这一节主要来介绍TesorFlow的可视化工具TensorBoard,以及TensorFlow基础类型定义、函数操作,后面又介绍到了共享变量和图操作。
一 TesnorBoard可视化操作
TensorFlow提供了可视化操作工具TensorBoard。他可以将训练过程中的各种数据展示出来,包括标量,图片,音频,计算图,数据分布,直方图和嵌入式向量。可以通过网页来观察模型的结构和训练过程中各个参数的变化。TensorBoard不会自动把代码代码出来,其实它是一个日志展示系统,需要在session中运算图时,将各种类型的数据汇总并输出到日志日志文件中。然后启动TensorBoard服务,读取这些日志文件,启动6006端口提供web服务,让用户可以在浏览器查看数据。
TsensorFlow提供了一下我们常用的API,如下所示:
- tf.summary.scalar(tags,values,collections=None,name=None):标量数据汇总,输出protobuf。
- tf.summary.histogram(tag,values,collections=None,name=None):记录变量var的直方图,输出带有直方图的汇总的protobuf。
- tf.summary.image(tag,tensor,max_images=3,collections=None,name=None):图像数据汇总,输出protobuf。
- tf.summary.merge_all(inputs,collections=None,name=None):合并所有的汇总日志。
- tf.summary.FileWriter:创建一个SummaryWriter
- Class SummaryWriter: add_summary(),add_sessionlog(),add_event(),add_graph():将protobuf写入文件的类。
下面我们通过实例来演示TensorFlow的使用,我们仍然使用线性回归的模型:
# -*- coding: utf-8 -*- """ Created on Wed Apr 18 14:06:16 2018 @author: zy """ ''' 1 TensorBoard可视化 ''' import tensorflow as tf import numpy as np import os import matplotlib.pyplot as plt ''' 一准备数据 ''' #设定训练集数据长度 n_train = 100 #生成x数据,[-1,1]之间,均分成n_train个数据 train_x = np.linspace(-1,1,n_train).reshape(n_train,1) #把x乘以2,在加入(0,0.3)的高斯正太分布 train_y = 2*train_x + np.random.normal(loc=0.0,scale=0.3,size=[n_train,1]) #绘制x,y波形 plt.figure() plt.plot(train_x,train_y,'ro',label='y=2x') #o使用圆点标记一个点 plt.legend() plt.show() ''' 二 搭建模型 ''' ''' 前向反馈 ''' #创建占位符 input_x = tf.placeholder(dtype=tf.float32) input_y = tf.placeholder(dtype=tf.float32) #模型参数 w = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='w') #设置正太分布参数 初始化权重 b = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='b') #设置正太分布参数 初始化偏置 #前向结构 pred = tf.multiply(w,input_x) + b #将预测值以直方图形式显示,给直方图命名为'pred' tf.summary.histogram('pred',pred) ''' 反向传播bp ''' #定义代价函数 选取二次代价函数 cost = tf.reduce_mean(tf.square(input_y - pred)) #将损失以标量形式显示 该变量命名为loss_function tf.summary.scalar('loss_function',cost) #设置求解器 采用梯度下降法 学习了设置为0.001 train = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost) ''' 三 迭代模型 ''' #设置迭代次数 training_epochs = 200 display_step = 20 savedir = './LinearRegression' with tf.Session() as sess: #初始化所有张量 sess.run(tf.global_variables_initializer()) #合并所有的summary merged_summary_op = tf.summary.merge_all() #创建summary_write,用于写文件 summary_writer = tf.summary.FileWriter(os.path.join(savedir,'summary_log'),sess.graph) #存放批次值和代价值 plotdata = {'batch_size':[],'loss':[]} #开始迭代 for epoch in range(training_epochs): for (x,y) in zip(train_x,train_y): #开始执行图 sess.run(train,feed_dict={input_x:x,input_y:y}) #生成summary summary_str = sess.run(merged_summary_op,feed_dict={input_x:x,input_y:y}) #将summary写入文件 summary_writer.add_summary(summary_str,epoch) #输出最终结果 print('Finished!') print('cost {0} w {1} b {2}'.format(sess.run(cost,feed_dict={input_x:train_x,input_y:train_y}),sess.run(w),sess.run(b))) #预测 test_x = [2,4,5,7] test_y = sess.run(pred,feed_dict={input_x:test_x}) print('prediction ',test_y) ''' 四 可视化显示 ''' #绘制原数据点,和估计曲线 plt.figure(figsize=(4.2*2,3.2*1)) plt.plot(train_x,train_y,'ro',label='Original data') plt.plot(train_x,sess.run(w)*train_x + sess.run(b),label ='Estimate data') plt.legend() plt.show()
程序运行后会自动创建文件夹summary_log,并生成如下文件:

