参考:https://github.com/Lockvictor/MovieLens-RecSys/blob/master/usercf.py#L169
数据集
本文使用了MovieLens中的ml-100k小数据集,数据集的地址为:传送门
该数据集中包含了943个独立用户对1682部电影做的10000次评分。
完整代码
总体和UserCF差不多,将用户相似度的计算改为物品相似度的计算即可。
1 import numpy as np 2 import pandas as pd 3 import math 4 from collections import defaultdict 5 from operator import itemgetter 6 7 np.random.seed(1) 8 9 10 class ItemCF(object): 11 12 def __init__(self): 13 self.train_set = {} 14 self.test_set = {} 15 self.movie_popularity = {} 16 17 self.tot_movie = 0 18 self.W = {} # 相似度矩阵 19 20 self.K = 160 # 最接近的K部电影 21 self.M = 10 # 推荐电影数 22 23 def split_data(self, data, ratio): 24 ''' 按ratio的比例分成训练集和测试集 ''' 25 for line in data.itertuples(): 26 user, movie, rating = line[1], line[2], line[3] 27 if np.random.random() < ratio: 28 self.train_set.setdefault(user, {}) 29 self.train_set[user][movie] = int(rating) 30 else: 31 self.test_set.setdefault(user, {}) 32 self.test_set[user][movie] = int(rating) 33 print('数据预处理完成') 34 35 def item_similarity(self): 36 ''' 计算物品相似度 ''' 37 for user, items in self.train_set.items(): 38 for movie in items.keys(): 39 if movie not in self.movie_popularity: # 用于后面计算新颖度 40 self.movie_popularity[movie] = 0 41 self.movie_popularity[movie] += 1 42 self.tot_movie = len(self.movie_popularity) # 用于计算覆盖率 43 44 C, N = {}, {} # C记录电影两两之间共同喜欢的人数, N记录电影的打分人数 45 for user, items in self.train_set.items(): 46 for m1 in items.keys(): 47 N.setdefault(m1, 0) 48 N[m1] += 1 49 C.setdefault(m1, defaultdict(int)) 50 for m2 in items.keys(): 51 if m1 == m2: 52 continue 53 else: 54 C[m1][m2] += 1 55 56 count = 1 57 for u, related_movies in C.items(): 58 print(' 相似度计算进度:{:.2f}%'.format(count * 100 / self.tot_movie), end='') 59 count += 1 60 self.W.setdefault(u, {}) 61 for v, cuv in related_movies.items(): 62 self.W[u][v] = float(cuv) / math.sqrt(N[u] * N[v]) 63 print(' 相似度计算完成') 64 65 def recommend(self, u): 66 ''' 推荐M部电影 ''' 67 rank = {} 68 user_movies = self.train_set[u] 69 70 for movie, rating in user_movies.items(): 71 for related_movie, similarity in sorted(self.W[movie].items(), key=itemgetter(1), reverse=True)[0:self.K]: 72 if related_movie in user_movies: 73 continue 74 else: 75 rank.setdefault(related_movie, 0) 76 rank[related_movie] += similarity * rating 77 return sorted(rank.items(), key=itemgetter(1), reverse=True)[0:self.M] 78 79 def evaluate(self): 80 ''' 评测算法 ''' 81 hit = 0 82 ret = 0 83 rec_tot = 0 84 pre_tot = 0 85 tot_rec_movies = set() # 推荐电影 86 for user in self.train_set: 87 test_movies = self.test_set.get(user, {}) 88 rec_movies = self.recommend(user) 89 for movie, pui in rec_movies: 90 if movie in test_movies.keys(): 91 hit += 1 92 tot_rec_movies.add(movie) 93 ret += math.log(1+self.movie_popularity[movie]) 94 pre_tot += self.M 95 rec_tot += len(test_movies) 96 precision = hit / (1.0 * pre_tot) 97 recall = hit / (1.0 * rec_tot) 98 coverage = len(tot_rec_movies) / (1.0 * self.tot_movie) 99 ret /= 1.0 * pre_tot 100 print('precision=%.4f' % precision) 101 print('recall=%.4f' % recall) 102 print('coverage=%.4f' % coverage) 103 print('popularity=%.4f' % ret) 104 105 106 if __name__ == '__main__': 107 data = pd.read_csv('u.data', sep=' ', names=['user_id', 'item_id', 'rating', 'timestamp']) 108 itemcf = ItemCF() 109 itemcf.split_data(data, 0.7) 110 itemcf.item_similarity() 111 itemcf.evaluate()
结果
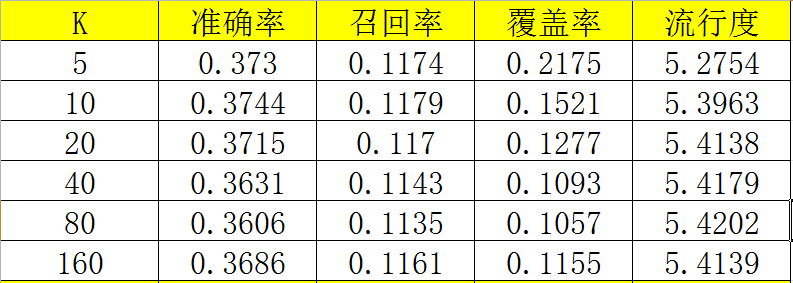
物品相似度的归一化
如果将ItemCF的相似度矩阵按最大值归一化,可以提高性能。
将上述相似度计算的部分代码改为
1 count = 1 2 for u, related_movies in C.items(): 3 print(' 相似度计算进度:{:.2f}%'.format(count * 100 / self.tot_movie), end='') 4 count += 1 5 self.W.setdefault(u, {}) 6 mx = 0.0 7 for v, cuv in related_movies.items(): 8 self.W[u][v] = float(cuv) / math.sqrt(N[u] * N[v]) 9 if self.W[u][v] > mx: 10 mx = self.W[u][v] 11 for v, cuv in related_movies.items(): 12 self.W[u][v] /= mx 13 print(' 相似度计算完成')
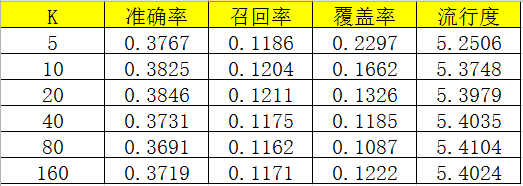
可以看到性能均有所提升。