一个ACK报文确认,并将确认序号seq设置为收到序号加一。 # 首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
TCP与UDP比较
-
TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
-
TCP提供可靠的服务,也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达; UDP尽最大努力交付,即不保证可靠交付
-
Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。
-
UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
-
每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
-
TCP对系统资源要求较多,UDP对系统资源要求较少。
注:UDP一般用于即时通信(QQ聊天 对数据准确性和丢包要求比较低,但速度必须快),在线视频等
tcp/udp相关协议
-
TCP: STMP, TELNET, HTTP, FTP
2.UDP: DNS,TFTP,RIP,DHCP,SNMP
Websocket
1.是一种在单个TCP连接上进行 全双工通信(又称为双向同时通信,即通信的双方可以同时发送和接收信 息的信息交互方式。)的协议。
2.WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
数据结构
栈
栈的定义
栈是一种数据集合,可以理解为只能在一端进行插入或删除操作的列表
栈的特点
后进先出 栈有栈顶和栈底
栈的基本操作
进栈(压栈):push
出栈:pop
取栈顶:gettop
栈的应用场景
匹配括号是否成对出现
def check_kuohao(s):
stack = []
for char in s:
if char in ['(','[','{']:
stack.append(char)
elif char == ')':
if len(stack)>0 and stack[-1] == '(':
stack.pop()
else:
return False
elif char == ']':
if len(stack) > 0 and stack[-1] == '[':
stack.pop()
else:
return False
elif char == '}':
if len(stack) > 0 and stack[-1] == '{':
stack.pop()
else:
return False
if len(stack) == 0:
return True
else:
return False
print(check_kuohao('(){}{}[]')) #True
队列
队列的定义
-
队列是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除
-
插入的一端称为队尾(rear),插入动作叫进队或入队
-
进行删除的一端称为对头(front),删除动作称为出队
-
队列性质:先进先出(First-in, First-out)
-
双向队列:队列的两端都允许进行进队和出队操作
队列的使用方法
-
导入: from collectios import deque
-
创建队列:queue = deque(li)
-
进队: append
-
出队: popleft
-
双向队列队首进队:appendleft
-
双向队列队尾出队:pop
链表
单链表
链表中每个元素都是一个对象,每个对象称为一个节点,包含有数据域key和指向下一节点的指针next,通过各个节点间的相互连接,最终串联成一个链表

单链表第一个节点没有前驱,最后一个节点没有后继。
链表反转
class Node(object):
def __init__(self, val):
self.val = val
self.next = None
def list_reverse(head):
if head == None:
return None
L, R, cur = None, None, head # 左指针、有指针、游标
while cur.next != None:
L = R # 左侧指针指向以前右侧指针位置
R = cur # 右侧指针前进一位指向当前游标位置
cur = cur.next # 游标每次向前进一位
R.next = L # 右侧指针指向左侧实现反转
cur.next = R # 当跳出 while 循环时 cur(原链表最后一个元素) R(原链表倒数第二个元素)
return cur
if __name__ == '__main__':
'''
原始链表:1 -> 2 -> 3 -> 4
反转链表:4 -> 3 -> 2 -> 1
'''
l1 = Node(1)
l1.next = Node(2)
l1.next.next = Node(3)
l1.next.next.next = Node(4)
l = list_reverse(l1)
print l.val # 4 反转后链表第一个值4
print l.next.val # 3 第二个值3
双链表
双链表中每个节点有两个指针:一个指针指向后面节点、一个指向前面节点

单向循环链表
本质和单向联链表一样,但循环链表的最后一个结点的指针是指向该循环链表的第一个结点或者表头结点,从而构成一个环形的链。
数组
数组的定义
-
所谓数组,就是相同数据类型的元素按一定顺序排列的集合
-
在Java等其他语言中并不是所有的数据都能存储到数组中,只有相同类型的数据才可以一起存储到数组中。
-
因为数组在存储数据时是按顺序存储的,存储数据的内存也是连续的,所以他的特点就是寻址读取数据比较容易,插入和删除比较困难。
python中list与数组比较
-
python中的list是python的内置数据类型,list中的数据类不必相同的,而array的中的类型必须全部相同。
-
在list中的数据类型保存的是数据的存放的地址,简单的说就是指针,并非数据
-
这样保存一个list就太麻烦了,例如list1=[1,2,3,'a']需要4个指针和四个数据,增加了存储和消耗cpu。
字典实现原理
哈希表
-
哈希表(也叫散列表),根据关键值对(Key-value)而直接进行访问的数据结构。
它通过把key和value映射到表中一个位置来访问记录,这种查询速度非常快,更新也快。
-
而这个映射函数叫做哈希函数,存放值的数组叫做哈希表
Python常用模块
https://www.cnblogs.com/xiaonq/p/7866925.html#i11
subprocess
subprocess原理
-
运行python的时候,我们都是在创建并运行一个进程。像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序
-
在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序。
-
subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用
-
另外subprocess还提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而在进程间使用文本通信。
subprocess.Popen()
Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block)
subprocess.PIPE
将多个子进程的输入和输出连接在一起
subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走
paramiko
Paramiko模块作用
-
如果需要使用SSH从一个平台连接到另外一个平台,进行一系列的操作时,
比如:批量执行命令,批量上传文件等操作,paramiko是最佳工具之一。
-
paramiko是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接
-
支持多平台 如Linux, Solaris, BSD,MacOS X, Windows等
re
常用正则表达式符号
通配符 ●
作用:● 可以匹配除换行符以外的任意一个字符串
转义字符 ╲
作用:可以将其他有特殊意义的字符串以原本意思表示
注:如果想对反斜线()自身转义可以使用双反斜线()这样就表示’’
字符集
作用:使用中括号来括住字符串来创建字符集,字符集可匹配他包括的任意字串
①‘[pj]ython’ 只能够匹配‘python’ ‘jython’
② [a-z] 能够(按字母顺序)匹配a-z任意一个字符
③ [a-zA-Z0-9] 能匹配任意一个大小写字母和数字
④ ^abc 可以匹配任意除a,b和c 之外的字符串
管道符
作用:一次性匹配多个字符串
例如:’python|perl’ 可以匹配字符串‘python’ 和 ‘perl’
.最常用的匹配方法
d 匹配任何十进制数;它相当于类 [0-9]。 D 匹配任何非数字字符;它相当于类 0-9。 s 匹配任何空白字符;它相当于类 [ fv]。 S 匹配任何非空白字符;它相当于类 fv。 w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 W 匹配任何非字母数字字符;它相当于类 a-zA-Z0-9_。
w* 匹配所有字母字符
w+ 至少匹配一个字符
匹配时忽略大小写
import re
#匹配时忽略大小写
print(re.search("[a-z]+","abcdA").group()) #abcd
print(re.search("[a-z]+","abcdA",flags=re.I).group()) #abcdA
sys
sys基本方法
sys.argv 返回执行脚本传入的参数
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
os
import os
# 当前工作目录,即当前python脚本工作的目录路径
print(os.getcwd()) # C:UsersadminPycharmProjectss14Day5 est4
# 当前脚本工作目录;相当于shell下cd
os.chdir("C:\Users\admin\PycharmProjects\s14")
os.chdir(r"C:UsersadminPycharmProjectss14")
print(os.getcwd()) # C:UsersadminPycharmProjectss14
# 返回当前目录: ('.')
print(os.curdir) # ('.')
#4 获取当前目录的父目录字符串名:('..')
print(os.pardir) # ('..')
# 可生成多层递归目录
os.makedirs(r'C:aaabb') # 可以发现在C盘创建了文件夹/aaa/bbb
# 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.removedirs(r'C:aaabb') # 删除所有空目录
# 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.rmdir(r'C:aaa') # 仅删除指定的一个空目录
# 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
print(os.listdir(r"C:UsersadminPycharmProjectss14"))
# 删除一个文件
os.remove(r'C:bb est.txt') # 指定删除test.txt文件
# 重命名文件/目录
os.rename(r'C:bb est.txt',r'C:bb est00.bak')
# 获取文件/目录信息
print(os.stat(r'C:bb est.txt'))
# 运行shell命令,直接显示
os.system("bash command")
# 获取系统环境变量
print(os.environ) # environ({'OS': 'Windows_NT', 'PUBLIC': ………….
# 返回path规范化的绝对路径
print(os.path.abspath(r'C:/bbb/test.txt')) # C:bb est.txt
# 将path分割成目录和文件名二元组返回
print(os.path.split(r'C:/bbb/ccc')) # ('C:/bbb', 'ccc')
# 无论linux还是windows,拼接出文件路径
put_filename = '%s%s%s'%(self.home,os. path.sep, filename)
#C:UsersadminPycharmProjectss14day10select版FTPhome
time
time()模块中的重要函数**
| 函数 | 描述 |
|---|---|
| asctime([tuple]) | 将时间元组转换为字符串 |
| localtime([secs]) | 将秒数转换为日期元组(转换成本国时区 |
| mktime(tuple) | 将时间元组转换为本地时间 |
| time() | 获取当前时间戳 |
time()模块时间转换**
-
时间戳 1970年1月1日之后的秒, 即:time.time()
-
格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
-
结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
datetime
import datetime
#1、datetime.datetime获取当前时间
print(datetime.datetime.now())
#2、获取三天后的时间
print(datetime.datetime.now()+datetime.timedelta(+3))
#3、获取三天前的时间
print(datetime.datetime.now()+datetime.timedelta(-3))
#4、获取三个小时后的时间
print(datetime.datetime.now()+datetime.timedelta(hours=3))
#5、获取三分钟以前的时间
print(datetime.datetime.now()+datetime.timedelta(minutes = -3))
import datetime
print(datetime.datetime.now())
print(datetime.datetime.now().date())
print(datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S"))