我们启动Anaconda Prompt,首先来到summary日志的上级路径下,这一步是必须的,然后输入如下命令:
tensorboard --logdir F:pythonLinearRegressionsummary_log

接着打开浏览器,输入http://127.0.0.1:6006,这里127.0.0.1是本机地址,6006是端口号。打开后,单击SCALARS,我们会看到我们在程序中创建的变量loss_function,点击它,会显示如下内容:

在左侧有个smoothing滚动条,可以用来改变右侧标量的曲线,我们还可以勾选上show data download links,然后下载数据。我们点开GRAPHS看一下内部图结构:

在程序程序中,我们把预测值以直方图显示,这里我们可以再HISTOGRAMS中看到:

二 基础类型定义
1.张量介绍
TensorFlow程序使用tensor数据结构来代表所有的数据,计算图中,操作间传递的数据都是tensor,你可以把TensorFlow tensor看做一个n维的数组或者列表。一个tensor包含一个静态类型,rank,和一个shape。具体参见Rank, Shape, 和 Type。
阶(rank)
在TensorFlow系统中,张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述.比如,下面的张量(使用Python中list定义的)就是2阶(因为它有两层中括号).然而作为矩阵,我们认为是3阶的。
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量.对于一个二阶张量你可以用语句t[i, j]来访问其中的任何元素.而对于三阶张量你可以用't[i, j, k]'来访问其中的任何元素.
下面列出标量向量,矩阵的阶数:
| 阶 | 数学实例 | Python 例子 |
|---|---|---|
| 0 | 标量 (只有大小) | s = 4 |
| 1 | 向量(大小和方向) | v = [1.1, 2.2, 3.3] |
| 2 | 矩阵(数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
| n | n阶 | ....n层中括号 |
数据类型
除了维度,Tensors有一个数据类型属性.你可以为一个张量指定下列数据类型中的任意一个类型:
|
tensor数据类型 |
Python 类型 |
描述 |
|---|---|---|
DT_FLOAT |
tf.float32 |
32 位浮点数. |
DT_DOUBLE |
tf.float64 |
64 位浮点数. |
DT_INT64 |
tf.int64 |
64 位有符号整型. |
DT_INT32 |
tf.int32 |
32 位有符号整型. |
DT_INT16 |
tf.int16 |
16 位有符号整型. |
DT_INT8 |
tf.int8 |
8 位有符号整型. |
DT_UINT8 |
tf.uint8 |
8 位无符号整型. |
DT_STRING |
tf.string |
可变长度的字节数组.每一个张量元素都是一个字节数组. |
DT_BOOL |
tf.bool |
布尔型. |
DT_COMPLEX64 |
tf.complex64 |
由两个32位浮点数组成的复数:实数和虚数. |
DT_QINT32 |
tf.qint32 |
用于量化Ops的32位有符号整型. |
DT_QINT8 |
tf.qint8 |
用于量化Ops的8位有符号整型. |
DT_QUINT8 |
tf.quint8 |
用于量化Ops的8位无符号整型. |
形状
TensorFlow文档中使用了三种记号来方便地描述张量的维度:阶,形状以及维数.下表展示了他们之间的关系:
| 阶 | 形状 | 维数 | 实例 |
|---|---|---|---|
| 0 | [ ] | 0-D | 一个 0维张量. 一个纯量. |
| 1 | [D0] | 1-D | 一个1维张量的形式[5]. |
| 2 | [D0, D1] | 2-D | 一个2维张量的形式[3, 4]. |
| 3 | [D0, D1, D2] | 3-D | 一个3维张量的形式 [1, 4, 3]. |
| n | [D0, D1, ... Dn] | n-D | 一个n维张量的形式 [D0, D1, ... Dn]. |
形状可以通过Python中的整数列表或元祖(int list或tuples)来表示,也或者用TensorShape class.
2.张量相关操作
张量的相关操作包括类型转换,数字操作,形状变换和数据操作。
类型转换的函数主要包括:详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-85v22c69.html
- tf.string_to_number
- tf.to_double
- tf.to_float
- tf.to_bfloat16
- tf.to_int32
- tf.to_int64
- tf.cast
- tf.bitcast
- tf.saturate_cast
形状变换
TensorFlow 提供了几种操作,可用于确定张量的形状并更改张量的形状。形状函数主要包括:详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-85v22c69.html
- tf.broadcast_dynamic_shape
- tf.broadcast_static_shape
- tf.shape
- tf.shape_n
- tf.size
- tf.rank
- tf.reshape
- tf.squeeze
- tf.expand_dims
- tf.meshgrid
张量的分割和连接
TensorFlow 提供了几个操作来分割或提取张量的部分,或者将多个张量连接在一起。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-85v22c69.html
- tf.slice
- tf.strided_slice
- tf.split
- tf.tile
- tf.pad
- tf.concat
- tf.stack
- tf.parallel_stack
