一、今日学习内容
清洗和组织数据
至此,获得了一段目标的 HTML 代码,但还没有把数据提取出来,接下来在 PyCharm 中输入以下代码:
- for item in data:
- result={
- 'title':item.get_text(),
- 'link':item.get('href')
- }
- print(result)
代码运行结果如图 20 所示:
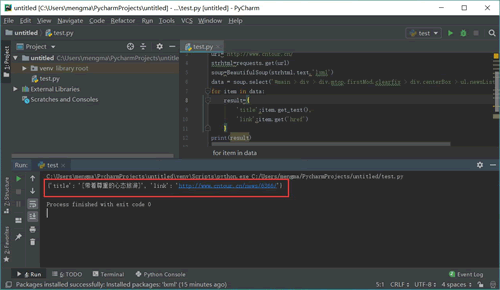
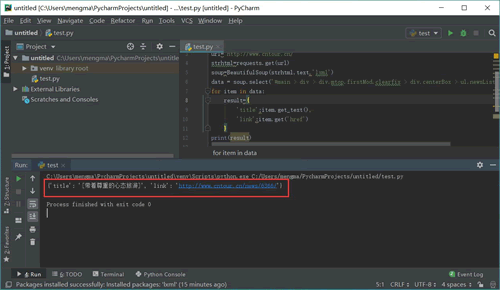
首先明确要提取的数据是标题和链接,标题在<a>标签中,提取标签的正文用 get_text() 方法。链接在<a>标签的 href 属性中,提取标签中的 href 属性用 get() 方法,在括号中指定要提取的属性数据,即 get('href')。
从图 20 中可以发现,文章的链接中有一个数字 ID。下面用正则表达式提取这个 ID。需要使用的正则符号如下:
d匹配数字
+匹配前一个字符1次或多次
在 Python 中调用正则表达式时使用 re 库,这个库不用安装,可以直接调用。在 PyCharm 中输入以下代码:
- import re
- for item in data:
- result={
- "title":item.get_text(),
- "link":item.get('href'),
- 'ID':re.findall('d+',item.get('href'))
- }
- print(result)
运行结果如图 21 所示:

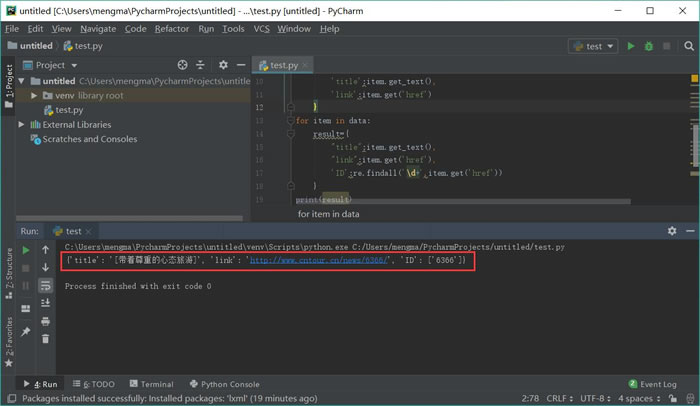
图 21
这里使用 re 库的 findall 方法,第一个参数表示正则表达式,第二个参数表示要提取的文本。
二、遇到的问题
暂无
三、明日计划
继续python学习