1>下载HTMLTestRunner.py文件,地址为:
Windows平台:
将下载的文件放入...Python27Lib 目录下
Linux平台:
下需要先确定 python 的安装目录,打开终端,输入 python 命令进入 python 交互模式,通过 sys.path 可以查看本机 python 文件目录,以管理员身份将 HTMLTestRunner.py 文件考本到/usr/lib/python2.7/dist-packages/ 目录下
2>导入模块:import HTMLTestRunner。在代码最尾部编写代码:
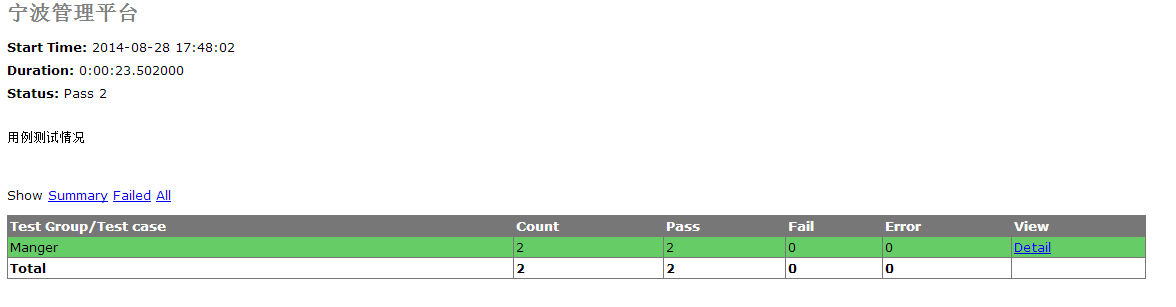
更好用的HTML报告
替换附件中的HTMLTestRunner.py。关于HTML报告中显示出截图的方法在HTMLTestRunner中已经写死,所以必须按写死的路径来设置文件件。文件夹顺序如下:
对HTMLTestRunner中的总结如下:
1、设置HTML报告的存放路径为result
2、设置截图保存的路径为resultimage。
3、data里面的图片用来做图标
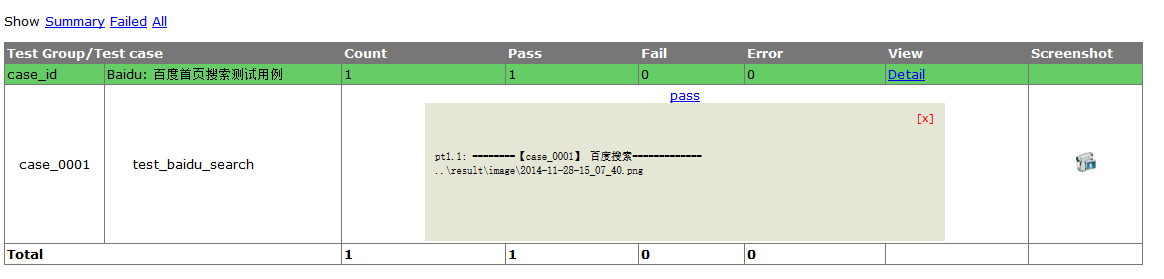
4、在代码里面把截图路径给打印出来,具体效果如下:
# -*- coding: utf-8 -*-from selenium import webdriverimport unittestimport time,sysimport HTMLTestRunnerreload(sys)sys.setdefaultencoding("utf-8")class Baidu(unittest.TestCase):"""百度首页搜索测试用例"""def setUp(self):self.driver = webdriver.Chrome()self.driver.implicitly_wait(30)self.base_url = "http://www.baidu.com"def test_baidu_search(self):driver = self.driverprint u"========【case_0001】 百度搜索============="driver.get(self.base_url + "/")driver.find_element_by_id("kw").clear()driver.find_element_by_id("kw").send_keys(u"林志玲")driver.find_element_by_id("su").click()now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))#必须要打印路径HTMLTestRunner才能捕获并且生成路径,image**.png 是获取路径的条件,必须这样的目录
pic_path='..\result\image\'+now+'.png'print pic_pathdriver.save_screenshot(pic_path)time.sleep(2)def tearDown(self):self.driver.quit()if __name__ == "__main__":now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))testunit = unittest.TestSuite()testunit.addTest(Baidu("test_baidu_search"))HtmlFile = "..\result\"+now+"HTMLtemplate.html"print HtmlFilefp = file(HtmlFile, "wb")runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"百度测试报告", description=u"用例测试情况")runner.run(testunit)
- 引用地址:http://www.cnblogs.com/hero-blog/p/4128575.html