- tf.unstack
- tf.reverse_sequence
- tf.reverse
- tf.reverse_v2
- tf.transpose
- tf.extract_image_patches
- tf.space_to_batch_nd
- tf.space_to_batch
- tf.required_space_to_batch_paddings
- tf.batch_to_space_nd
- tf.batch_to_space
- tf.space_to_depth
- tf.depth_to_space
- tf.gather
- tf.gather_nd
- tf.unique_with_counts
- tf.scatter_nd
- tf.dynamic_partition
- tf.dynamic_stitch
- tf.boolean_mask
- tf.one_hot
- tf.sequence_mask
- tf.dequantize
- tf.quantize_v2
- tf.quantized_concat
- tf.setdiff1d
假量化
用于帮助训练提高量化准确度的操作。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-85v22c69.html
- tf.fake_quant_with_min_max_args
- tf.fake_quant_with_min_max_args_gradient
- tf.fake_quant_with_min_max_vars
- tf.fake_quant_with_min_max_vars_gradient
- tf.fake_quant_with_min_max_vars_per_channel
- tf.fake_quant_with_min_max_vars_per_channel_gradient
常数值传感器
TensorFlow 提供了几种可用于生成常量的操作。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-efts28tw.html
序列
详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-efts28tw.html
随机张量
TensorFlow 有几个 ops 用来创建不同分布的随机张量。随机操作是有状态的,并在每次评估时创建新的随机值。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-efts28tw.html
seed 这些函数中的关键字参数与图级随机种子一起作用。使用 tf.set_random_seed 或使用 op 级别的种子更改图形级别的种子将会更改这些操作的底层种子。设置图形级别或操作级种子,都会为所有操作生成随机种子。有关 tf.set_random_seed 操作级和图级随机种子之间的交互的详细信息,请参阅。
- tf.random_normal
- tf.truncated_normal
- tf.random_uniform
- tf.random_shuffle
- tf.random_crop
- tf.multinomial
- tf.random_gamma
- tf.set_random_seed
3.算数运算函数
算术运算符
TensorFlow 提供了几种操作,您可以使用它们将基本算术运算符添加到图形中。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
- tf.add
- tf.subtract
- tf.multiply
- tf.scalar_mul
- tf.div
- tf.divide
- tf.truediv
- tf.floordiv
- tf.realdiv
- tf.truncatediv
- tf.floor_div
- tf.truncatemod
- tf.floormod
- tf.mod
- tf.cross
基本数学函数
TensorFlow 提供了几种可用于向图形添加基本数学函数的操作。
详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
- tf.add_n
- tf.abs
- tf.negative
- tf.sign
- tf.reciprocal
- tf.square
- tf.round
- tf.sqrt
- tf.rsqrt
- tf.pow
- tf.exp
- tf.expm1
- tf.log
- tf.log1p
- tf.ceil
- tf.floor
- tf.maximum
- tf.minimum
- tf.cos
- tf.cosh
- tf.sin
- tf.lbeta
- tf.tan
- tf.acos
- tf.asin
- tf.atan
- tf.lgamma
- tf.digamma
- tf.erf
- tf.erfc
- tf.squared_difference
- tf.igamma
- tf.igammac
- tf.zeta
- tf.polygamma
- tf.betainc
- tf.rint
矩阵数学函数
TensorFlow 提供了几种操作,您可以使用它们将曲线上的线性代数函数添加到图形中。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
- tf.diag
- tf.diag_part
- tf.trace
- tf.transpose
- tf.eye
- tf.matrix_diag
- tf.matrix_diag_part
- tf.matrix_band_part
- tf.matrix_set_diag
- tf.matrix_transpose
- tf.matmul
- tf.norm
- tf.matrix_determinant
- tf.matrix_inverse
- tf.cholesky
- tf.cholesky_solve
- tf.matrix_solve
- tf.matrix_triangular_solve
- tf.matrix_solve_ls
- tf.qr
