Deployment
简述
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的 ReplicationController 来方便的管理应用。
Deployment 概念解析
Deployment 是什么?
Deployment 为 Pod 和 Replica Set(下一代 Replication Controller)提供声明式更新。
你只需要在 Deployment 中描述你想要的目标状态是什么,Deployment controller 就会帮你将 Pod 和 Replica Set 的实际状态改变到你的目标状态。你可以定义一个全新的 Deployment,也可以创建一个新的替换旧的 Deployment。
一个典型的用例如下:
使用 Deployment 来创建 ReplicaSet。ReplicaSet 在后台创建 pod。检查启动状态,看它是成功还是失败。
然后,通过更新 Deployment 的 PodTemplateSpec 字段来声明 Pod 的新状态。这会创建一个新的 ReplicaSet,Deployment 会按照控制的速率将 pod 从旧的 ReplicaSet 移动到新的 ReplicaSet 中。
如果当前状态不稳定,回滚到之前的 Deployment revision。每次回滚都会更新 Deployment 的 revision。
扩容 Deployment 以满足更高的负载。
暂停 Deployment 来应用 PodTemplateSpec 的多个修复,然后恢复上线。
根据 Deployment 的状态判断上线是否 hang 住了。
清除旧的不必要的 ReplicaSet。
ReplicaSet
ReplicaSet的目的是在任何给定时间维护一组稳定的副本Pod。因此,它通常用于保证指定数量的相同Pod的可用性。
ReplicaSet的工作原理 ReplicaSet是使用字段定义的,包括指定如何识别它可以获取的Pod的选择器,指示它应该维护多少Pod的多个副本,以及一个pod模板,用于指定它应该创建的新Pod的数据以满足该数量复制品标准。然后,ReplicaSet通过根据需要创建和删除Pod来达到其目的,以达到所需的数量。当ReplicaSet需要创建新Pod时,它使用其Pod模板。 ReplicaSet与其Pods的链接是通过Pods的metadata.ownerReferences 字段,该字段指定当前对象所拥有的资源。ReplicaSet获取的所有Pod在其ownerReferences字段中拥有其拥有的ReplicaSet标识信息。通过此链接,ReplicaSet知道它正在维护的Pod的状态并相应地进行计划。 ReplicaSet使用其选择器标识要获取的新Pod。如果Pod没有OwnerReference或者OwnerReference不是控制器并且它与ReplicaSet的选择器匹配,则它将立即由所述ReplicaSet获取。 何时使用ReplicaSet ReplicaSet确保在任何给定时间运行指定数量的pod副本。但是,部署是一个更高级别的概念,它管理ReplicaSet并为Pod提供声明性更新以及许多其他有用的功能。因此,除非您需要自定义更新编排或根本不需要更新,否则我们建议使用部署而不是直接使用ReplicaSet。 这实际上意味着您可能永远不需要操作ReplicaSet对象:改为使用Deployment,并在spec部分中定义您的应用程序。
DaemonSet
aemonSet 保证在每个 Node 上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括: 日志收集,比如 fluentd,logstash 等 系统监控,比如 Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond 等 系统程序,比如 kube-proxy, kube-dns, glusterd, ceph 等
Job
Job 类型
Kubernetes 支持以下几种 Job:
- 非并行 Job:通常创建一个 Pod 直至其成功结束
- 固定结束次数的 Job:设置
.spec.completions,创建多个 Pod,直到.spec.completions个 Pod 成功结束 - 带有工作队列的并行 Job:设置
.spec.Parallelism但不设置.spec.completions,当所有 Pod 结束并且至少一个成功时,Job 就认为是成功
根据 .spec.completions 和 .spec.Parallelism 的设置,可以将 Job 划分为以下几种 pattern:
| Job 类型 | 使用示例 | 行为 | completions | Parallelism |
|---|---|---|---|---|
| 一次性 Job | 数据库迁移 | 创建一个 Pod 直至其成功结束 | 1 | 1 |
| 固定结束次数的 Job | 处理工作队列的 Pod | 依次创建一个 Pod 运行直至 completions 个成功结束 | 2+ | 1 |
| 固定结束次数的并行 Job | 多个 Pod 同时处理工作队列 | 依次创建多个 Pod 运行直至 completions 个成功结束 | 2+ | 2+ |
| 并行 Job | 多个 Pod 同时处理工作队列 | 创建一个或多个 Pod 直至有一个成功结束 | 1 | 2+ |
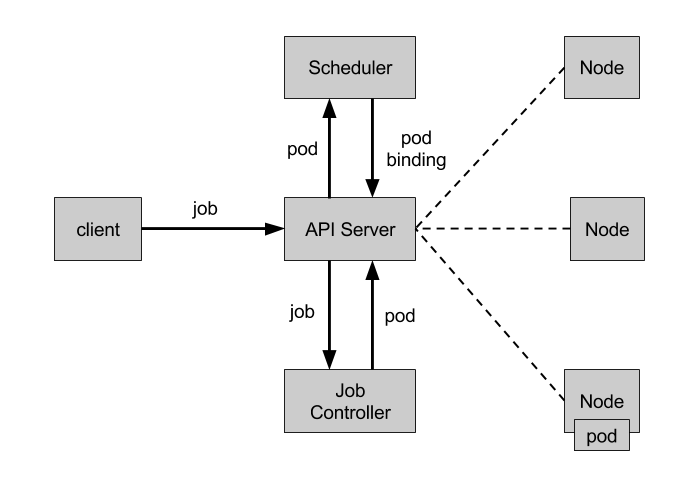
Job Controller
Job Controller 负责根据 Job Spec 创建 Pod,并持续监控 Pod 的状态,直至其成功结束。如果失败,则根据 restartPolicy(只支持 OnFailure 和 Never,不支持 Always)决定是否创建新的 Pod 再次重试任务。
StatefulSet
StatefulSet 是为了解决有状态服务的问题(对应 Deployments 和 ReplicaSets 是为无状态服务而设计),其应用场景包括 稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现 稳定的网络标志,即 Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)来实现 有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依序进行(即从 0 到 N-1,在下一个 Pod 运行之前所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现 有序收缩,有序删除(即从 N-1 到 0) 从上面的应用场景可以发现,StatefulSet 由以下几个部分组成: 用于定义网络标志(DNS domain)的 Headless Service 用于创建 PersistentVolumes 的 volumeClaimTemplates 定义具体应用的 StatefulSet