存储介质
数据库采用多级存储器,用的最多的辅存是磁盘。磁盘的耗时主要在寻道时间。
磁盘上数据划分为大小相等的物理块,磁盘与内存间的数据交换以物理块为单位。好处:
- 减少IO次数
- 减少间隙的数目,提高磁盘空间利用率
为了解决磁盘和内存之间速度不匹配,可设立缓冲区:
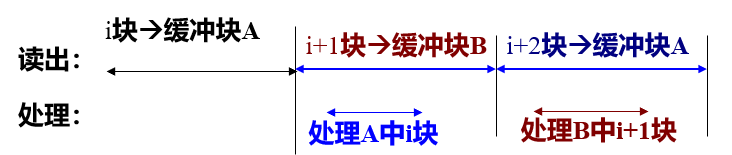
DBMS可以采用延迟写(一系列写入一起进行)与提前读(正在处理i位置时提前调入i+1位置)技术,减少I/O,改善性能。
记录的存储结构
记录
- 定位法:每个字段按最大可能长度分配定长
- 相对法:每个字段没有固定的长度,而用特殊的字符分隔
- 计数法:每个字段的开始加上该字段长度信息
记录到物理块
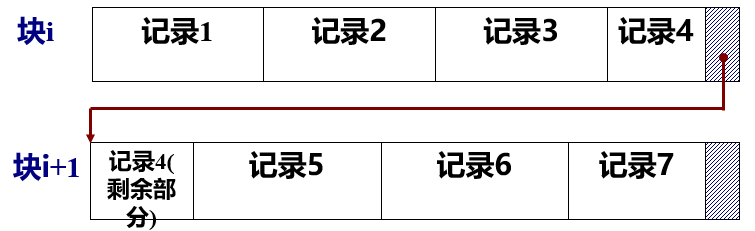
每个物理块可容纳记录数(块因子)p=[B/R],B:物理块大小,R:固定长记录的大小
通常,B=pR<R,即物理块会留出零头。为了利用这一部分,可以采用跨块组织。
物理块到磁盘
- 连续分配法:有利于顺序存取,不利于扩充
- 链接分配法:各物理块用指针连接,有利于扩充,效率较差
- 簇集分配法:结合上述两种方法,将一系列物理块串在一起,入口放在某地址
- 索引分配法:每个文件有一个逻辑块号与其物理块地址对照的索引条目
数据压缩
-
消零或空格符法:例如00000用@5表示
-
串型代替法:用某个约定的短串代替长串数据
-
索引法:在用到这些串的地方,用指针引用索引表中的条目
文件结构和存取路径
访问文件的方式
对数据库的操作最终要落实到对文件的操作。
数据库对文件的要求
更多的DBMS不用OS的文件管理系统,而是独立设计其存储结构。因为:
- 传统文件系统不能提供DBMS功能所需的附加信息
- 传统文件系统主要面向批处理,数据库系统要求即时访问、动态修改
- 减少DBMS对OS的依赖,提高DBMS的可移植性
文件的基本类型
-
堆文件
按照插入先后顺序存放。
插入容易,查找不方便(只能顺序搜索),删除记录也较麻烦(需要空间回收)。
-
直接文件
记录的某一属性用散列函数直接映射成记录的地址。
散列函数的设计较为困难;地址范围设的太大或太小都不好;要处理地址重叠问题。

-
索引文件
建立一个集中的映射机构,保存某些属性的值(如主键)与存储地址的映射。

索引与散列的区别:索引文件有记录才占用空间,散列空文件也占用全部空间(因为必须留出整个空间)。
针对非散列键和非索引属性的访问,都不能有效发挥直接文件或索引文件的优势。散列或索引失效时,散列的访问代价通常更大,因为需要遍历整个散列空间,而索引的条数较少。
索引的建立与使用
-
键值:索引键属性的可能取值
-
主索引:索引是主键 —— 一个索引只有一个地址对应
- 非稠密索引:按主键排序
- 稠密索引:不按主键排序
-
次索引:索引不是主键 —— 一个索引可能有多个地址对应
- 簇集索引:按索引键排序并簇集,是稠密索引
- 非簇集索引:不按索引键排序,是稠密索引,也叫无序索引、非簇集的稠密次索引、二次索引
-
稠密索引:每个键值对应一个索引项。每增加一个键值,就要增加一个索引项,索引会有溢出的可能。
-
非稠密索引:不为每个键值设立索引项。可以节省索引的存储空间,代价是文件要按索引键排序。对一个文件,只能为一个索引键(一般为主键)建立非稠密索引。
-
簇集索引:在稠密索引中,若键值不唯一,则每个键值可能对应多个记录,这时可以在索引区进行拉链簇集,把键值相同的记录在物理地址上集中存放