- tf.self_adjoint_eig
- tf.self_adjoint_eigvals
- tf.svd
张量数学函数
TensorFlow 提供可用于向图形添加张量函数的操作。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
复数函数
TensorFlow 提供了多种操作,您可以使用它们将复数函数添加到图形中。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
规约计算
TensorFlow 提供了几种操作,您可以使用这些操作来执行减少张量的各种维度的常规数学计算。在所有reduce_xxx系列操作函数中,都是以xxx的手段降维,每个函数都有axis这个参数,即沿某个方向,使xxx方法对输入的Tensor进行降维。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
- tf.reduce_sum
- tf.reduce_prod
- tf.reduce_min
- tf.reduce_max
- tf.reduce_mean
- tf.reduce_all
- tf.reduce_any
- tf.reduce_logsumexp
- tf.count_nonzero
- tf.accumulate_n
- tf.einsum
张量扫描
TensorFlow 提供了几种操作,您可以使用它们在张量的一个轴上执行扫描(运行总计)。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
分段
TensorFlow 提供了几种可用于在张量片段上执行常规数学计算的操作。这里,分割是沿着第一维度的张量的分割,即它定义从第一维度到的映射 segment_ids。segment_ids 张量应该是第一尺寸的大小,d0与在范围内的连续的ID 0到k,在那里 k<d0。特别地,矩阵张量的分割是行到段的映射。详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
- tf.segment_sum
- tf.segment_prod
- tf.segment_min
- tf.segment_max
- tf.segment_mean
- tf.unsorted_segment_sum
- tf.sparse_segment_sum
- tf.sparse_segment_mean
- tf.sparse_segment_sqrt_n
序列比较和索引提取
TensorFlow 提供了几种操作,您可以使用它们将序列比较和索引提取添加到图形中。您可以使用这些操作来确定序列差异,并确定张量中特定值的索引。
详情:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-u7wa28vm.html
- tf.argmin
- tf.argmax
- tf.setdiff1d
- tf.where
- tf.unique
- tf.edit_distance
- tf.invert_permutation
三 共享变量
共享变量在复杂的网络中涌出非常广泛。
1.共享变量用途
在构建模型时,需要使用tf.Variable来创建一个变量。比如创建一个偏置的学习参数,在训练的时候,这个变量会不断地更新:
biases = tf.Variable(tf.zeros(shape=[2]),name='biases')
但在某些情况下,一个模型需要使用其它模型创建的变量,两个模型在一起训练。比如:对抗网络中的生成器模型与判别器模型。如果使用tf.Variable始终会生成一个新的变量,这个函数在处理同名的时候,一般会在后面追加_n:0,比如之前已经创建了一个,那么我们第二次调用这个函数,创建的变量的name将是'biases_1:0',而我们需要的是原来的那么biases变量,这时候怎么办?
我们可以通过引入get_variable方法,实现共享变量来解决这个问题。
2.get_variable
get_variable函数一般会和variable_scope一起使用,以实现共享变量。variable_scope的意思是变量作用域。在某一作用域的变量可以被设置成共享的方式,被其它网络模型使用。该函数的定义如下:
tf.get_variable( name, shape=None, dtype=None, initializer=None, regularizer=None, trainable=True, collections=None, caching_device=None, partitioner=None, validate_shape=True, use_resource=None, custom_getter=None )
在TensorFlow中,使用get_variable创建的变量是以指定的name属性为唯一标识符,并不是定义的变量名称,重复定义name属性一样的变量会报错,但是可以通过reuse参数指定这不是创建一个新的变量,而是查找之前使用该函数定义过得name一致的变量。使用时一般通过name属性定位到具体变量,并将其共享到其它模型中。
下面我们通过一个案例来直观的解释get_variable和Variable的区别:
''' (1) tf.Variable的使用 ''' var1 = tf.Variable(1.0,name='first_var',dtype=tf.float32) print('var1:',var1.name) var1 = tf.Variable(2.0,name='first_var',dtype=tf.float32) print('var1:',var1.name) var2 = tf.Variable(3.0,dtype=tf.float32) print('var2:',var2.name) var2 = tf.Variable(4.0,dtype=tf.float32) print('var2:',var2.name) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print('var1=',var1.eval()) print('var2=',var2.eval())
运行结果如下:

上面代码中我们定义了两次var1,可以看到在内存中生成了两个var1(因为这两个变量的名字不一样),对于图来讲后面的var1是生效的(var1=2.0)。var2在定义的时候没有指定name属性,系统自动给加上一个名字Variable:0.
''' (2) get_variable的使用 ''' get_var1 = tf.get_variable('first_var',shape=[1],initializer=tf.constant_initializer(0.3)) print('get_var1:',get_var1.name) get_var1 = tf.get_variable('first_var',shape=[1],initializer=tf.constant_initializer(0.4)) print('get_var1:',get_var1.name)
运行结果如下:

可以看到程序定义第2个get_var1时发生崩溃了。这表明,使用get_variable只能定义一次指定名称的变量。同时由于变量first_var在前面使用Variable函数生成过一次,所以系统自动变成了firstvar_2:0。
因此我们需要把代码修改成如下:
''' (2) get_variable的使用 ''' get_var1 = tf.get_variable('first_var',shape=[1],initializer=tf.constant_initializer(0.3)) print('get_var1:',get_var1.name) get_var1 = tf.get_variable('first_var1',shape=[1],initializer=tf.constant_initializer(0.4)) print('get_var1:',get_var1.name) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print('get_var1:',get_var1.eval())

可以看到,这次又是定义了一个get_var1,不同的的是我们在程序中指定了不同的name属性。同样,新的get_var1会在图中生效,所以它的输出值时0.4而不是0.3.
3.variable_scope
在作用域下,使用get_variable以及嵌套使用variable_scope。在上面的例子中,使用get_variable创建两个同样名字(name属性)的变量是错误的。但是我们通过配合使用variable_scope就可以将它们隔开。代码如下:
''' (3) variable_scope使用 ''' #定义一个作用域'test1' with tf.variable_scope('test1'): var1 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test2'): var2 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) print('var1:',var1.name) print('var2:',var2.name)

我们可以看到变量的名字前面都加了作用域作为前缀,因此这段程序生成的两个变量var1和var2是不同的。
作用域scope是支持嵌套的,效果如下:
#定义一个作用域'test1' with tf.variable_scope('test1'): var1 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test2'): var2 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) print('var1:',var1.name) print('var2:',var2.name)

4.共享变量功能的实现
使用作用域中的reuse参数来实现共享变量的功能。废了那么大的劲来讲解get_variable就是为了要通过它实现共享变量的功能。
variable_scope里面有一个reuse=True属性,表示使用已经定义过得变量。这时get_varaible将不会创建新的变量,而是取图中get_variable所创建过得变量中查找与name相同的变量。
''' (4) 共享变量功能的实现 ''' with tf.variable_scope('test1',reuse=True): var3 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test2',reuse=True): var4 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) print('var3:',var3.name) print('var4:',var4.name)

我们可以看到var3和var1的输出name是一样的,var2和var4的输出name也是一样的。这表明他们共用一个变量,这也就实现了共享变量的功能。在实际应用中,可以把var1和var2放到一个网络模型中取训练,把var3和var4放到另一个网络模型中训练,而两个模型的训练结果都会作用于一个模型的学习参数上。
注:tf.get_variable在创建变量时,会去检查图中是否已经创建过该变量,如果创建过并且本次调用没有设置为共享模型,则会报错,因此在spyder中只能运行一次,第二次运行会报错,我们可以通过重启内核清空图。除此之外,我们还可以使用代码tf.rest_default_graph(),将图里面的变量清空,就可以解决报错的问题。
5.初始化共享变量的作用域
variable_scopr和get_varaibel都有初始化的功能。在初始化时,如果没有对当前变量初始化,则TensorFlow会默认使用作用域的初始化方法对其初始化,并且作用域的初始化方法也有继承功能。代码如下:(tf.constant_initializer初始化器用于生成具有常量值的张量,即用来初始化其它张量的初始值。)
''' (5)初始化共享变量的作用域 ''' with tf.variable_scope('test3',initializer=tf.constant_initializer(0.4)): var5 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test4'): var6 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) var7 = tf.get_variable('var7',shape=[2],dtype=tf.float32,initializer=tf.constant_initializer(0.3)) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #作用域test3下的变量 print('var5:',var5.eval()) #作用域test4下面的变量,继承自test3初始化 print('var6:',var6.eval()) #作用域test4下的变量 print('var7:',var7.eval())