动态索引
动态索引是一种平衡多分树(即B-树),常用B+树。
- 每个节点最多有2k个键值,k称为B+树的秩
- 根节点至少有一个键值,其它节点至少有k个键值。节点内,键值有序存放
- 除叶节点外,其它节点若有J个键值,则有J+1个子女
- 叶节点都处于树的同一层
用B+树实现主索引
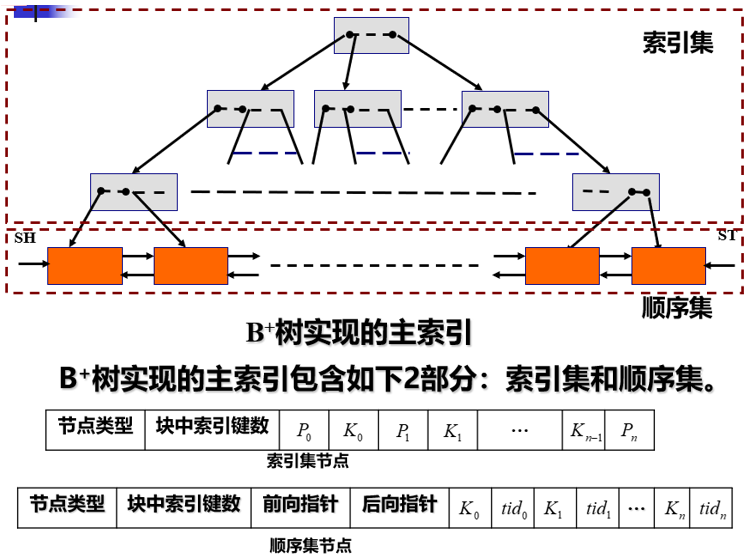
要找键值Kx所对应的记录时,从索引树的根开始,按照大小夹逼原理,自上而下地搜索。即:若Kx<K0,则沿P0所指的节点向下搜索;若Kx>Kn-1,则沿Pn所指的节点向下搜索;若Ki-1<Kx≤Ki,则沿Pi所指的节点向下搜索。
索引集节点中的键值不一定是文件中当前存在的键值(仅起“导航路标”的作用)。在搜索过程中,即使发现索引集节点中的键值等于要找的键值,查找仍要按上述规则进行下去。
B+树提供的存取路径
-
通过索引集进行树形搜索
-
通过顺序集进行顺序搜索
-
先通过索引找到入口,再沿顺序集顺序搜索
效率
搜索B+树所需的I/O次数决定于其级数L,最多经过L次I/O就可以搜索到,而B+树的级数决定于N(索引属性不同键值的数目),而不是记录数。

补充知识
到底什么是稠密索引和非稠密索引
稠密索引每个数据记录的键值对应一个索引项。也就是说,稠密索引为数据记录文件的每一条记录都设一个键-指针对。
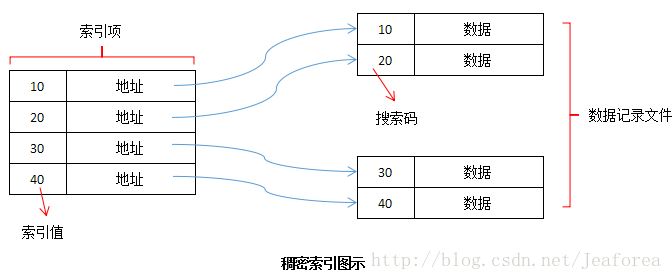
非稠密索引不为每个数据记录的键值设立索引项。也就是说,为数据记录文件的每个存储块设一个键-指针对。
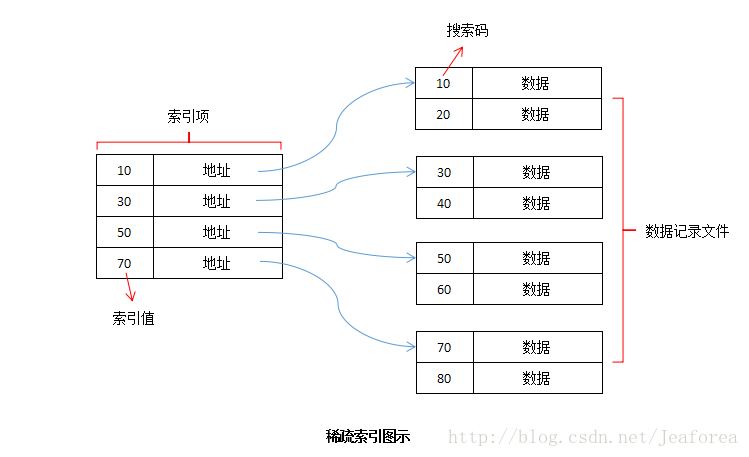
到底什么是主索引和次索引
-
主索引:索引是主键 —— 一个索引只有一个地址对应(如上图所示)
- 非稠密索引:按主键排序
- 稠密索引:不按主键排序
-
次索引:索引不是主键 —— 一个索引可能有多个地址对应(上图地址部分为一个地址列表)
因为不按主键排序,所以必然是稠密索引
- 簇集索引:按索引键排序并簇集(地址列表拉链)
- 非簇集索引:不按索引键排序,也叫无序索引、非簇集的稠密次索引、二次索引