我们从输出结果可以看到以下过程:
- 将test3作用域进行初始化为0.4
- var5没有初始化,var5的值为0.4,继承了test3的值。
- 嵌套的test4作用域也没有初始化
- test4下的var6也没有初始化,var6的值为0.4,也继承了test3的初始化。
- test4下的var7进行了初始化,值为0.3.
6.作用域和操作符的受限范围
variable_scope还可以以with variable_scope('name') as xxscope的方式定义作用域,当使用这种方式,所定义的作用域变量xxscope将不再受到外围的scope的限制。
如下代码:
''' (6)作用域和操作符的受限范围 ''' with tf.variable_scope('scope1') as sp: var1 = tf.get_variable('v',shape=[1]) print('sp',sp.name) print('var1:',var1.name) with tf.variable_scope('scope2'): var2 = tf.get_variable('v',shape=[1]) with tf.variable_scope(sp) as sp1: var3 = tf.get_variable('v3',shape=[1]) print('sp1:',sp1.name) print('var2:',var2.name) print('var3:',var3.name)
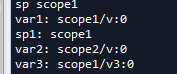
我们这里主要关注var3的输出,var3.name输出是scope1/v3:0,sp1在scope2下,但是输出的仍然是scope1,这表明了sp1没有受到外层(scope2)的限制。这主要是因为我们在定义scope1和scope2时,它们之间是并列关系。
7.name_scope
这里有必要介绍另一个操作符的作用域tf.name_scope,这个作用域和variable_scope有个区别,即Variable定义的变量在这两个作用域下都需要加上作用域作为前缀。而get_variable在name_scope作用域下并不会加上前缀,这表明name_scope作用域对get_variable生成的变量没有任何约束作用,只对Variable生成的变量起作用。
''' (7) name_scope ''' with tf.variable_scope('scope'): with tf.name_scope('bar'): t=tf.get_variable('t',shape=[1]) x= 1.0 + t y = tf.Variable('y') print('t:',t.name) print('x:',x.name) print('x.op:',x.op.name) print('y:',y.name)
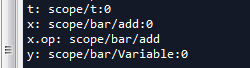
从上面我们也可以看到,t变量只受限于variable_scope作用域。而name_scope并不能限制get_variable生成的变量,但是可以限制op以及Variable变量。注意这里有必要说一下什么是op:我们可以把其看做是模型中的中间节点,是通过源节点(即tf常量或者变量)计算得到的,是网络中的结构。
在name_scope函数中,可以使用空字符串将作用域返回到顶层。
with tf.name_scope(''):
然而variable_scope却是把其作空字符串处理。
with tf.variable_scope(''):
四 图操作
前面我们大概知道图是什么?图就是一个计算任务,之前我们写的程序,都是在默认图中工作的,除了系统自动构建图以外,我们还可以手动构建,并做一些其它的操作,这里我们更加详细的阐述什么是图。
TensorFlow中与图相关的函数主要有以下这些:
核心图数据结构
张量类型
实用功能
- tf.device
- tf.container
- tf.name_scope
- tf.control_dependencies
- tf.convert_to_tensor
- tf.convert_to_tensor_or_indexed_slices
- tf.convert_to_tensor_or_sparse_tensor
- tf.get_default_graph
- tf.reset_default_graph
- tf.import_graph_def
- tf.load_file_system_library
- tf.load_op_library
图形集合
定义新操作
- tf.RegisterGradient
- tf.NotDifferentiable
- tf.NoGradient
- tf.TensorShape
- tf.Dimension
- tf.op_scope
- tf.get_seed
对于建立在TensorFlow上的库
1.构建图
可以在一个TensorFlow中手动构建其它的图,也可以根据图中的变量获得当前的图。下面程序展示了tf.Graph构建图,使用tf.get_default_graph获得图,以及使用reset_default_graph重置图的过程。
''' (1) 构建图 ''' c = tf.constant(0.0,dtype=tf.float32) g = tf.Graph() with g.as_default(): c1 = tf.constant(0.0,dtype=tf.float32) print(c1.graph) print(g) print(c.graph) g2 = tf.get_default_graph() print(g2) tf.reset_default_graph() g3 = tf.get_default_graph() print(g3)

- c是在刚开始的默认图中生成的变量,所以图的打印值就是原始默认图的打印值。
- 然后使用tf.Graph()构建一个图g,并且在新建的图中添加变量c1,所以c1.graph和g的打印值是一样的。
- 在新图的作用域外,使用tf.get_default_graph()获取默认图,所以输出值和c.graph一样。
- 最后使用tf.reset_default_graph()函数重置图,相当于重新构建一个图来替代默认的图。
注意:使用tf.reset_default_graph()函数必须要保证当前图的资源已经全部释放,否则会报错。
2.获取张量
在图里面可以通过名字得到相应的元素,例如get_tensor_by_name可以获得图里面的张量。
''' (2)获得张量 ''' g = tf.Graph() with g.as_default(): c1 = tf.constant(2.0,dtype=tf.float32,shape=[2]) print(t.name) t = g.get_tensor_by_name(name = 'Const:0') print(g.get_tensor_by_name(name = t.name)) print(t)
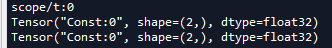
上面程序将c1的名字放在get_tensor_by_name()里反向得到其张量,通过对t的打印我们可以看到t就是前面定义的张量c1.
注意:对于张量的命名,我们不需要去研究,一般使用的时候我们会指定固定的名字,如果真不清楚某个张量的名称,我们可以先打印出来,然后再使用。
3.获取节点操作
获取节点操作op的方法和获取张量的方法类似,使用的方法是get_operation_by_name()
''' (3)获取节点的操作 ''' tf.reset_default_graph() g4 = tf.get_default_graph() print(g4) a = tf.constant([1.0,2.0]) b = tf.constant([3.0,4.0]) #test和tensor1指向同一个张量 tensor1 = tf.multiply(a,b,name='product') print(tensor1.name,tensor1) test = g4.get_tensor_by_name('product:0') print(test) #获取节点操作 print(tensor1.op.name) testop = g4.get_operation_by_name('product') print(testop) with tf.Session() as sess: #执行图 得到矩阵乘积 test = sess.run(test) print(test) #Z再次获得张量 test = tf.get_default_graph().get_tensor_by_name('product:0') print(test)
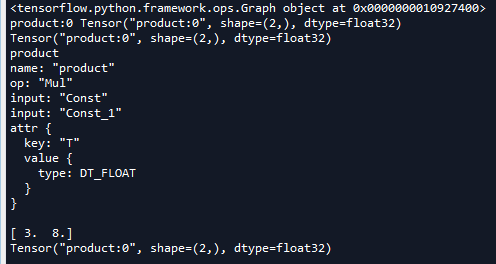
我们首先把图g4打印出来,然后将张量tesnor以及名字打印出来,然后通过get_sensor_by_name()获得该张量,test和tensor1指向同一个张量。为了证明这一点,直接test在session执行,运行后也能得到正确的结果。
程序中,我们通过print(tensor1.op.name)打印出节点操作的name,然后通过get_operation_by_name()获取相同的op,可以看出op与tensor1之间的关系。
注意:op和张量在定义节点时很容易混淆,上例中tensor1 = tf.multiply(a,b,name='product')并不是op,而是张量。op其实是描述张量中的运算关系,是通过访问张量的属性找到的。
4.获取元素列表
通过get_operations()函数获取图中的所有元素。
''' (4)获取元素列表 ''' t2 = g4.get_operations() print(t2)

5.获取对象
前面是根据名字来获取元素,还可以根据对象来获取元素,使用tf.Graph().as_graph_elment(obj,allow_tensor=True,allow_operation=True)函数,即传入一个对象,返回一个张量或是一个op。该函数具有验证和转换功能,再多线程方面偶尔会用到。
''' (5)获取对象 ''' t3= g4.as_graph_element(a) print(t3)

通过print(t3)可以看到,函数as_graph_element()获取了a张量,然后赋值给了变量t3。
这里我们再看一个特殊的例子:
print(' g4:',g4) with g4.as_default(): print(tf.get_default_graph)

我们可以看到就算我们在新建图的作用域输出默认图,其实打印的还是全局的默认图,并不是我们新建的图。
全部代码:


# -*- coding: utf-8 -*- """ Created on Wed Apr 18 14:06:16 2018 @author: zy """ ''' TensorBoard可视化显示以及共享变量 ''' ''' 1 TensorBoard可视化 ''' import tensorflow as tf import numpy as np import os import matplotlib.pyplot as plt ''' 一准备数据 ''' #设定训练集数据长度 n_train = 100 #生成x数据,[-1,1]之间,均分成n_train个数据 train_x = np.linspace(-1,1,n_train).reshape(n_train,1) #把x乘以2,在加入(0,0.3)的高斯正太分布 train_y = 2*train_x + np.random.normal(loc=0.0,scale=0.3,size=[n_train,1]) #绘制x,y波形 plt.figure() plt.plot(train_x,train_y,'ro',label='y=2x') #o使用圆点标记一个点 plt.legend() plt.show() ''' 二 搭建模型 ''' ''' 前向反馈 ''' #创建占位符 input_x = tf.placeholder(dtype=tf.float32) input_y = tf.placeholder(dtype=tf.float32) #模型参数 w = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='w') #设置正太分布参数 初始化权重 b = tf.Variable(tf.truncated_normal(shape=[1],mean=0.0,stddev=1),name='b') #设置正太分布参数 初始化偏置 #前向结构 pred = tf.multiply(w,input_x) + b #将预测值以直方图形式显示,给直方图命名为'pred' tf.summary.histogram('pred',pred) ''' 反向传播bp ''' #定义代价函数 选取二次代价函数 cost = tf.reduce_mean(tf.square(input_y - pred)) #将损失以标量形式显示 该变量命名为loss_function tf.summary.scalar('loss_function',cost) #设置求解器 采用梯度下降法 学习了设置为0.001 train = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost) ''' 三 迭代模型 ''' #设置迭代次数 training_epochs = 200 display_step = 20 savedir = './LinearRegression' with tf.Session() as sess: #初始化所有张量 sess.run(tf.global_variables_initializer()) #合并所有的summary merged_summary_op = tf.summary.merge_all() #创建summary_write,用于写文件 summary_writer = tf.summary.FileWriter(os.path.join(savedir,'summary_log'),sess.graph) #存放批次值和代价值 plotdata = {'batch_size':[],'loss':[]} #开始迭代 for epoch in range(training_epochs): for (x,y) in zip(train_x,train_y): #开始执行图 sess.run(train,feed_dict={input_x:x,input_y:y}) #生成summary summary_str = sess.run(merged_summary_op,feed_dict={input_x:x,input_y:y}) #将summary写入文件 summary_writer.add_summary(summary_str,epoch) #输出最终结果 print('Finished!') print('cost {0} w {1} b {2}'.format(sess.run(cost,feed_dict={input_x:train_x,input_y:train_y}),sess.run(w),sess.run(b))) #预测 test_x = [2,4,5,7] test_y = sess.run(pred,feed_dict={input_x:test_x}) print('prediction ',test_y) ''' 四 可视化显示 ''' #绘制原数据点,和估计曲线 plt.figure(figsize=(4.2*2,3.2*1)) plt.plot(train_x,train_y,'ro',label='Original data') plt.plot(train_x,sess.run(w)*train_x + sess.run(b),label ='Estimate data') plt.legend() plt.show() ''' 2. 共享变量 ''' biases = tf.Variable(tf.zeros(shape=[2]),name='biases') tf.reset_default_graph() ''' (1) tf.Variable的使用 ''' var1 = tf.Variable(1.0,name='first_var',dtype=tf.float32) print('var1:',var1.name) var1 = tf.Variable(2.0,name='first_var',dtype=tf.float32) print('var1:',var1.name) var2 = tf.Variable(3.0,dtype=tf.float32) print('var2:',var2.name) var2 = tf.Variable(4.0,dtype=tf.float32) print('var2:',var2.name) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print('var1=',var1.eval()) print('var2=',var2.eval()) ''' (2) get_variable的使用 ''' get_var1 = tf.get_variable('first_var',shape=[1],initializer=tf.constant_initializer(0.3)) print('get_var1:',get_var1.name) get_var1 = tf.get_variable('first_var1',shape=[1],initializer=tf.constant_initializer(0.4)) print('get_var1:',get_var1.name) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) print('get_var1:',get_var1.eval()) ''' (3) variable_scope使用 ''' #定义一个作用域'test1' with tf.variable_scope('test1'): var1 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test2'): var2 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) print('var1:',var1.name) print('var2:',var2.name) ''' (4) 共享变量功能的实现 ''' with tf.variable_scope('test1',reuse=True): var3 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test2',reuse=True): var4 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) print('var3:',var3.name) print('var4:',var4.name) ''' (5)初始化共享变量的作用域 ''' with tf.variable_scope('test3',initializer=tf.constant_initializer(0.4)): var5 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) with tf.variable_scope('test4'): var6 = tf.get_variable('testvar',shape=[2],dtype=tf.float32) var7 = tf.get_variable('var7',shape=[2],dtype=tf.float32,initializer=tf.constant_initializer(0.3)) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #作用域test3下的变量 print('var5:',var5.eval()) #作用域test4下面的变量,继承自test3初始化 print('var6:',var6.eval()) #作用域test4下的变量 print('var7:',var7.eval()) ''' (6)作用域和操作符的受限范围 ''' with tf.variable_scope('scope1') as sp: var1 = tf.get_variable('v',shape=[1]) print('sp',sp.name) print('var1:',var1.name) with tf.variable_scope('scope2'): var2 = tf.get_variable('v',shape=[1]) with tf.variable_scope(sp) as sp1: var3 = tf.get_variable('v3',shape=[1]) print('sp1:',sp1.name) print('var2:',var2.name) print('var3:',var3.name) ''' (7) name_scope ''' with tf.variable_scope('scope'): with tf.name_scope('bar'): t=tf.get_variable('t',shape=[1]) x= 1.0 + t y = tf.Variable('y') print('t:',t.name) print('x:',x.name) print('x.op:',x.op.name) print('y:',y.name) ''' 3 图操作 ''' ''' (1)构建图 ''' c = tf.constant(0.0,dtype=tf.float32) g = tf.Graph() with g.as_default(): c1 = tf.constant(0.0,dtype=tf.float32) print(c1.graph) print(g) print(c.graph) g2 = tf.get_default_graph() print(g2) tf.reset_default_graph() g3 = tf.get_default_graph() print(g3) ''' (2)获得张量 ''' g = tf.Graph() with g.as_default(): c1 = tf.constant(2.0,dtype=tf.float32,shape=[2]) print(t.name) t = g.get_tensor_by_name(name = 'Const:0') print(g.get_tensor_by_name(name = t.name)) print(t) ''' (3)获取节点的操作 ''' tf.reset_default_graph() g4 = tf.get_default_graph() print(g4) a = tf.constant([1.0,2.0]) b = tf.constant([3.0,4.0]) #test和tensor1指向同一个张量 tensor1 = tf.multiply(a,b,name='product') print(tensor1.name,tensor1) test = g4.get_tensor_by_name('product:0') print(test) #获取节点操作 print(tensor1.op.name) testop = g4.get_operation_by_name('product') print(testop) with tf.Session() as sess: #执行图 得到矩阵乘积 test = sess.run(test) print(test) #Z再次获得张量 test = tf.get_default_graph().get_tensor_by_name('product:0') print(test) ''' (4)获取元素列表 ''' t2 = g4.get_operations() print(t2) ''' (5)获取对象 ''' t3= g4.as_graph_element(a) print(t3) print(' g4:',g4) with g4.as_default(): print(tf.get_default_graph)